 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefFusionNet: Learning Multimodal Goal Shapes for Deformable Object Manipulation via a Diffusion-based Probabilistic Model
Jun 23, 2025Deformable object manipulation is critical to many real-world robotic applications, ranging from surgical robotics and soft material handling in manufacturing to household tasks like laundry folding. At the core of this important robotic field is shape servoing, a task focused on controlling deformable objects into desired shapes. The shape servoing formulation requires the specification of a goal shape. However, most prior works in shape servoing rely on impractical goal shape acquisition methods, such as laborious domain-knowledge engineering or manual manipulation. DefGoalNet previously posed the current state-of-the-art solution to this problem, which learns deformable object goal shapes directly from a small number of human demonstrations. However, it significantly struggles in multi-modal settings, where multiple distinct goal shapes can all lead to successful task completion. As a deterministic model, DefGoalNet collapses these possibilities into a single averaged solution, often resulting in an unusable goal. In this paper, we address this problem by developing DefFusionNet, a novel neural network that leverages the diffusion probabilistic model to learn a distribution over all valid goal shapes rather than predicting a single deterministic outcome. This enables the generation of diverse goal shapes and avoids the averaging artifacts. We demonstrate our method's effectiveness on robotic tasks inspired by both manufacturing and surgical applications, both in simulation and on a physical robot. Our work is the first generative model capable of producing a diverse, multi-modal set of deformable object goals for real-world robotic applications.
Generative LiDAR Editing with Controllable Novel Object Layouts
Nov 30, 2024



We propose a framework to edit real-world Lidar scans with novel object layouts while preserving a realistic background environment. Compared to the synthetic data generation frameworks where Lidar point clouds are generated from scratch, our framework focuses on new scenario generation in a given background environment, and our method also provides labels for the generated data. This approach ensures the generated data remains relevant to the specific environment, aiding both the development and the evaluation of algorithms in real-world scenarios. Compared with novel view synthesis, our framework allows the creation of counterfactual scenarios with significant changes in the object layout and does not rely on multi-frame optimization. In our framework, the object removal and insertion are supported by generative background inpainting and object point cloud completion, and the entire pipeline is built upon spherical voxelization, which realizes the correct Lidar projective geometry by construction. Experiments show that our framework generates realistic Lidar scans with object layout changes and benefits the development of Lidar-based self-driving systems.
Reward Learning from Suboptimal Demonstrations with Applications in Surgical Electrocautery
Apr 10, 2024Automating robotic surgery via learning from demonstration (LfD) techniques is extremely challenging. This is because surgical tasks often involve sequential decision-making processes with complex interactions of physical objects and have low tolerance for mistakes. Prior works assume that all demonstrations are fully observable and optimal, which might not be practical in the real world. This paper introduces a sample-efficient method that learns a robust reward function from a limited amount of ranked suboptimal demonstrations consisting of partial-view point cloud observations. The method then learns a policy by optimizing the learned reward function using reinforcement learning (RL). We show that using a learned reward function to obtain a policy is more robust than pure imitation learning. We apply our approach on a physical surgical electrocautery task and demonstrate that our method can perform well even when the provided demonstrations are suboptimal and the observations are high-dimensional point clouds.
DefGoalNet: Contextual Goal Learning from Demonstrations For Deformable Object Manipulation
Sep 25, 2023

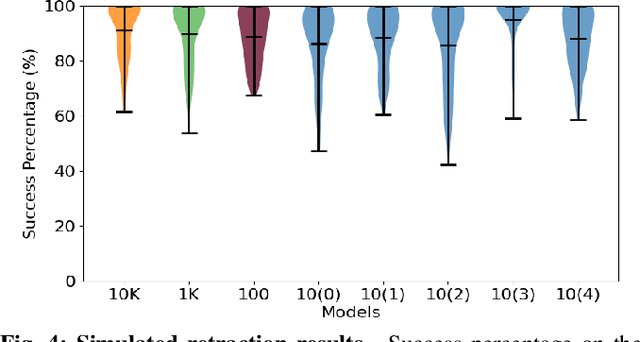

Shape servoing, a robotic task dedicated to controlling objects to desired goal shapes, is a promising approach to deformable object manipulation. An issue arises, however, with the reliance on the specification of a goal shape. This goal has been obtained either by a laborious domain knowledge engineering process or by manually manipulating the object into the desired shape and capturing the goal shape at that specific moment, both of which are impractical in various robotic applications. In this paper, we solve this problem by developing a novel neural network DefGoalNet, which learns deformable object goal shapes directly from a small number of human demonstrations. We demonstrate our method's effectiveness on various robotic tasks, both in simulation and on a physical robot. Notably, in the surgical retraction task, even when trained with as few as 10 demonstrations, our method achieves a median success percentage of nearly 90%. These results mark a substantial advancement in enabling shape servoing methods to bring deformable object manipulation closer to practical, real-world applications.