 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialMem: Unified 3D Memory with Metric Anchoring and Fast Retrieval
Jan 21, 2026We present SpatialMem, a memory-centric system that unifies 3D geometry, semantics, and language into a single, queryable representation. Starting from casually captured egocentric RGB video, SpatialMem reconstructs metrically scaled indoor environments, detects structural 3D anchors (walls, doors, windows) as the first-layer scaffold, and populates a hierarchical memory with open-vocabulary object nodes -- linking evidence patches, visual embeddings, and two-layer textual descriptions to 3D coordinates -- for compact storage and fast retrieval. This design enables interpretable reasoning over spatial relations (e.g., distance, direction, visibility) and supports downstream tasks such as language-guided navigation and object retrieval without specialized sensors. Experiments across three real-life indoor scenes demonstrate that SpatialMem maintains strong anchor-description-level navigation completion and hierarchical retrieval accuracy under increasing clutter and occlusion, offering an efficient and extensible framework for embodied spatial intelligence.
CAMP-VQA: Caption-Embedded Multimodal Perception for No-Reference Quality Assessment of Compressed Video
Nov 10, 2025The prevalence of user-generated content (UGC) on platforms such as YouTube and TikTok has rendered no-reference (NR) perceptual video quality assessment (VQA) vital for optimizing video delivery. Nonetheless, the characteristics of non-professional acquisition and the subsequent transcoding of UGC video on sharing platforms present significant challenges for NR-VQA. Although NR-VQA models attempt to infer mean opinion scores (MOS), their modeling of subjective scores for compressed content remains limited due to the absence of fine-grained perceptual annotations of artifact types. To address these challenges, we propose CAMP-VQA, a novel NR-VQA framework that exploits the semantic understanding capabilities of large vision-language models. Our approach introduces a quality-aware prompting mechanism that integrates video metadata (e.g., resolution, frame rate, bitrate) with key fragments extracted from inter-frame variations to guide the BLIP-2 pretraining approach in generating fine-grained quality captions. A unified architecture has been designed to model perceptual quality across three dimensions: semantic alignment, temporal characteristics, and spatial characteristics. These multimodal features are extracted and fused, then regressed to video quality scores. Extensive experiments on a wide variety of UGC datasets demonstrate that our model consistently outperforms existing NR-VQA methods, achieving improved accuracy without the need for costly manual fine-grained annotations. Our method achieves the best performance in terms of average rank and linear correlation (SRCC: 0.928, PLCC: 0.938) compared to state-of-the-art methods. The source code and trained models, along with a user-friendly demo, are available at: https://github.com/xinyiW915/CAMP-VQA.
MARC: Memory-Augmented RL Token Compression for Efficient Video Understanding
Oct 09, 2025The rapid progress of large language models (LLMs) has laid the foundation for multimodal models. However, visual language models (VLMs) still face heavy computational costs when extended from images to videos due to high frame rates and long durations. Token compression is a promising solution, yet most existing training-free methods cause information loss and performance degradation. To overcome this, we propose \textbf{Memory-Augmented Reinforcement Learning-based Token Compression (MARC)}, which integrates structured retrieval and RL-based distillation. MARC adopts a \textit{retrieve-then-compress} strategy using a \textbf{Visual Memory Retriever (VMR)} to select key clips and a \textbf{Compression Group Relative Policy Optimization (C-GRPO)} framework to distil reasoning ability from a teacher to a student model. Experiments on six video benchmarks show that MARC achieves near-baseline accuracy using only one frame's tokens -- reducing visual tokens by \textbf{95\%}, GPU memory by \textbf{72\%}, and latency by \textbf{23.9\%}. This demonstrates its potential for efficient, real-time video understanding in resource-constrained settings such as video QA, surveillance, and autonomous driving.
