 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Operators for Design-Space Surrogate Modeling of Tendon-Actuated Continuum Robots
May 18, 2026Continuum robots enable dexterous manipulation in constrained environments, but require accurate and efficient models for real-time manipulation and control. Traditional physics-based models can be computationally expensive and may suffer from inaccuracies due to unmodeled effects, while current learning-based methods often generalize poorly beyond the specific robot on which they are trained. We present a formulation of surrogate modeling for tendon-driven continuum robots as an operator learning problem that maps robot design parameters and tendon actuation inputs to resulting configurations. This formulation enables a single trained model to generalize across a large class of robot designs. We develop four novel neural operator architectures--two based on Deep Operator Networks (DeepONets) and two based on Fourier Neural Operators (FNOs)--and train them on simulation data to predict robot configurations. All architectures achieve good accuracy while allowing for fast and accurate generalization across designs. Our results demonstrate that operator learning provides an effective and generalizable surrogate for continuum robot mechanics in the design space, enabling fast modeling for control, planning, and design optimization in surgical and industrial applications.
Open-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
PinPoint: Monocular Needle Pose Estimation for Robotic Suturing via Stein Variational Newton and Geometric Residuals
Mar 24, 2026Reliable estimation of surgical needle 3D position and orientation is essential for autonomous robotic suturing, yet existing methods operate almost exclusively under stereoscopic vision. In monocular endoscopic settings, common in transendoscopic and intraluminal procedures, depth ambiguity and rotational symmetry render needle pose estimation inherently ill-posed, producing a multimodal distribution over feasible configurations, rather than a single, well-grounded estimate. We present PinPoint, a probabilistic variational inference framework that treats this ambiguity directly, maintaining a distribution of pose hypotheses rather than suppressing it. PinPoint combines monocular image observations with robot-grasp constraints through analytical geometric likelihoods with closed-form Jacobians. This framework enables efficient Gauss-Newton preconditioning in a Stein Variational Newton inference, where second-order particle transport deterministically moves particles toward high-probability regions while kernel-based repulsion preserves diversity in the multimodal structure. On real needle-tracking sequences, PinPoint reduces mean translational error by 80% (down to 1.00 mm) and rotational error by 78% (down to 13.80°) relative to a particle-filter baseline, with substantially better-calibrated uncertainty. On induced-rotation sequences, where monocular ambiguity is most severe, PinPoint maintains a bimodal posterior 84% of the time, almost three times the rate of the particle filter baseline, correctly preserving the alternative hypothesis rather than committing prematurely to one mode. Suturing experiments in ex vivo tissue demonstrate stable tracking through intermittent occlusion, with average errors during occlusion of 1.34 mm in translation and 19.18° in rotation, even when the needle is fully embedded.
Fast Continuum Robot Shape and External Load State Estimation on SE(3)
Jan 08, 2026Previous on-manifold approaches to continuum robot state estimation have typically adopted simplified Cosserat rod models, which cannot directly account for actuation inputs or external loads. We introduce a general framework that incorporates uncertainty models for actuation (e.g., tendon tensions), applied forces and moments, process noise, boundary conditions, and arbitrary backbone measurements. By adding temporal priors across time steps, our method additionally performs joint estimation in both the spatial (arclength) and temporal domains, enabling full \textit{spacetime} state estimation. Discretizing the arclength domain yields a factor graph representation of the continuum robot model, which can be exploited for fast batch sparse nonlinear optimization in the style of SLAM. The framework is general and applies to a broad class of continuum robots; as illustrative cases, we show (i) tendon-driven robots in simulation, where we demonstrate real-time kinematics with uncertainty, tip force sensing from position feedback, and distributed load estimation from backbone strain, and (ii) a surgical concentric tube robot in experiment, where we validate accurate kinematics and tip force estimation, highlighting potential for surgical palpation.
