 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStaggered Batch Scheduling: Co-optimizing Time-to-First-Token and Throughput for High-Efficiency LLM Inference
Dec 18, 2025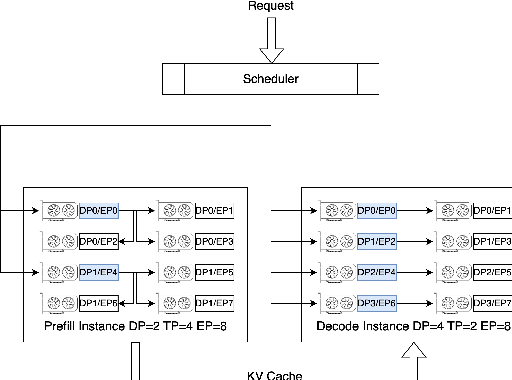
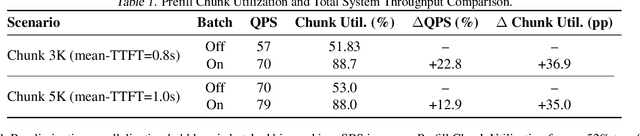
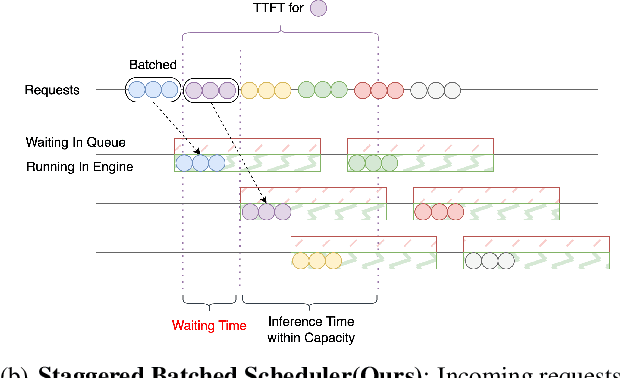
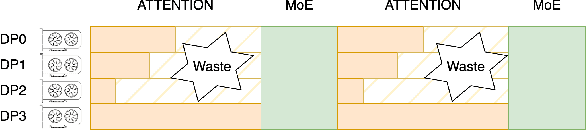
The evolution of Large Language Model (LLM) serving towards complex, distributed architectures--specifically the P/D-separated, large-scale DP+EP paradigm--introduces distinct scheduling challenges. Unlike traditional deployments where schedulers can treat instances as black boxes, DP+EP architectures exhibit high internal synchronization costs. We identify that immediate request dispatching in such systems leads to severe in-engine queuing and parallelization bubbles, degrading Time-to-First-Token (TTFT). To address this, we propose Staggered Batch Scheduling (SBS), a mechanism that deliberately buffers requests to form optimal execution batches. This temporal decoupling eliminates internal queuing bubbles without compromising throughput. Furthermore, leveraging the scheduling window created by buffering, we introduce a Load-Aware Global Allocation strategy that balances computational load across DP units for both Prefill and Decode phases. Deployed on a production H800 cluster serving Deepseek-V3, our system reduces TTFT by 30%-40% and improves throughput by 15%-20% compared to state-of-the-art immediate scheduling baselines.
Equivariant Neural Networks for General Linear Symmetries on Lie Algebras
Oct 27, 2025Encoding symmetries is a powerful inductive bias for improving the generalization of deep neural networks. However, most existing equivariant models are limited to simple symmetries like rotations, failing to address the broader class of general linear transformations, GL(n), that appear in many scientific domains. We introduce Reductive Lie Neurons (ReLNs), a novel neural network architecture exactly equivariant to these general linear symmetries. ReLNs are designed to operate directly on a wide range of structured inputs, including general n-by-n matrices. ReLNs introduce a novel adjoint-invariant bilinear layer to achieve stable equivariance for both Lie-algebraic features and matrix-valued inputs, without requiring redesign for each subgroup. This architecture overcomes the limitations of prior equivariant networks that only apply to compact groups or simple vector data. We validate ReLNs' versatility across a spectrum of tasks: they outperform existing methods on algebraic benchmarks with sl(3) and sp(4) symmetries and achieve competitive results on a Lorentz-equivariant particle physics task. In 3D drone state estimation with geometric uncertainty, ReLNs jointly process velocities and covariances, yielding significant improvements in trajectory accuracy. ReLNs provide a practical and general framework for learning with broad linear group symmetries on Lie algebras and matrix-valued data. Project page: https://reductive-lie-neuron.github.io/
Vysics: Object Reconstruction Under Occlusion by Fusing Vision and Contact-Rich Physics
Apr 25, 2025



