 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Width Scaling of Neural Optimizers Under Matrix Operator Norms I: Row/Column Normalization and Hyperparameter Transfer
Mar 10, 2026A central question in modern deep learning is how to design optimizers whose behavior remains stable as the network width $w$ increases. We address this question by interpreting several widely used neural-network optimizers, including \textrm{AdamW} and \textrm{Muon}, as instances of steepest descent under matrix operator norms. This perspective links optimizer geometry with the Lipschitz structure of the network forward map, and enables width-independent control of both Lipschitz and smoothness constants. However, steepest-descent rules induced by standard $p \to q$ operator norms lack layerwise composability and therefore cannot provide width-independent bounds in deep architectures. We overcome this limitation by introducing a family of mean-normalized operator norms, denoted $\pmean \to \qmean$, that admit layerwise composability, yield width-independent smoothness bounds, and give rise to practical optimizers such as \emph{rescaled} \textrm{AdamW}, row normalization, and column normalization. The resulting learning rate width-aware scaling rules recover $μ$P scaling~\cite{yang2021tensor} as a special case and provide a principled mechanism for cross-width learning-rate transfer across a broad class of optimizers. We further show that \textrm{Muon} can suffer an $\mathcal{O}(\sqrt{w})$ worst-case growth in the smoothness constant, whereas a new family of row-normalized optimizers we propose achieves width-independent smoothness guarantees. Based on the observations, we propose MOGA (Matrix Operator Geometry Aware), a width-aware optimizer based only on row/column-wise normalization that enables stable learning-rate transfer across model widths. Large-scale pre-training on GPT-2 and LLaMA shows that MOGA, especially with row normalization, is competitive with Muon while being notably faster in large-token and low-loss regimes.
FlattenGPT: Depth Compression for Transformer with Layer Flattening
Feb 09, 2026Recent works have indicated redundancy across transformer blocks, prompting the research of depth compression to prune less crucial blocks. However, current ways of entire-block pruning suffer from risks of discarding meaningful cues learned in those blocks, leading to substantial performance degradation. As another line of model compression, channel pruning can better preserve performance, while it cannot reduce model depth and is challenged by inconsistent pruning ratios for individual layers. To pursue better model compression and acceleration, this paper proposes \textbf{FlattenGPT}, a novel way to detect and reduce depth-wise redundancies. By flatting two adjacent blocks into one, it compresses the network depth, meanwhile enables more effective parameter redundancy detection and removal. FlattenGPT allows to preserve the knowledge learned in all blocks, and remains consistent with the original transformer architecture. Extensive experiments demonstrate that FlattenGPT enhances model efficiency with a decent trade-off to performance. It outperforms existing pruning methods in both zero-shot accuracies and WikiText-2 perplexity across various model types and parameter sizes. On LLaMA-2/3 and Qwen-1.5 models, FlattenGPT retains 90-96\% of zero-shot performance with a compression ratio of 20\%. It also outperforms other pruning methods in accelerating LLM inference, making it promising for enhancing the efficiency of transformers.
Looping Back to Move Forward: Recursive Transformers for Efficient and Flexible Large Multimodal Models
Feb 09, 2026Large Multimodal Models (LMMs) have achieved remarkable success in vision-language tasks, yet their vast parameter counts are often underutilized during both training and inference. In this work, we embrace the idea of looping back to move forward: reusing model parameters through recursive refinement to extract stronger multimodal representations without increasing model size. We propose RecursiveVLM, a recursive Transformer architecture tailored for LMMs. Two key innovations enable effective looping: (i) a Recursive Connector that aligns features across recursion steps by fusing intermediate-layer hidden states and applying modality-specific projections, respecting the distinct statistical structures of vision and language tokens; (ii) a Monotonic Recursion Loss that supervises every step and guarantees performance improves monotonically with recursion depth. This design transforms recursion into an on-demand refinement mechanism: delivering strong results with few loops on resource-constrained devices and progressively improving outputs when more computation resources are available. Experiments show consistent gains of +3% over standard Transformers and +7% over vanilla recursive baselines, demonstrating that strategic looping is a powerful path toward efficient, deployment-adaptive LMMs.
