 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProof of Time: A Benchmark for Evaluating Scientific Idea Judgments
Jan 12, 2026Large language models are increasingly being used to assess and forecast research ideas, yet we lack scalable ways to evaluate the quality of models' judgments about these scientific ideas. Towards this goal, we introduce PoT, a semi-verifiable benchmarking framework that links scientific idea judgments to downstream signals that become observable later (e.g., citations and shifts in researchers' agendas). PoT freezes a pre-cutoff snapshot of evidence in an offline sandbox and asks models to forecast post-cutoff outcomes, enabling verifiable evaluation when ground truth arrives, scalable benchmarking without exhaustive expert annotation, and analysis of human-model misalignment against signals such as peer-review awards. In addition, PoT provides a controlled testbed for agent-based research judgments that evaluate scientific ideas, comparing tool-using agents to non-agent baselines under prompt ablations and budget scaling. Across 30,000+ instances spanning four benchmark domains, we find that, compared with non-agent baselines, higher interaction budgets generally improve agent performance, while the benefit of tool use is strongly task-dependent. By combining time-partitioned, future-verifiable targets with an offline sandbox for tool use, PoT supports scalable evaluation of agents on future-facing scientific idea judgment tasks.
Towards a Science of Scaling Agent Systems
Dec 17, 2025Agents, language model-based systems that are capable of reasoning, planning, and acting are becoming the dominant paradigm for real-world AI applications. Despite this widespread adoption, the principles that determine their performance remain underexplored. We address this by deriving quantitative scaling principles for agent systems. We first formalize a definition for agentic evaluation and characterize scaling laws as the interplay between agent quantity, coordination structure, model capability, and task properties. We evaluate this across four benchmarks: Finance-Agent, BrowseComp-Plus, PlanCraft, and Workbench. With five canonical agent architectures (Single-Agent and four Multi-Agent Systems: Independent, Centralized, Decentralized, Hybrid), instantiated across three LLM families, we perform a controlled evaluation spanning 180 configurations. We derive a predictive model using coordination metrics, that achieves cross-validated R^2=0.524, enabling prediction on unseen task domains. We identify three effects: (1) a tool-coordination trade-off: under fixed computational budgets, tool-heavy tasks suffer disproportionately from multi-agent overhead. (2) a capability saturation: coordination yields diminishing or negative returns once single-agent baselines exceed ~45%. (3) topology-dependent error amplification: independent agents amplify errors 17.2x, while centralized coordination contains this to 4.4x. Centralized coordination improves performance by 80.8% on parallelizable tasks, while decentralized coordination excels on web navigation (+9.2% vs. +0.2%). Yet for sequential reasoning tasks, every multi-agent variants degraded performance by 39-70%. The framework predicts the optimal coordination strategy for 87% of held-out configurations. Out-of-sample validation on GPT-5.2, achieves MAE=0.071 and confirms four of five scaling principles generalize to unseen frontier models.
SRT-H: A Hierarchical Framework for Autonomous Surgery via Language Conditioned Imitation Learning
May 15, 2025Research on autonomous robotic surgery has largely focused on simple task automation in controlled environments. However, real-world surgical applications require dexterous manipulation over extended time scales while demanding generalization across diverse variations in human tissue. These challenges remain difficult to address using existing logic-based or conventional end-to-end learning strategies. To bridge this gap, we propose a hierarchical framework for dexterous, long-horizon surgical tasks. Our method employs a high-level policy for task planning and a low-level policy for generating task-space controls for the surgical robot. The high-level planner plans tasks using language, producing task-specific or corrective instructions that guide the robot at a coarse level. Leveraging language as a planning modality offers an intuitive and generalizable interface, mirroring how experienced surgeons instruct traineers during procedures. We validate our framework in ex-vivo experiments on a complex minimally invasive procedure, cholecystectomy, and conduct ablative studies to assess key design choices. Our approach achieves a 100% success rate across n=8 different ex-vivo gallbladders, operating fully autonomously without human intervention. The hierarchical approach greatly improves the policy's ability to recover from suboptimal states that are inevitable in the highly dynamic environment of realistic surgical applications. This work represents the first demonstration of step-level autonomy, marking a critical milestone toward autonomous surgical systems for clinical studies. By advancing generalizable autonomy in surgical robotics, our approach brings the field closer to real-world deployment.