We introduce Vysics, a vision-and-physics framework for a robot to build an expressive geometry and dynamics model of a single rigid body, using a seconds-long RGBD video and the robot's proprioception. While the computer vision community has built powerful visual 3D perception algorithms, cluttered environments with heavy occlusions can limit the visibility of objects of interest. However, observed motion of partially occluded objects can imply physical interactions took place, such as contact with a robot or the environment. These inferred contacts can supplement the visible geometry with "physible geometry," which best explains the observed object motion through physics. Vysics uses a vision-based tracking and reconstruction method, BundleSDF, to estimate the trajectory and the visible geometry from an RGBD video, and an odometry-based model learning method, Physics Learning Library (PLL), to infer the "physible" geometry from the trajectory through implicit contact dynamics optimization. The visible and "physible" geometries jointly factor into optimizing a signed distance function (SDF) to represent the object shape. Vysics does not require pretraining, nor tactile or force sensors. Compared with vision-only methods, Vysics yields object models with higher geometric accuracy and better dynamics prediction in experiments where the object interacts with the robot and the environment under heavy occlusion. Project page: https://vysics-vision-and-physics.github.io/
Generative LiDAR Editing with Controllable Novel Object Layouts
Nov 30, 2024



We propose a framework to edit real-world Lidar scans with novel object layouts while preserving a realistic background environment. Compared to the synthetic data generation frameworks where Lidar point clouds are generated from scratch, our framework focuses on new scenario generation in a given background environment, and our method also provides labels for the generated data. This approach ensures the generated data remains relevant to the specific environment, aiding both the development and the evaluation of algorithms in real-world scenarios. Compared with novel view synthesis, our framework allows the creation of counterfactual scenarios with significant changes in the object layout and does not rely on multi-frame optimization. In our framework, the object removal and insertion are supported by generative background inpainting and object point cloud completion, and the entire pipeline is built upon spherical voxelization, which realizes the correct Lidar projective geometry by construction. Experiments show that our framework generates realistic Lidar scans with object layout changes and benefits the development of Lidar-based self-driving systems.
Latent BKI: Open-Dictionary Continuous Mapping in Visual-Language Latent Spaces with Quantifiable Uncertainty
Oct 15, 2024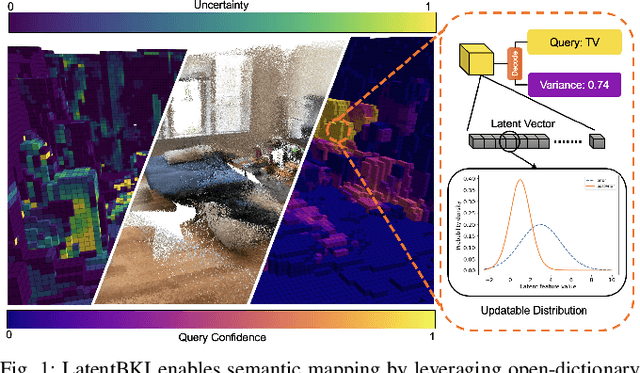



This paper introduces a novel probabilistic mapping algorithm, Latent BKI, which enables open-vocabulary mapping with quantifiable uncertainty. Traditionally, semantic mapping algorithms focus on a fixed set of semantic categories which limits their applicability for complex robotic tasks. Vision-Language (VL) models have recently emerged as a technique to jointly model language and visual features in a latent space, enabling semantic recognition beyond a predefined, fixed set of semantic classes. Latent BKI recurrently incorporates neural embeddings from VL models into a voxel map with quantifiable uncertainty, leveraging the spatial correlations of nearby observations through Bayesian Kernel Inference (BKI). Latent BKI is evaluated against similar explicit semantic mapping and VL mapping frameworks on the popular MatterPort-3D and Semantic KITTI data sets, demonstrating that Latent BKI maintains the probabilistic benefits of continuous mapping with the additional benefit of open-dictionary queries. Real-world experiments demonstrate applicability to challenging indoor environments.
SE3ET: SE(3)-Equivariant Transformer for Low-Overlap Point Cloud Registration
Jul 23, 2024



Partial point cloud registration is a challenging problem in robotics, especially when the robot undergoes a large transformation, causing a significant initial pose error and a low overlap between measurements. This work proposes exploiting equivariant learning from 3D point clouds to improve registration robustness. We propose SE3ET, an SE(3)-equivariant registration framework that employs equivariant point convolution and equivariant transformer designs to learn expressive and robust geometric features. We tested the proposed registration method on indoor and outdoor benchmarks where the point clouds are under arbitrary transformations and low overlapping ratios. We also provide generalization tests and run-time performance.
Lie Neurons: Adjoint-Equivariant Neural Networks for Semisimple Lie Algebras
Oct 06, 2023



