 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMLPA: Language Model Linguistic Personality Assessment
Oct 23, 2024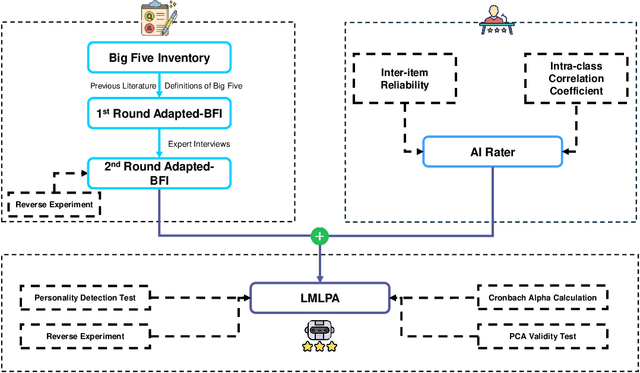


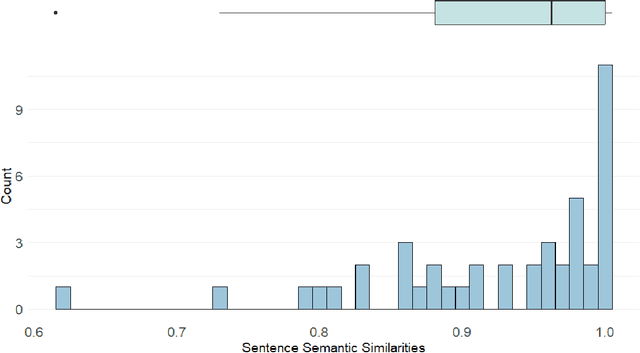
Large Language Models (LLMs) are increasingly used in everyday life and research. One of the most common use cases is conversational interactions, enabled by the language generation capabilities of LLMs. Just as between two humans, a conversation between an LLM-powered entity and a human depends on the personality of the conversants. However, measuring the personality of a given LLM is currently a challenge. This paper introduces the Language Model Linguistic Personality Assessment (LMLPA), a system designed to evaluate the linguistic personalities of LLMs. Our system helps to understand LLMs' language generation capabilities by quantitatively assessing the distinct personality traits reflected in their linguistic outputs. Unlike traditional human-centric psychometrics, the LMLPA adapts a personality assessment questionnaire, specifically the Big Five Inventory, to align with the operational capabilities of LLMs, and also incorporates the findings from previous language-based personality measurement literature. To mitigate sensitivity to the order of options, our questionnaire is designed to be open-ended, resulting in textual answers. Thus, the AI rater is needed to transform ambiguous personality information from text responses into clear numerical indicators of personality traits. Utilising Principal Component Analysis and reliability validations, our findings demonstrate that LLMs possess distinct personality traits that can be effectively quantified by the LMLPA. This research contributes to Human-Computer Interaction and Human-Centered AI, providing a robust framework for future studies to refine AI personality assessments and expand their applications in multiple areas, including education and manufacturing.
Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
Mar 08, 2024


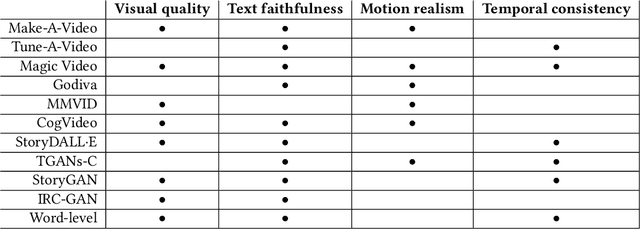
Text-to-video generation marks a significant frontier in the rapidly evolving domain of generative AI, integrating advancements in text-to-image synthesis, video captioning, and text-guided editing. This survey critically examines the progression of text-to-video technologies, focusing on the shift from traditional generative models to the cutting-edge Sora model, highlighting developments in scalability and generalizability. Distinguishing our analysis from prior works, we offer an in-depth exploration of the technological frameworks and evolutionary pathways of these models. Additionally, we delve into practical applications and address ethical and technological challenges such as the inability to perform multiple entity handling, comprehend causal-effect learning, understand physical interaction, perceive object scaling and proportioning, and combat object hallucination which is also a long-standing problem in generative models. Our comprehensive discussion covers the topic of enablement of text-to-video generation models as human-assistive tools and world models, as well as eliciting model's shortcomings and summarizing future improvement direction that mainly centers around training datasets and evaluation metrics (both automatic and human-centered). Aimed at both newcomers and seasoned researchers, this survey seeks to catalyze further innovation and discussion in the growing field of text-to-video generation, paving the way for more reliable and practical generative artificial intelligence technologies.