TxGemma: Efficient and Agentic LLMs for Therapeutics
Apr 08, 2025Therapeutic development is a costly and high-risk endeavor that is often plagued by high failure rates. To address this, we introduce TxGemma, a suite of efficient, generalist large language models (LLMs) capable of therapeutic property prediction as well as interactive reasoning and explainability. Unlike task-specific models, TxGemma synthesizes information from diverse sources, enabling broad application across the therapeutic development pipeline. The suite includes 2B, 9B, and 27B parameter models, fine-tuned from Gemma-2 on a comprehensive dataset of small molecules, proteins, nucleic acids, diseases, and cell lines. Across 66 therapeutic development tasks, TxGemma achieved superior or comparable performance to the state-of-the-art generalist model on 64 (superior on 45), and against state-of-the-art specialist models on 50 (superior on 26). Fine-tuning TxGemma models on therapeutic downstream tasks, such as clinical trial adverse event prediction, requires less training data than fine-tuning base LLMs, making TxGemma suitable for data-limited applications. Beyond these predictive capabilities, TxGemma features conversational models that bridge the gap between general LLMs and specialized property predictors. These allow scientists to interact in natural language, provide mechanistic reasoning for predictions based on molecular structure, and engage in scientific discussions. Building on this, we further introduce Agentic-Tx, a generalist therapeutic agentic system powered by Gemini 2.5 that reasons, acts, manages diverse workflows, and acquires external domain knowledge. Agentic-Tx surpasses prior leading models on the Humanity's Last Exam benchmark (Chemistry & Biology) with 52.3% relative improvement over o3-mini (high) and 26.7% over o3-mini (high) on GPQA (Chemistry) and excels with improvements of 6.3% (ChemBench-Preference) and 2.4% (ChemBench-Mini) over o3-mini (high).
Surgical Gaussian Surfels: Highly Accurate Real-time Surgical Scene Rendering
Mar 06, 2025
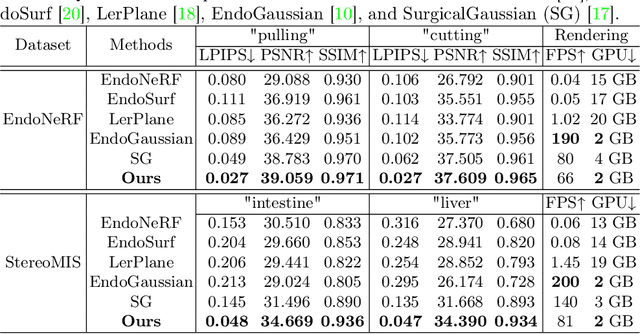

Accurate geometric reconstruction of deformable tissues in monocular endoscopic video remains a fundamental challenge in robot-assisted minimally invasive surgery. Although recent volumetric and point primitive methods based on neural radiance fields (NeRF) and 3D Gaussian primitives have efficiently rendered surgical scenes, they still struggle with handling artifact-free tool occlusions and preserving fine anatomical details. These limitations stem from unrestricted Gaussian scaling and insufficient surface alignment constraints during reconstruction. To address these issues, we introduce Surgical Gaussian Surfels (SGS), which transforms anisotropic point primitives into surface-aligned elliptical splats by constraining the scale component of the Gaussian covariance matrix along the view-aligned axis. We predict accurate surfel motion fields using a lightweight Multi-Layer Perceptron (MLP) coupled with locality constraints to handle complex tissue deformations. We use homodirectional view-space positional gradients to capture fine image details by splitting Gaussian Surfels in over-reconstructed regions. In addition, we define surface normals as the direction of the steepest density change within each Gaussian surfel primitive, enabling accurate normal estimation without requiring monocular normal priors. We evaluate our method on two in-vivo surgical datasets, where it outperforms current state-of-the-art methods in surface geometry, normal map quality, and rendering efficiency, while remaining competitive in real-time rendering performance. We make our code available at https://github.com/aloma85/SurgicalGaussianSurfels
Agent Laboratory: Using LLM Agents as Research Assistants
Jan 08, 2025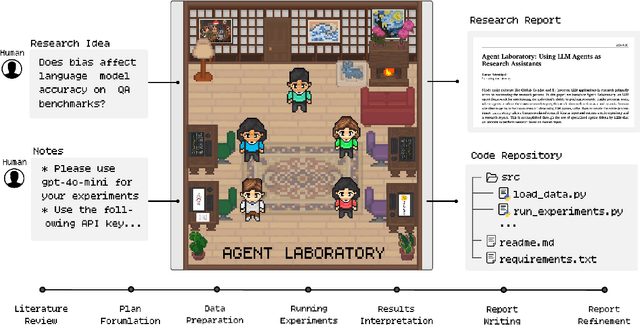



Historically, scientific discovery has been a lengthy and costly process, demanding substantial time and resources from initial conception to final results. To accelerate scientific discovery, reduce research costs, and improve research quality, we introduce Agent Laboratory, an autonomous LLM-based framework capable of completing the entire research process. This framework accepts a human-provided research idea and progresses through three stages--literature review, experimentation, and report writing to produce comprehensive research outputs, including a code repository and a research report, while enabling users to provide feedback and guidance at each stage. We deploy Agent Laboratory with various state-of-the-art LLMs and invite multiple researchers to assess its quality by participating in a survey, providing human feedback to guide the research process, and then evaluate the final paper. We found that: (1) Agent Laboratory driven by o1-preview generates the best research outcomes; (2) The generated machine learning code is able to achieve state-of-the-art performance compared to existing methods; (3) Human involvement, providing feedback at each stage, significantly improves the overall quality of research; (4) Agent Laboratory significantly reduces research expenses, achieving an 84% decrease compared to previous autonomous research methods. We hope Agent Laboratory enables researchers to allocate more effort toward creative ideation rather than low-level coding and writing, ultimately accelerating scientific discovery.
