 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPLATART: Articulated Gaussian Splatting with Estimated Object Structure
Jun 13, 2025Representing articulated objects remains a difficult problem within the field of robotics. Objects such as pliers, clamps, or cabinets require representations that capture not only geometry and color information, but also part seperation, connectivity, and joint parametrization. Furthermore, learning these representations becomes even more difficult with each additional degree of freedom. Complex articulated objects such as robot arms may have seven or more degrees of freedom, and the depth of their kinematic tree may be notably greater than the tools, drawers, and cabinets that are the typical subjects of articulated object research. To address these concerns, we introduce SPLATART - a pipeline for learning Gaussian splat representations of articulated objects from posed images, of which a subset contains image space part segmentations. SPLATART disentangles the part separation task from the articulation estimation task, allowing for post-facto determination of joint estimation and representation of articulated objects with deeper kinematic trees than previously exhibited. In this work, we present data on the SPLATART pipeline as applied to the syntheic Paris dataset objects, and qualitative results on a real-world object under spare segmentation supervision. We additionally present on articulated serial chain manipulators to demonstrate usage on deeper kinematic tree structures.
NARF24: Estimating Articulated Object Structure for Implicit Rendering
Sep 15, 2024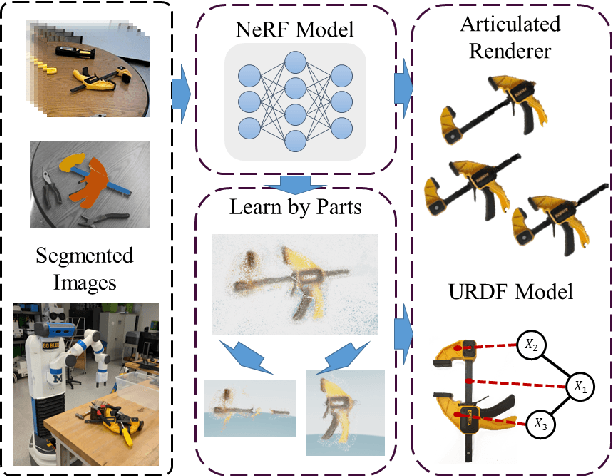



Articulated objects and their representations pose a difficult problem for robots. These objects require not only representations of geometry and texture, but also of the various connections and joint parameters that make up each articulation. We propose a method that learns a common Neural Radiance Field (NeRF) representation across a small number of collected scenes. This representation is combined with a parts-based image segmentation to produce an implicit space part localization, from which the connectivity and joint parameters of the articulated object can be estimated, thus enabling configuration-conditioned rendering.
Single-View 3D Reconstruction via SO(2)-Equivariant Gaussian Sculpting Networks
Sep 11, 2024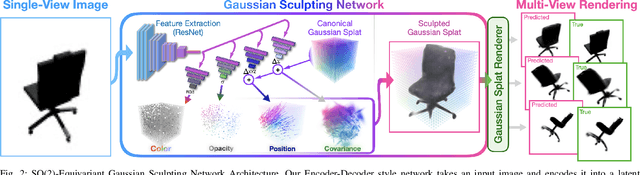
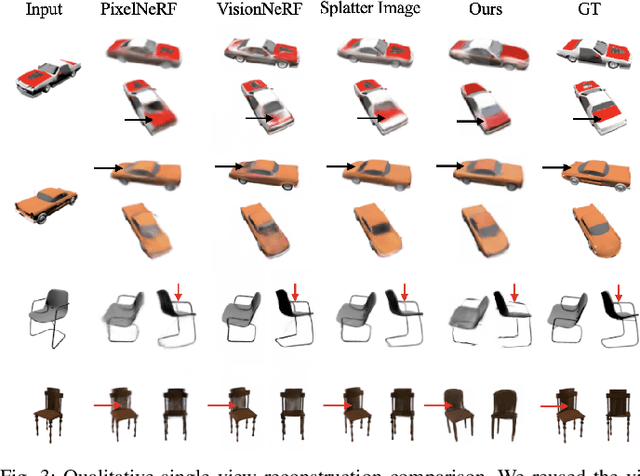