ProbeMDE: Uncertainty-Guided Active Proprioception for Monocular Depth Estimation in Surgical Robotics
Dec 17, 2025Monocular depth estimation (MDE) provides a useful tool for robotic perception, but its predictions are often uncertain and inaccurate in challenging environments such as surgical scenes where textureless surfaces, specular reflections, and occlusions are common. To address this, we propose ProbeMDE, a cost-aware active sensing framework that combines RGB images with sparse proprioceptive measurements for MDE. Our approach utilizes an ensemble of MDE models to predict dense depth maps conditioned on both RGB images and on a sparse set of known depth measurements obtained via proprioception, where the robot has touched the environment in a known configuration. We quantify predictive uncertainty via the ensemble's variance and measure the gradient of the uncertainty with respect to candidate measurement locations. To prevent mode collapse while selecting maximally informative locations to propriocept (touch), we leverage Stein Variational Gradient Descent (SVGD) over this gradient map. We validate our method in both simulated and physical experiments on central airway obstruction surgical phantoms. Our results demonstrate that our approach outperforms baseline methods across standard depth estimation metrics, achieving higher accuracy while minimizing the number of required proprioceptive measurements. Project page: https://brittonjordan.github.io/probe_mde/
A Supervised Autonomous Resection and Retraction Framework for Transurethral Enucleation of the Prostatic Median Lobe
Nov 11, 2025Concentric tube robots (CTRs) offer dexterous motion at millimeter scales, enabling minimally invasive procedures through natural orifices. This work presents a coordinated model-based resection planner and learning-based retraction network that work together to enable semi-autonomous tissue resection using a dual-arm transurethral concentric tube robot (the Virtuoso). The resection planner operates directly on segmented CT volumes of prostate phantoms, automatically generating tool trajectories for a three-phase median lobe resection workflow: left/median trough resection, right/median trough resection, and median blunt dissection. The retraction network, PushCVAE, trained on surgeon demonstrations, generates retractions according to the procedural phase. The procedure is executed under Level-3 (supervised) autonomy on a prostate phantom composed of hydrogel materials that replicate the mechanical and cutting properties of tissue. As a feasibility study, we demonstrate that our combined autonomous system achieves a 97.1% resection of the targeted volume of the median lobe. Our study establishes a foundation for image-guided autonomy in transurethral robotic surgery and represents a first step toward fully automated minimally-invasive prostate enucleation.
DefFusionNet: Learning Multimodal Goal Shapes for Deformable Object Manipulation via a Diffusion-based Probabilistic Model
Jun 23, 2025Deformable object manipulation is critical to many real-world robotic applications, ranging from surgical robotics and soft material handling in manufacturing to household tasks like laundry folding. At the core of this important robotic field is shape servoing, a task focused on controlling deformable objects into desired shapes. The shape servoing formulation requires the specification of a goal shape. However, most prior works in shape servoing rely on impractical goal shape acquisition methods, such as laborious domain-knowledge engineering or manual manipulation. DefGoalNet previously posed the current state-of-the-art solution to this problem, which learns deformable object goal shapes directly from a small number of human demonstrations. However, it significantly struggles in multi-modal settings, where multiple distinct goal shapes can all lead to successful task completion. As a deterministic model, DefGoalNet collapses these possibilities into a single averaged solution, often resulting in an unusable goal. In this paper, we address this problem by developing DefFusionNet, a novel neural network that leverages the diffusion probabilistic model to learn a distribution over all valid goal shapes rather than predicting a single deterministic outcome. This enables the generation of diverse goal shapes and avoids the averaging artifacts. We demonstrate our method's effectiveness on robotic tasks inspired by both manufacturing and surgical applications, both in simulation and on a physical robot. Our work is the first generative model capable of producing a diverse, multi-modal set of deformable object goals for real-world robotic applications.
From Monocular Vision to Autonomous Action: Guiding Tumor Resection via 3D Reconstruction
Mar 20, 2025Surgical automation requires precise guidance and understanding of the scene. Current methods in the literature rely on bulky depth cameras to create maps of the anatomy, however this does not translate well to space-limited clinical applications. Monocular cameras are small and allow minimally invasive surgeries in tight spaces but additional processing is required to generate 3D scene understanding. We propose a 3D mapping pipeline that uses only RGB images to create segmented point clouds of the target anatomy. To ensure the most precise reconstruction, we compare different structure from motion algorithms' performance on mapping the central airway obstructions, and test the pipeline on a downstream task of tumor resection. In several metrics, including post-procedure tissue model evaluation, our pipeline performs comparably to RGB-D cameras and, in some cases, even surpasses their performance. These promising results demonstrate that automation guidance can be achieved in minimally invasive procedures with monocular cameras. This study is a step toward the complete autonomy of surgical robots.
Early Failure Detection in Autonomous Surgical Soft-Tissue Manipulation via Uncertainty Quantification
Jan 17, 2025Autonomous surgical robots are a promising solution to the increasing demand for surgery amid a shortage of surgeons. Recent work has proposed learning-based approaches for the autonomous manipulation of soft tissue. However, due to variability in tissue geometries and stiffnesses, these methods do not always perform optimally, especially in out-of-distribution settings. We propose, develop, and test the first application of uncertainty quantification to learned surgical soft-tissue manipulation policies as an early identification system for task failures. We analyze two different methods of uncertainty quantification, deep ensembles and Monte Carlo dropout, and find that deep ensembles provide a stronger signal of future task success or failure. We validate our approach using the physical daVinci Research Kit (dVRK) surgical robot to perform physical soft-tissue manipulation. We show that we are able to successfully detect task failure and request human intervention when necessary while still enabling autonomous manipulation when possible. Our learned tissue manipulation policy with uncertainty-based early failure detection achieves a zero-shot sim2real performance improvement of 47.5% over the prior state of the art in learned soft-tissue manipulation. We also show that our method generalizes well to new types of tissue as well as to a bimanual soft tissue manipulation task.