Tracking Tumors under Deformation from Partial Point Clouds using Occupancy Networks
Nov 04, 2024



To track tumors during surgery, information from preoperative CT scans is used to determine their position. However, as the surgeon operates, the tumor may be deformed which presents a major hurdle for accurately resecting the tumor, and can lead to surgical inaccuracy, increased operation time, and excessive margins. This issue is particularly pronounced in robot-assisted partial nephrectomy (RAPN), where the kidney undergoes significant deformations during operation. Toward addressing this, we introduce a occupancy network-based method for the localization of tumors within kidney phantoms undergoing deformations at interactive speeds. We validate our method by introducing a 3D hydrogel kidney phantom embedded with exophytic and endophytic renal tumors. It closely mimics real tissue mechanics to simulate kidney deformation during in vivo surgery, providing excellent contrast and clear delineation of tumor margins to enable automatic threshold-based segmentation. Our findings indicate that the proposed method can localize tumors in moderately deforming kidneys with a margin of 6mm to 10mm, while providing essential volumetric 3D information at over 60Hz. This capability directly enables downstream tasks such as robotic resection.
SurGen: Text-Guided Diffusion Model for Surgical Video Generation
Aug 26, 2024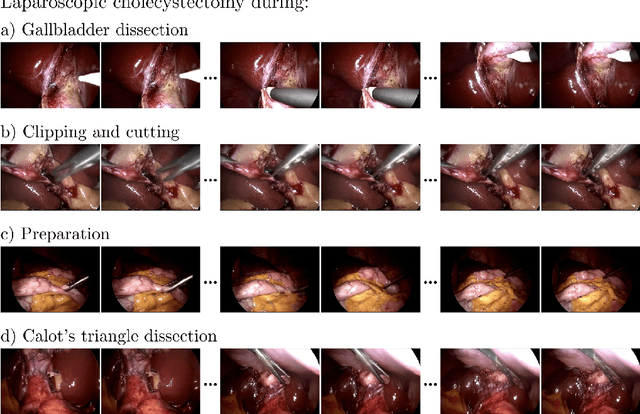
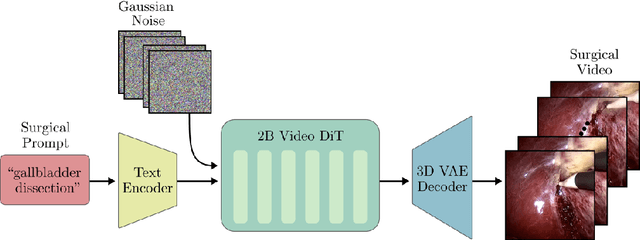
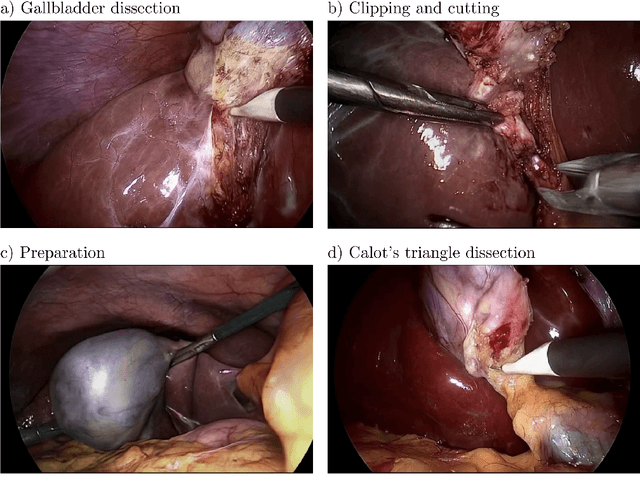

Diffusion-based video generation models have made significant strides, producing outputs with improved visual fidelity, temporal coherence, and user control. These advancements hold great promise for improving surgical education by enabling more realistic, diverse, and interactive simulation environments. In this study, we introduce SurGen, a text-guided diffusion model tailored for surgical video synthesis, producing the highest resolution and longest duration videos among existing surgical video generation models. We validate the visual and temporal quality of the outputs using standard image and video generation metrics. Additionally, we assess their alignment to the corresponding text prompts through a deep learning classifier trained on surgical data. Our results demonstrate the potential of diffusion models to serve as valuable educational tools for surgical trainees.