Promptor: A Conversational and Autonomous Prompt Generation Agent for Intelligent Text Entry Techniques
Oct 15, 2023Text entry is an essential task in our day-to-day digital interactions. Numerous intelligent features have been developed to streamline this process, making text entry more effective, efficient, and fluid. These improvements include sentence prediction and user personalization. However, as deep learning-based language models become the norm for these advanced features, the necessity for data collection and model fine-tuning increases. These challenges can be mitigated by harnessing the in-context learning capability of large language models such as GPT-3.5. This unique feature allows the language model to acquire new skills through prompts, eliminating the need for data collection and fine-tuning. Consequently, large language models can learn various text prediction techniques. We initially showed that, for a sentence prediction task, merely prompting GPT-3.5 surpassed a GPT-2 backed system and is comparable with a fine-tuned GPT-3.5 model, with the latter two methods requiring costly data collection, fine-tuning and post-processing. However, the task of prompting large language models to specialize in specific text prediction tasks can be challenging, particularly for designers without expertise in prompt engineering. To address this, we introduce Promptor, a conversational prompt generation agent designed to engage proactively with designers. Promptor can automatically generate complex prompts tailored to meet specific needs, thus offering a solution to this challenge. We conducted a user study involving 24 participants creating prompts for three intelligent text entry tasks, half of the participants used Promptor while the other half designed prompts themselves. The results show that Promptor-designed prompts result in a 35% increase in similarity and 22% in coherence over those by designers.
Dual Ask-Answer Network for Machine Reading Comprehension
Sep 10, 2018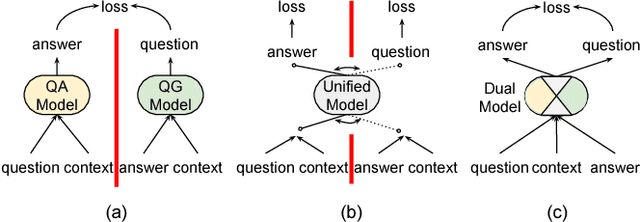
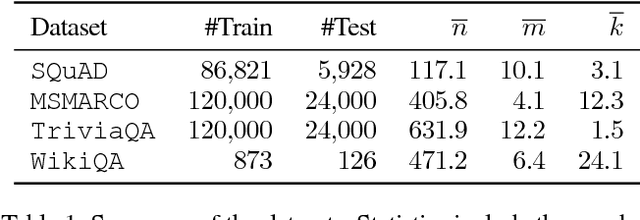
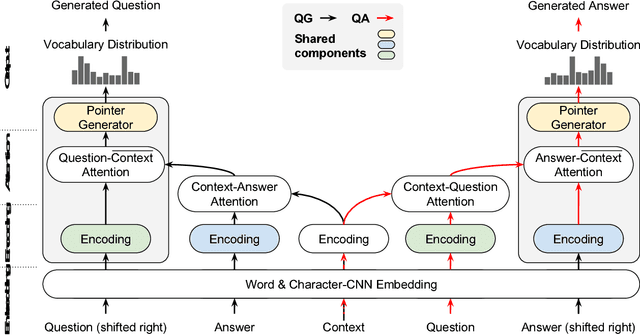
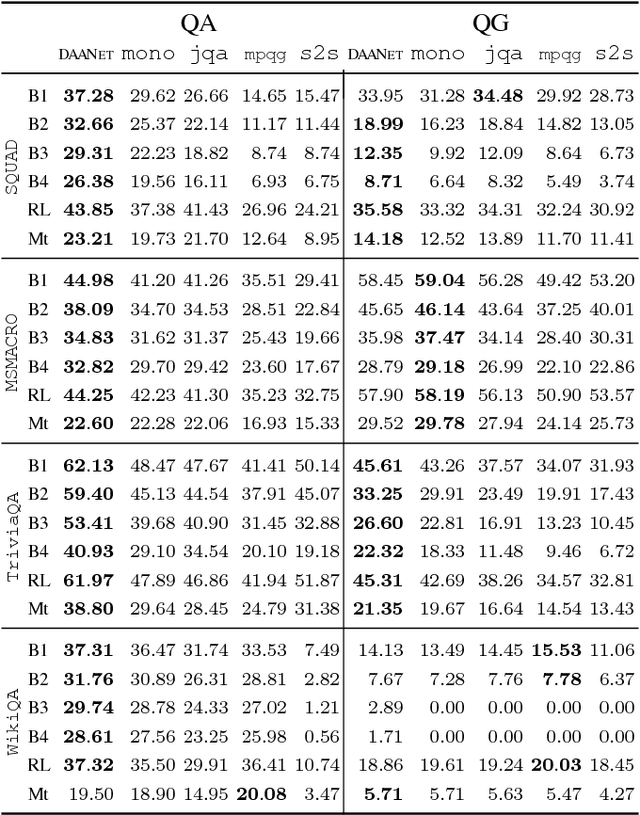
There are three modalities in the reading comprehension setting: question, answer and context. The task of question answering or question generation aims to infer an answer or a question when given the counterpart based on context. We present a novel two-way neural sequence transduction model that connects three modalities, allowing it to learn two tasks simultaneously and mutually benefit one another. During training, the model receives question-context-answer triplets as input and captures the cross-modal interaction via a hierarchical attention process. Unlike previous joint learning paradigms that leverage the duality of question generation and question answering at data level, we solve such dual tasks at the architecture level by mirroring the network structure and partially sharing components at different layers. This enables the knowledge to be transferred from one task to another, helping the model to find a general representation for each modality. The evaluation on four public datasets shows that our dual-learning model outperforms the mono-learning counterpart as well as the state-of-the-art joint models on both question answering and question generation tasks.