Leveraging Fixed-Parameter Tractability for Robot Inspection Planning
Jun 28, 2024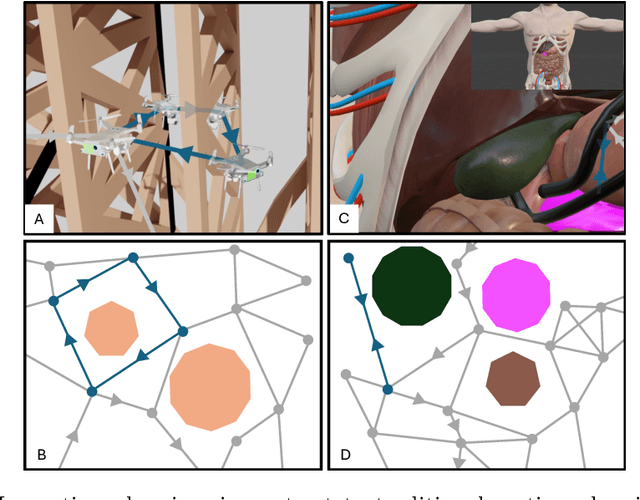
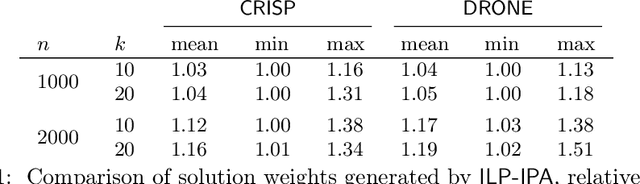
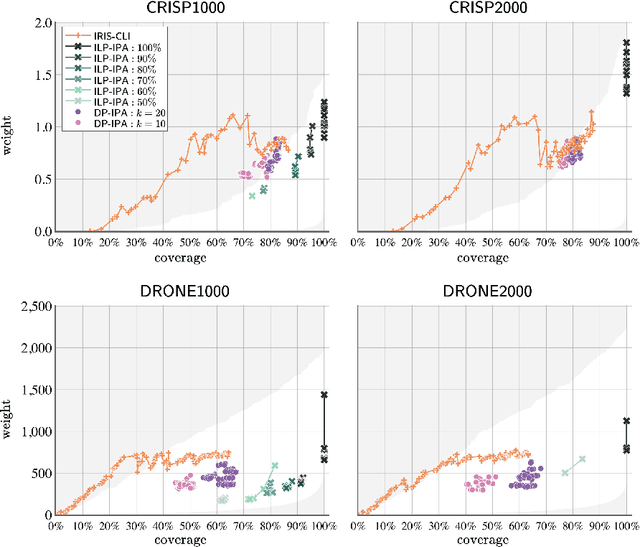
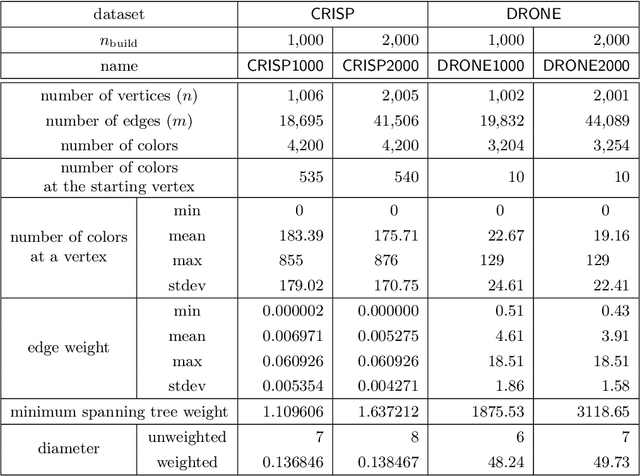
Autonomous robotic inspection, where a robot moves through its environment and inspects points of interest, has applications in industrial settings, structural health monitoring, and medicine. Planning the paths for a robot to safely and efficiently perform such an inspection is an extremely difficult algorithmic challenge. In this work we consider an abstraction of the inspection planning problem which we term Graph Inspection. We give two exact algorithms for this problem, using dynamic programming and integer linear programming. We analyze the performance of these methods, and present multiple approaches to achieve scalability. We demonstrate significant improvement both in path weight and inspection coverage over a state-of-the-art approach on two robotics tasks in simulation, a bridge inspection task by a UAV and a surgical inspection task using a medical robot.