This paper proposes an adjoint-equivariant neural network that takes Lie algebra data as input. Various types of equivariant neural networks have been proposed in the literature, which treat the input data as elements in a vector space carrying certain types of transformations. In comparison, we aim to process inputs that are transformations between vector spaces. The change of basis on transformation is described by conjugations, inducing the adjoint-equivariance relationship that our model is designed to capture. Leveraging the invariance property of the Killing form, the proposed network is a general framework that works for arbitrary semisimple Lie algebras. Our network possesses a simple structure that can be viewed as a Lie algebraic generalization of a multi-layer perceptron (MLP). This work extends the application of equivariant feature learning. As an example, we showcase its value in homography modeling using sl(3) Lie algebra.
4D Panoptic Segmentation as Invariant and Equivariant Field Prediction
Mar 28, 2023In this paper, we develop rotation-equivariant neural networks for 4D panoptic segmentation. 4D panoptic segmentation is a recently established benchmark task for autonomous driving, which requires recognizing semantic classes and object instances on the road based on LiDAR scans, as well as assigning temporally consistent IDs to instances across time. We observe that the driving scenario is symmetric to rotations on the ground plane. Therefore, rotation-equivariance could provide better generalization and more robust feature learning. Specifically, we review the object instance clustering strategies, and restate the centerness-based approach and the offset-based approach as the prediction of invariant scalar fields and equivariant vector fields. Other sub-tasks are also unified from this perspective, and different invariant and equivariant layers are designed to facilitate their predictions. Through evaluation on the standard 4D panoptic segmentation benchmark of SemanticKITTI, we show that our equivariant models achieve higher accuracy with lower computational costs compared to their non-equivariant counterparts. Moreover, our method sets the new state-of-the-art performance and achieves 1st place on the SemanticKITTI 4D Panoptic Segmentation leaderboard.
MonoEdge: Monocular 3D Object Detection Using Local Perspectives
Jan 04, 2023We propose a novel approach for monocular 3D object detection by leveraging local perspective effects of each object. While the global perspective effect shown as size and position variations has been exploited for monocular 3D detection extensively, the local perspectives has long been overlooked. We design a local perspective module to regress a newly defined variable named keyedge-ratios as the parameterization of the local shape distortion to account for the local perspective, and derive the object depth and yaw angle from it. Theoretically, this module does not rely on the pixel-wise size or position in the image of the objects, therefore independent of the camera intrinsic parameters. By plugging this module in existing monocular 3D object detection frameworks, we incorporate the local perspective distortion with global perspective effect for monocular 3D reasoning, and we demonstrate the effectiveness and superior performance over strong baseline methods in multiple datasets.
Mix-Teaching: A Simple, Unified and Effective Semi-Supervised Learning Framework for Monocular 3D Object Detection
Jul 10, 2022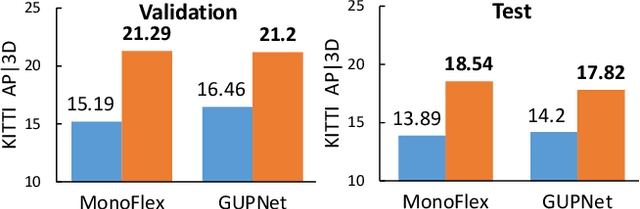
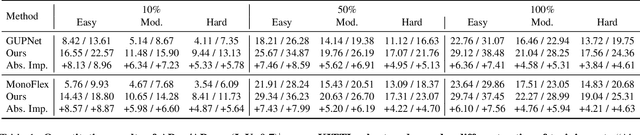
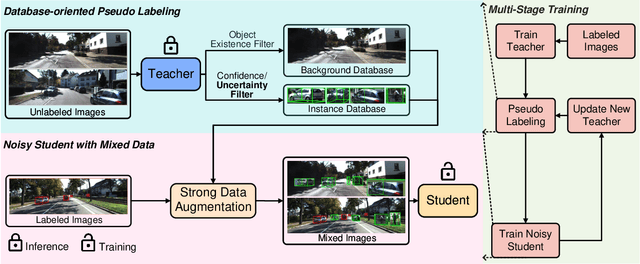

Monocular 3D object detection is an essential perception task for autonomous driving. However, the high reliance on large-scale labeled data make it costly and time-consuming during model optimization. To reduce such over-reliance on human annotations, we propose Mix-Teaching, an effective semi-supervised learning framework applicable to employ both labeled and unlabeled images in training stage. Mix-Teaching first generates pseudo-labels for unlabeled images by self-training. The student model is then trained on the mixed images possessing much more intensive and precise labeling by merging instance-level image patches into empty backgrounds or labeled images. This is the first to break the image-level limitation and put high-quality pseudo labels from multi frames into one image for semi-supervised training. Besides, as a result of the misalignment between confidence score and localization quality, it's hard to discriminate high-quality pseudo-labels from noisy predictions using only confidence-based criterion. To that end, we further introduce an uncertainty-based filter to help select reliable pseudo boxes for the above mixing operation. To the best of our knowledge, this is the first unified SSL framework for monocular 3D object detection. Mix-Teaching consistently improves MonoFlex and GUPNet by significant margins under various labeling ratios on KITTI dataset. For example, our method achieves around +6.34% AP@0.7 improvement against the GUPNet baseline on validation set when using only 10% labeled data. Besides, by leveraging full training set and the additional 48K raw images of KITTI, it can further improve the MonoFlex by +4.65% improvement on AP@0.7 for car detection, reaching 18.54% AP@0.7, which ranks the 1st place among all monocular based methods on KITTI test leaderboard. The code and pretrained models will be released at https://github.com/yanglei18/Mix-Teaching.