PixelGen: Pixel Diffusion Beats Latent Diffusion with Perceptual Loss
Feb 02, 2026Pixel diffusion generates images directly in pixel space in an end-to-end manner, avoiding the artifacts and bottlenecks introduced by VAEs in two-stage latent diffusion. However, it is challenging to optimize high-dimensional pixel manifolds that contain many perceptually irrelevant signals, leaving existing pixel diffusion methods lagging behind latent diffusion models. We propose PixelGen, a simple pixel diffusion framework with perceptual supervision. Instead of modeling the full image manifold, PixelGen introduces two complementary perceptual losses to guide diffusion model towards learning a more meaningful perceptual manifold. An LPIPS loss facilitates learning better local patterns, while a DINO-based perceptual loss strengthens global semantics. With perceptual supervision, PixelGen surpasses strong latent diffusion baselines. It achieves an FID of 5.11 on ImageNet-256 without classifier-free guidance using only 80 training epochs, and demonstrates favorable scaling performance on large-scale text-to-image generation with a GenEval score of 0.79. PixelGen requires no VAEs, no latent representations, and no auxiliary stages, providing a simpler yet more powerful generative paradigm. Codes are publicly available at https://github.com/Zehong-Ma/PixelGen.
Imaginative World Modeling with Scene Graphs for Embodied Agent Navigation
Aug 09, 2025Semantic navigation requires an agent to navigate toward a specified target in an unseen environment. Employing an imaginative navigation strategy that predicts future scenes before taking action, can empower the agent to find target faster. Inspired by this idea, we propose SGImagineNav, a novel imaginative navigation framework that leverages symbolic world modeling to proactively build a global environmental representation. SGImagineNav maintains an evolving hierarchical scene graphs and uses large language models to predict and explore unseen parts of the environment. While existing methods solely relying on past observations, this imaginative scene graph provides richer semantic context, enabling the agent to proactively estimate target locations. Building upon this, SGImagineNav adopts an adaptive navigation strategy that exploits semantic shortcuts when promising and explores unknown areas otherwise to gather additional context. This strategy continuously expands the known environment and accumulates valuable semantic contexts, ultimately guiding the agent toward the target. SGImagineNav is evaluated in both real-world scenarios and simulation benchmarks. SGImagineNav consistently outperforms previous methods, improving success rate to 65.4 and 66.8 on HM3D and HSSD, and demonstrating cross-floor and cross-room navigation in real-world environments, underscoring its effectiveness and generalizability.
NN-Former: Rethinking Graph Structure in Neural Architecture Representation
Jul 01, 2025
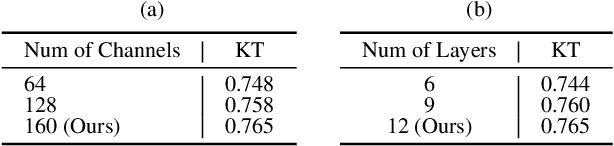
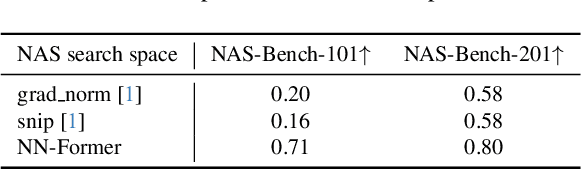
The growing use of deep learning necessitates efficient network design and deployment, making neural predictors vital for estimating attributes such as accuracy and latency. Recently, Graph Neural Networks (GNNs) and transformers have shown promising performance in representing neural architectures. However, each of both methods has its disadvantages. GNNs lack the capabilities to represent complicated features, while transformers face poor generalization when the depth of architecture grows. To mitigate the above issues, we rethink neural architecture topology and show that sibling nodes are pivotal while overlooked in previous research. We thus propose a novel predictor leveraging the strengths of GNNs and transformers to learn the enhanced topology. We introduce a novel token mixer that considers siblings, and a new channel mixer named bidirectional graph isomorphism feed-forward network. Our approach consistently achieves promising performance in both accuracy and latency prediction, providing valuable insights for learning Directed Acyclic Graph (DAG) topology. The code is available at https://github.com/XuRuihan/NNFormer.
What is a Sketch-and-Precondition Derivation for Low-Rank Approximation? Inverse Power Error or Inverse Power Estimation?
Feb 11, 2025Randomized sketching accelerates large-scale numerical linear algebra by reducing computa- tional complexity. While the traditional sketch-and-solve approach reduces the problem size di- rectly through sketching, the sketch-and-precondition method leverages sketching to construct a computational friendly preconditioner. This preconditioner improves the convergence speed of iterative solvers applied to the original problem, maintaining accuracy in the full space. Further- more, the convergence rate of the solver improves at least linearly with the sketch size. Despite its potential, developing a sketch-and-precondition framework for randomized algorithms in low- rank matrix approximation remains an open challenge. We introduce the Error-Powered Sketched Inverse Iteration (EPSI) Method via run sketched Newton iteration for the Lagrange form as a sketch-and-precondition variant for randomized low-rank approximation. Our method achieves theoretical guarantees, including a convergence rate that improves at least linearly with the sketch size.