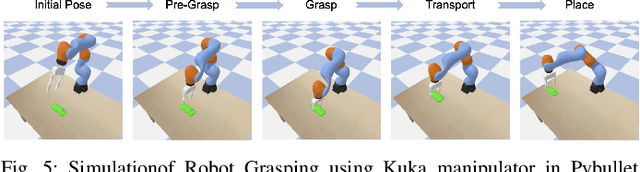
This paper introduces SO(2)-Equivariant Gaussian Sculpting Networks (GSNs) as an approach for SO(2)-Equivariant 3D object reconstruction from single-view image observations. GSNs take a single observation as input to generate a Gaussian splat representation describing the observed object's geometry and texture. By using a shared feature extractor before decoding Gaussian colors, covariances, positions, and opacities, GSNs achieve extremely high throughput (>150FPS). Experiments demonstrate that GSNs can be trained efficiently using a multi-view rendering loss and are competitive, in quality, with expensive diffusion-based reconstruction algorithms. The GSN model is validated on multiple benchmark experiments. Moreover, we demonstrate the potential for GSNs to be used within a robotic manipulation pipeline for object-centric grasping.
OVAL-Prompt: Open-Vocabulary Affordance Localization for Robot Manipulation through LLM Affordance-Grounding
Apr 17, 2024



In order for robots to interact with objects effectively, they must understand the form and function of each object they encounter. Essentially, robots need to understand which actions each object affords, and where those affordances can be acted on. Robots are ultimately expected to operate in unstructured human environments, where the set of objects and affordances is not known to the robot before deployment (i.e. the open-vocabulary setting). In this work, we introduce OVAL-Prompt, a prompt-based approach for open-vocabulary affordance localization in RGB-D images. By leveraging a Vision Language Model (VLM) for open-vocabulary object part segmentation and a Large Language Model (LLM) to ground each part-segment-affordance, OVAL-Prompt demonstrates generalizability to novel object instances, categories, and affordances without domain-specific finetuning. Quantitative experiments demonstrate that without any finetuning, OVAL-Prompt achieves localization accuracy that is competitive with supervised baseline models. Moreover, qualitative experiments show that OVAL-Prompt enables affordance-based robot manipulation of open-vocabulary object instances and categories.
MBot: A Modular Ecosystem for Scalable Robotics Education
Dec 01, 2023



The Michigan Robotics MBot is a low-cost mobile robot platform that has been used to train over 1,400 students in autonomous navigation since 2014 at the University of Michigan and our collaborating colleges. The MBot platform was designed to meet the needs of teaching robotics at scale to match the growth of robotics as a field and an academic discipline. Transformative advancements in robot navigation over the past decades have led to a significant demand for skilled roboticists across industry and academia. This demand has sparked a need for robotics courses in higher education, spanning all levels of undergraduate and graduate experiences. Incorporating real robot platforms into such courses and curricula is effective for conveying the unique challenges of programming embodied agents in real-world environments and sparking student interest. However, teaching with real robots remains challenging due to the cost of hardware and the development effort involved in adapting existing hardware for a new course. In this paper, we describe the design and evolution of the MBot platform, and the underlying principals of scalability and flexibility which are keys to its success.
NARF22: Neural Articulated Radiance Fields for Configuration-Aware Rendering
Oct 03, 2022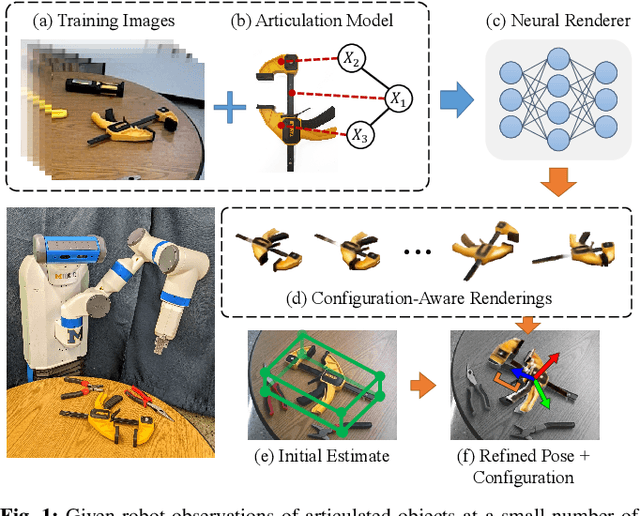
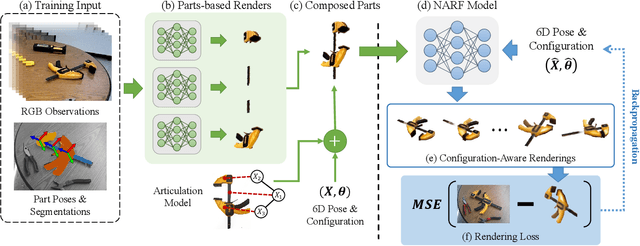