GP-VLS: A general-purpose vision language model for surgery
Jul 27, 2024Surgery requires comprehensive medical knowledge, visual assessment skills, and procedural expertise. While recent surgical AI models have focused on solving task-specific problems, there is a need for general-purpose systems that can understand surgical scenes and interact through natural language. This paper introduces GP-VLS, a general-purpose vision language model for surgery that integrates medical and surgical knowledge with visual scene understanding. For comprehensively evaluating general-purpose surgical models, we propose SurgiQual, which evaluates across medical and surgical knowledge benchmarks as well as surgical vision-language questions. To train GP-VLS, we develop six new datasets spanning medical knowledge, surgical textbooks, and vision-language pairs for tasks like phase recognition and tool identification. We show that GP-VLS significantly outperforms existing open- and closed-source models on surgical vision-language tasks, with 8-21% improvements in accuracy across SurgiQual benchmarks. GP-VLS also demonstrates strong performance on medical and surgical knowledge tests compared to open-source alternatives. Overall, GP-VLS provides an open-source foundation for developing AI assistants to support surgeons across a wide range of tasks and scenarios.
Surgical Robot Transformer (SRT): Imitation Learning for Surgical Tasks
Jul 17, 2024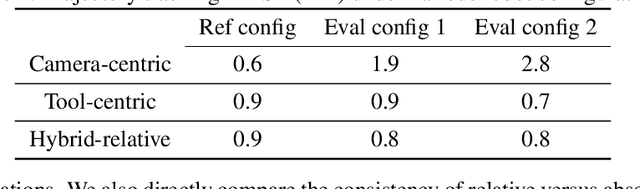
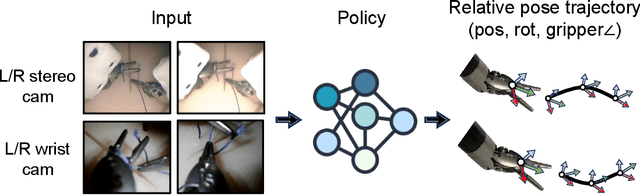
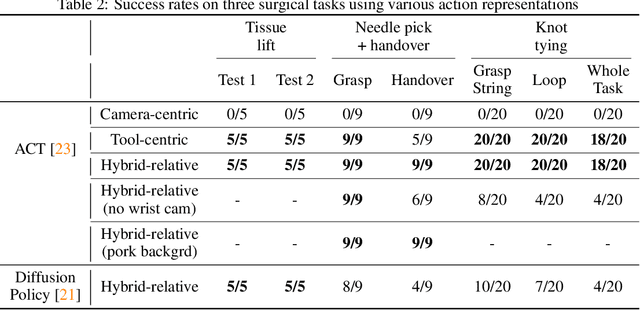
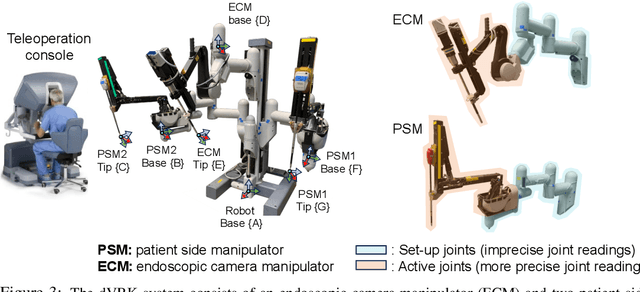
We explore whether surgical manipulation tasks can be learned on the da Vinci robot via imitation learning. However, the da Vinci system presents unique challenges which hinder straight-forward implementation of imitation learning. Notably, its forward kinematics is inconsistent due to imprecise joint measurements, and naively training a policy using such approximate kinematics data often leads to task failure. To overcome this limitation, we introduce a relative action formulation which enables successful policy training and deployment using its approximate kinematics data. A promising outcome of this approach is that the large repository of clinical data, which contains approximate kinematics, may be directly utilized for robot learning without further corrections. We demonstrate our findings through successful execution of three fundamental surgical tasks, including tissue manipulation, needle handling, and knot-tying.