Latent BKI: Open-Dictionary Continuous Mapping in Visual-Language Latent Spaces with Quantifiable Uncertainty
Oct 15, 2024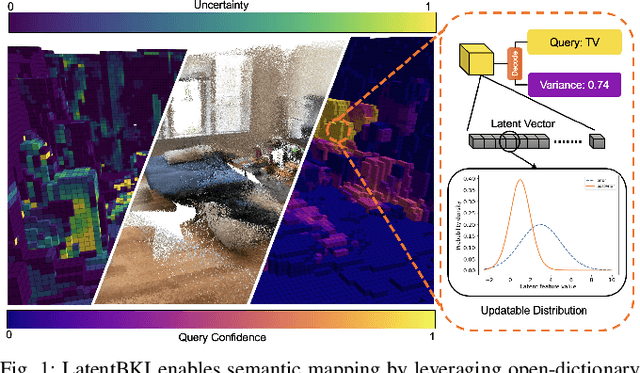



This paper introduces a novel probabilistic mapping algorithm, Latent BKI, which enables open-vocabulary mapping with quantifiable uncertainty. Traditionally, semantic mapping algorithms focus on a fixed set of semantic categories which limits their applicability for complex robotic tasks. Vision-Language (VL) models have recently emerged as a technique to jointly model language and visual features in a latent space, enabling semantic recognition beyond a predefined, fixed set of semantic classes. Latent BKI recurrently incorporates neural embeddings from VL models into a voxel map with quantifiable uncertainty, leveraging the spatial correlations of nearby observations through Bayesian Kernel Inference (BKI). Latent BKI is evaluated against similar explicit semantic mapping and VL mapping frameworks on the popular MatterPort-3D and Semantic KITTI data sets, demonstrating that Latent BKI maintains the probabilistic benefits of continuous mapping with the additional benefit of open-dictionary queries. Real-world experiments demonstrate applicability to challenging indoor environments.
Single-View 3D Reconstruction via SO(2)-Equivariant Gaussian Sculpting Networks
Sep 11, 2024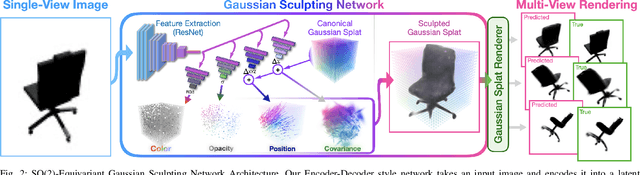
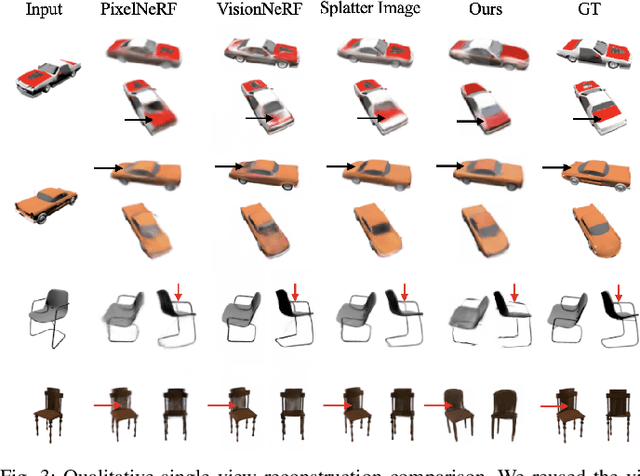

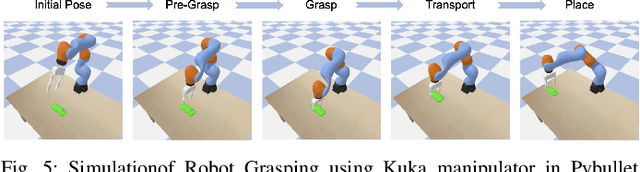
This paper introduces SO(2)-Equivariant Gaussian Sculpting Networks (GSNs) as an approach for SO(2)-Equivariant 3D object reconstruction from single-view image observations. GSNs take a single observation as input to generate a Gaussian splat representation describing the observed object's geometry and texture. By using a shared feature extractor before decoding Gaussian colors, covariances, positions, and opacities, GSNs achieve extremely high throughput (>150FPS). Experiments demonstrate that GSNs can be trained efficiently using a multi-view rendering loss and are competitive, in quality, with expensive diffusion-based reconstruction algorithms. The GSN model is validated on multiple benchmark experiments. Moreover, we demonstrate the potential for GSNs to be used within a robotic manipulation pipeline for object-centric grasping.