ST-Think: How Multimodal Large Language Models Reason About 4D Worlds from Ego-Centric Videos
Mar 16, 2025Humans excel at spatio-temporal reasoning, effortlessly interpreting dynamic visual events from an egocentric viewpoint. However, whether multimodal large language models (MLLMs) can similarly comprehend the 4D world remains uncertain. This paper explores multimodal spatio-temporal reasoning from an egocentric perspective, aiming to equip MLLMs with human-like reasoning capabilities. To support this objective, we introduce Ego-ST Bench, a novel benchmark containing over 5,000 question-answer pairs across four categories, systematically evaluating spatial, temporal, and integrated spatio-temporal reasoning. Additionally, we propose the ST-R1 Video model, a video-based reasoning model that incorporates reverse thinking into its reinforcement learning process, significantly enhancing performance. We combine long-chain-of-thought (long-CoT) supervised fine-tuning with Group Relative Policy Optimization (GRPO) reinforcement learning, achieving notable improvements with limited high-quality data. Ego-ST Bench and ST-R1 provide valuable insights and resources for advancing video-based spatio-temporal reasoning research.
VideoMAP: Toward Scalable Mamba-based Video Autoregressive Pretraining
Mar 16, 2025Recent Mamba-based architectures for video understanding demonstrate promising computational efficiency and competitive performance, yet struggle with overfitting issues that hinder their scalability. To overcome this challenge, we introduce VideoMAP, a Hybrid Mamba-Transformer framework featuring a novel pre-training approach. VideoMAP uses a 4:1 Mamba-to-Transformer ratio, effectively balancing computational cost and model capacity. This architecture, combined with our proposed frame-wise masked autoregressive pre-training strategy, delivers significant performance gains when scaling to larger models. Additionally, VideoMAP exhibits impressive sample efficiency, significantly outperforming existing methods with less training data. Experiments show that VideoMAP outperforms existing models across various datasets, including Kinetics-400, Something-Something V2, Breakfast, and COIN. Furthermore, we demonstrate the potential of VideoMAP as a visual encoder for multimodal large language models, highlighting its ability to reduce memory usage and enable the processing of longer video sequences. The code is open-source at https://github.com/yunzeliu/MAP
AutoMR: A Universal Time Series Motion Recognition Pipeline
Feb 21, 2025
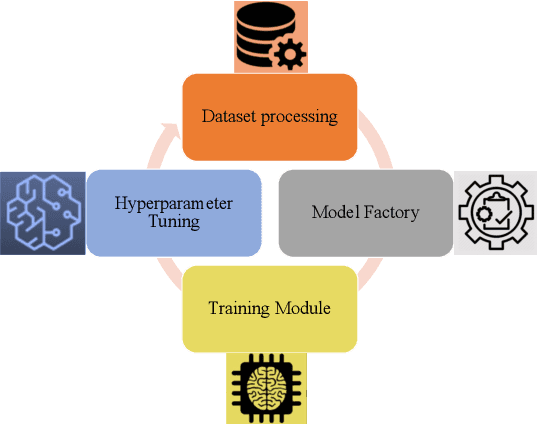
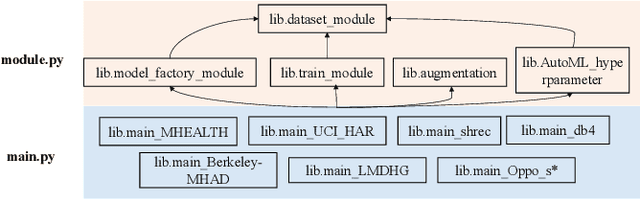
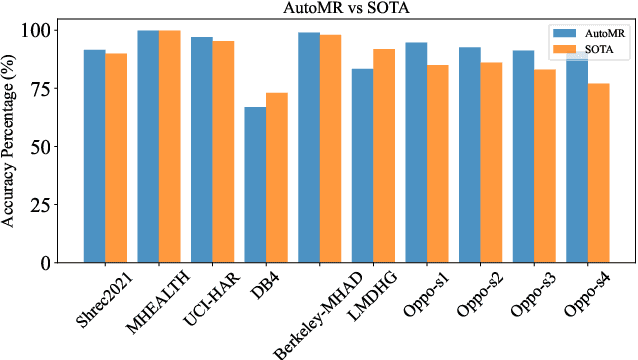
In this paper, we present an end-to-end automated motion recognition (AutoMR) pipeline designed for multimodal datasets. The proposed framework seamlessly integrates data preprocessing, model training, hyperparameter tuning, and evaluation, enabling robust performance across diverse scenarios. Our approach addresses two primary challenges: 1) variability in sensor data formats and parameters across datasets, which traditionally requires task-specific machine learning implementations, and 2) the complexity and time consumption of hyperparameter tuning for optimal model performance. Our library features an all-in-one solution incorporating QuartzNet as the core model, automated hyperparameter tuning, and comprehensive metrics tracking. Extensive experiments demonstrate its effectiveness on 10 diverse datasets, achieving state-of-the-art performance. This work lays a solid foundation for deploying motion-capture solutions across varied real-world applications.
