 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurGen: Text-Guided Diffusion Model for Surgical Video Generation
Aug 26, 2024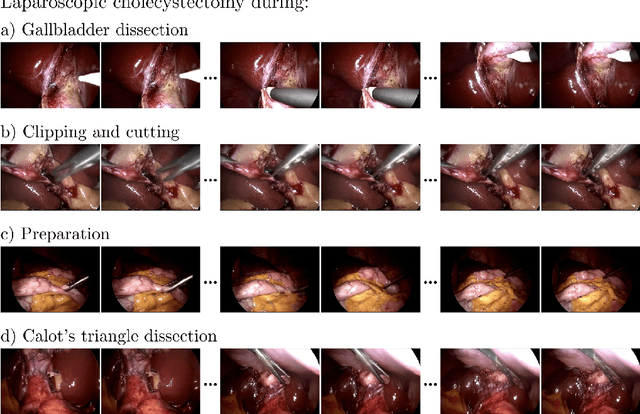
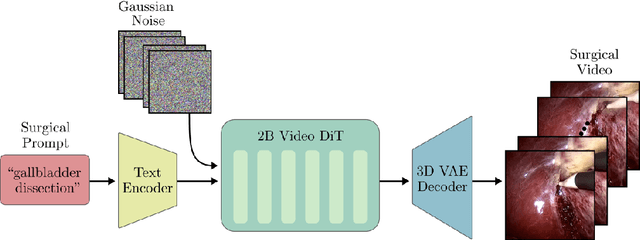
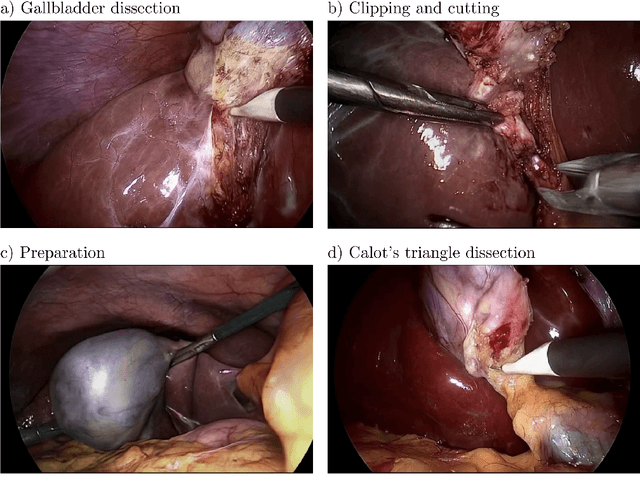

Diffusion-based video generation models have made significant strides, producing outputs with improved visual fidelity, temporal coherence, and user control. These advancements hold great promise for improving surgical education by enabling more realistic, diverse, and interactive simulation environments. In this study, we introduce SurGen, a text-guided diffusion model tailored for surgical video synthesis, producing the highest resolution and longest duration videos among existing surgical video generation models. We validate the visual and temporal quality of the outputs using standard image and video generation metrics. Additionally, we assess their alignment to the corresponding text prompts through a deep learning classifier trained on surgical data. Our results demonstrate the potential of diffusion models to serve as valuable educational tools for surgical trainees.
GP-VLS: A general-purpose vision language model for surgery
Jul 27, 2024Surgery requires comprehensive medical knowledge, visual assessment skills, and procedural expertise. While recent surgical AI models have focused on solving task-specific problems, there is a need for general-purpose systems that can understand surgical scenes and interact through natural language. This paper introduces GP-VLS, a general-purpose vision language model for surgery that integrates medical and surgical knowledge with visual scene understanding. For comprehensively evaluating general-purpose surgical models, we propose SurgiQual, which evaluates across medical and surgical knowledge benchmarks as well as surgical vision-language questions. To train GP-VLS, we develop six new datasets spanning medical knowledge, surgical textbooks, and vision-language pairs for tasks like phase recognition and tool identification. We show that GP-VLS significantly outperforms existing open- and closed-source models on surgical vision-language tasks, with 8-21% improvements in accuracy across SurgiQual benchmarks. GP-VLS also demonstrates strong performance on medical and surgical knowledge tests compared to open-source alternatives. Overall, GP-VLS provides an open-source foundation for developing AI assistants to support surgeons across a wide range of tasks and scenarios.
MediSyn: Text-Guided Diffusion Models for Broad Medical 2D and 3D Image Synthesis
May 16, 2024Diffusion models have recently gained significant traction due to their ability to generate high-fidelity and diverse images and videos conditioned on text prompts. In medicine, this application promises to address the critical challenge of data scarcity, a consequence of barriers in data sharing, stringent patient privacy regulations, and disparities in patient population and demographics. By generating realistic and varying medical 2D and 3D images, these models offer a rich, privacy-respecting resource for algorithmic training and research. To this end, we introduce MediSyn, a pair of instruction-tuned text-guided latent diffusion models with the ability to generate high-fidelity and diverse medical 2D and 3D images across specialties and modalities. Through established metrics, we show significant improvement in broad medical image and video synthesis guided by text prompts.
Almanac Copilot: Towards Autonomous Electronic Health Record Navigation
May 14, 2024



Clinicians spend large amounts of time on clinical documentation, and inefficiencies impact quality of care and increase clinician burnout. Despite the promise of electronic medical records (EMR), the transition from paper-based records has been negatively associated with clinician wellness, in part due to poor user experience, increased burden of documentation, and alert fatigue. In this study, we present Almanac Copilot, an autonomous agent capable of assisting clinicians with EMR-specific tasks such as information retrieval and order placement. On EHR-QA, a synthetic evaluation dataset of 300 common EHR queries based on real patient data, Almanac Copilot obtains a successful task completion rate of 74% (n = 221 tasks) with a mean score of 2.45 over 3 (95% CI:2.34-2.56). By automating routine tasks and streamlining the documentation process, our findings highlight the significant potential of autonomous agents to mitigate the cognitive load imposed on clinicians by current EMR systems.
Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
Mar 08, 2024


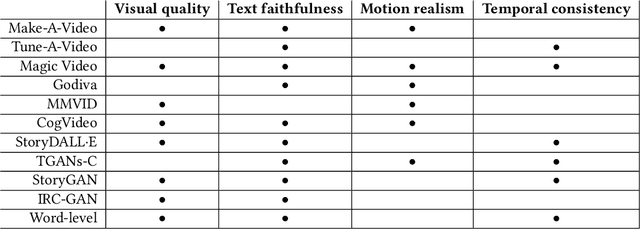
Text-to-video generation marks a significant frontier in the rapidly evolving domain of generative AI, integrating advancements in text-to-image synthesis, video captioning, and text-guided editing. This survey critically examines the progression of text-to-video technologies, focusing on the shift from traditional generative models to the cutting-edge Sora model, highlighting developments in scalability and generalizability. Distinguishing our analysis from prior works, we offer an in-depth exploration of the technological frameworks and evolutionary pathways of these models. Additionally, we delve into practical applications and address ethical and technological challenges such as the inability to perform multiple entity handling, comprehend causal-effect learning, understand physical interaction, perceive object scaling and proportioning, and combat object hallucination which is also a long-standing problem in generative models. Our comprehensive discussion covers the topic of enablement of text-to-video generation models as human-assistive tools and world models, as well as eliciting model's shortcomings and summarizing future improvement direction that mainly centers around training datasets and evaluation metrics (both automatic and human-centered). Aimed at both newcomers and seasoned researchers, this survey seeks to catalyze further innovation and discussion in the growing field of text-to-video generation, paving the way for more reliable and practical generative artificial intelligence technologies.