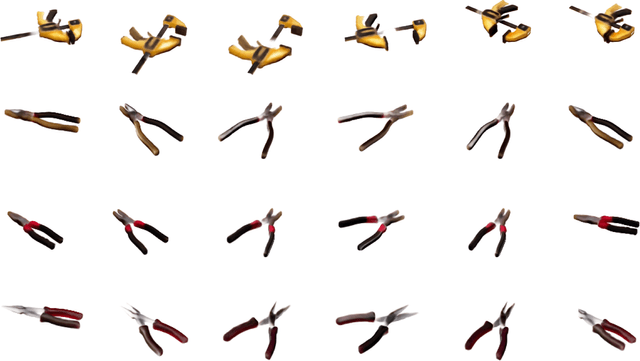
Articulated objects pose a unique challenge for robotic perception and manipulation. Their increased number of degrees-of-freedom makes tasks such as localization computationally difficult, while also making the process of real-world dataset collection unscalable. With the aim of addressing these scalability issues, we propose Neural Articulated Radiance Fields (NARF22), a pipeline which uses a fully-differentiable, configuration-parameterized Neural Radiance Field (NeRF) as a means of providing high quality renderings of articulated objects. NARF22 requires no explicit knowledge of the object structure at inference time. We propose a two-stage parts-based training mechanism which allows the object rendering models to generalize well across the configuration space even if the underlying training data has as few as one configuration represented. We demonstrate the efficacy of NARF22 by training configurable renderers on a real-world articulated tool dataset collected via a Fetch mobile manipulation robot. We show the applicability of the model to gradient-based inference methods through a configuration estimation and 6 degree-of-freedom pose refinement task. The project webpage is available at: https://progress.eecs.umich.edu/projects/narf/.
ProgressLabeller: Visual Data Stream Annotation for Training Object-Centric 3D Perception
Mar 01, 2022