Stein Variational Belief Propagation for Multi-Robot Coordination
Nov 28, 2023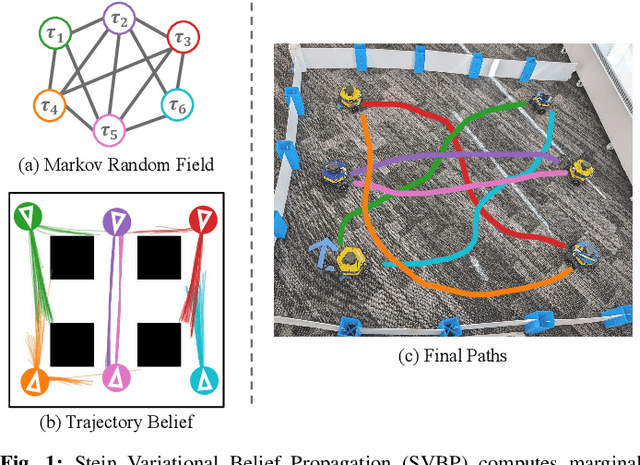
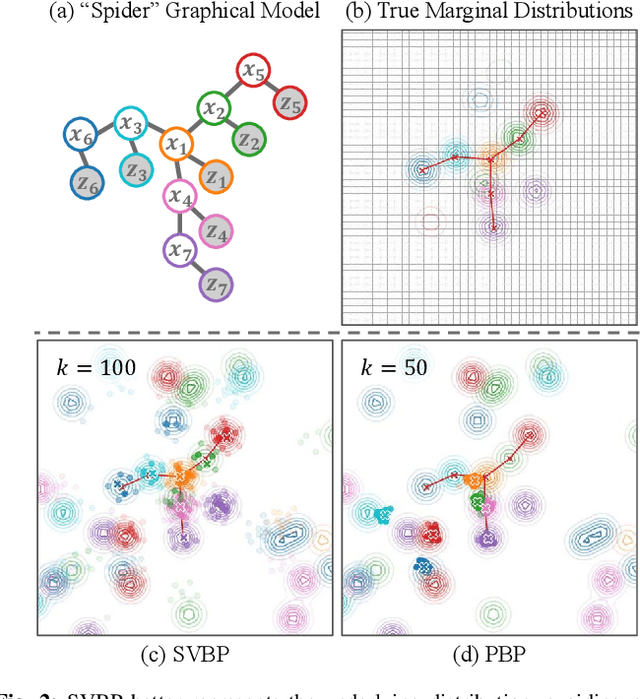
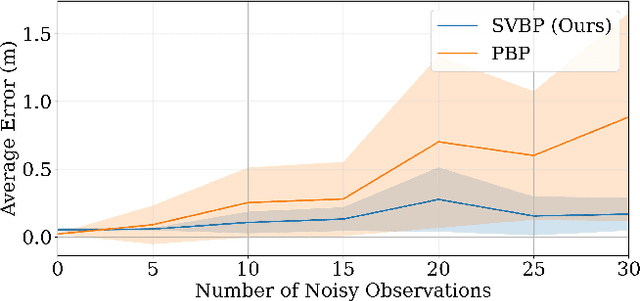
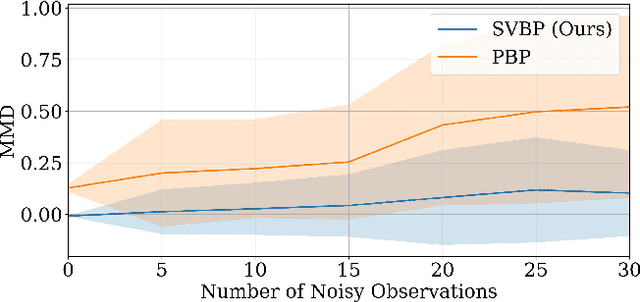
Decentralized coordination for multi-robot systems involves planning in challenging, high-dimensional spaces. The planning problem is particularly challenging in the presence of obstacles and different sources of uncertainty such as inaccurate dynamic models and sensor noise. In this paper, we introduce Stein Variational Belief Propagation (SVBP), a novel algorithm for performing inference over nonparametric marginal distributions of nodes in a graph. We apply SVBP to multi-robot coordination by modelling a robot swarm as a graphical model and performing inference for each robot. We demonstrate our algorithm on a simulated multi-robot perception task, and on a multi-robot planning task within a Model-Predictive Control (MPC) framework, on both simulated and real-world mobile robots. Our experiments show that SVBP represents multi-modal distributions better than sampling-based or Gaussian baselines, resulting in improved performance on perception and planning tasks. Furthermore, we show that SVBP's ability to represent diverse trajectories for decentralized multi-robot planning makes it less prone to deadlock scenarios than leading baselines.