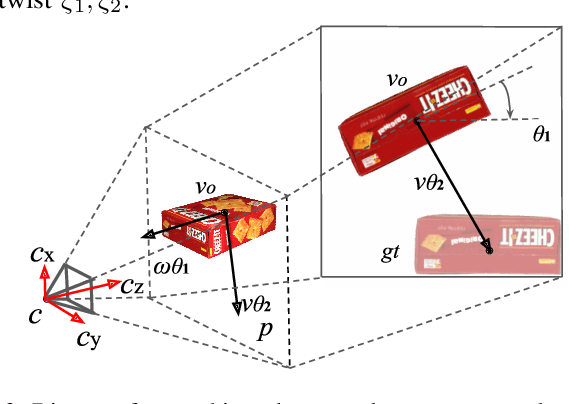
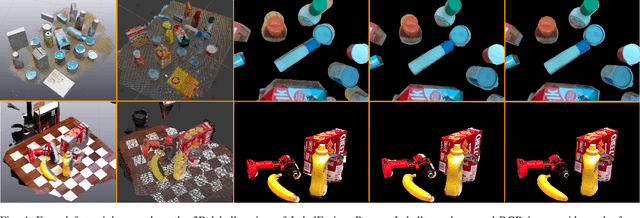
Visual perception tasks often require vast amounts of labelled data, including 3D poses and image space segmentation masks. The process of creating such training data sets can prove difficult or time-intensive to scale up to efficacy for general use. Consider the task of pose estimation for rigid objects. Deep neural network based approaches have shown good performance when trained on large, public datasets. However, adapting these networks for other novel objects, or fine-tuning existing models for different environments, requires significant time investment to generate newly labelled instances. Towards this end, we propose ProgressLabeller as a method for more efficiently generating large amounts of 6D pose training data from color images sequences for custom scenes in a scalable manner. ProgressLabeller is intended to also support transparent or translucent objects, for which the previous methods based on depth dense reconstruction will fail. We demonstrate the effectiveness of ProgressLabeller by rapidly create a dataset of over 1M samples with which we fine-tune a state-of-the-art pose estimation network in order to markedly improve the downstream robotic grasp success rates. ProgressLabeller will be made publicly available soon.
Parts-Based Articulated Object Localization in Clutter Using Belief Propagation
Aug 06, 2020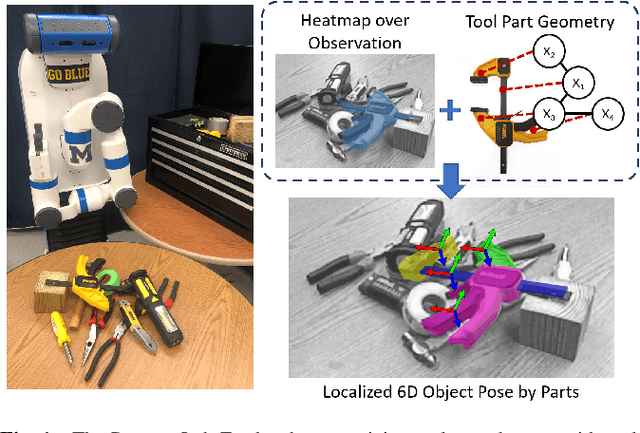
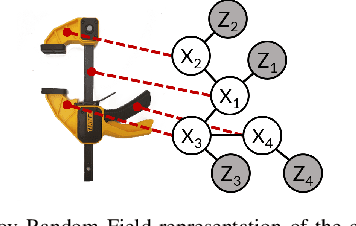
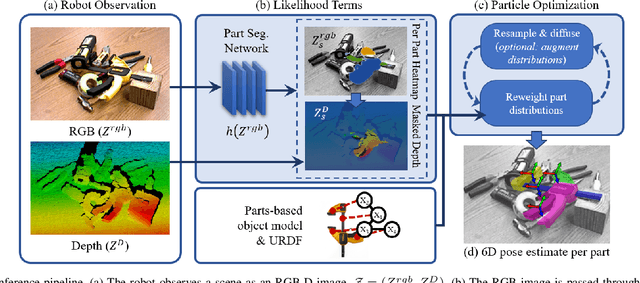

Robots working in human environments must be able to perceive and act on challenging objects with articulations, such as a pile of tools. Articulated objects increase the dimensionality of the pose estimation problem, and partial observations under clutter create additional challenges. To address this problem, we present a generative-discriminative parts-based recognition and localization method for articulated objects in clutter. We formulate the problem of articulated object pose estimation as a Markov Random Field (MRF). Hidden nodes in this MRF express the pose of the object parts, and edges express the articulation constraints between parts. Localization is performed within the MRF using an efficient belief propagation method. The method is informed by both part segmentation heatmaps over the observation, generated by a neural network, and the articulation constraints between object parts. Our generative-discriminative approach allows the proposed method to function in cluttered environments by inferring the pose of occluded parts using hypotheses from the visible parts. We demonstrate the efficacy of our methods in a tabletop environment for recognizing and localizing hand tools in uncluttered and cluttered configurations.