Duo Streamers: A Streaming Gesture Recognition Framework
Feb 17, 2025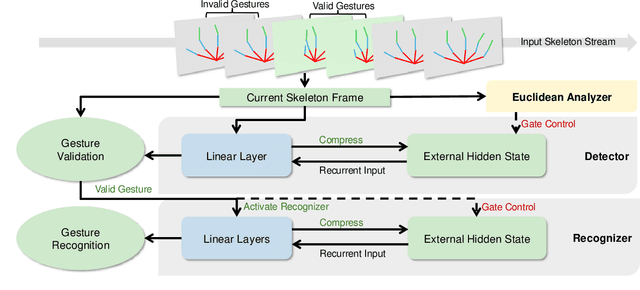
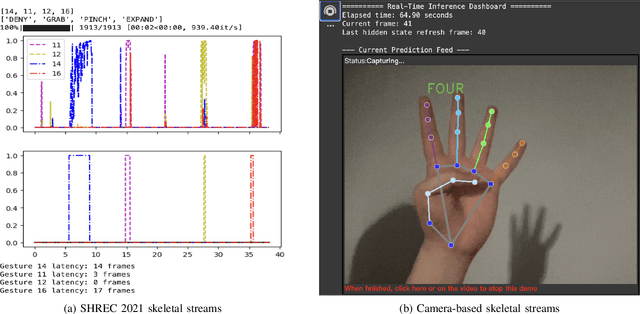
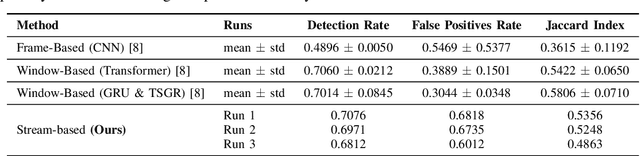

Gesture recognition in resource-constrained scenarios faces significant challenges in achieving high accuracy and low latency. The streaming gesture recognition framework, Duo Streamers, proposed in this paper, addresses these challenges through a three-stage sparse recognition mechanism, an RNN-lite model with an external hidden state, and specialized training and post-processing pipelines, thereby making innovative progress in real-time performance and lightweight design. Experimental results show that Duo Streamers matches mainstream methods in accuracy metrics, while reducing the real-time factor by approximately 92.3%, i.e., delivering a nearly 13-fold speedup. In addition, the framework shrinks parameter counts to 1/38 (idle state) and 1/9 (busy state) compared to mainstream models. In summary, Duo Streamers not only offers an efficient and practical solution for streaming gesture recognition in resource-constrained devices but also lays a solid foundation for extended applications in multimodal and diverse scenarios.
X-LeBench: A Benchmark for Extremely Long Egocentric Video Understanding
Jan 12, 2025Long-form egocentric video understanding provides rich contextual information and unique insights into long-term human behaviors, holding significant potential for applications in embodied intelligence, long-term activity analysis, and personalized assistive technologies. However, existing benchmark datasets primarily focus on single, short-duration videos or moderately long videos up to dozens of minutes, leaving a substantial gap in evaluating extensive, ultra-long egocentric video recordings. To address this, we introduce X-LeBench, a novel benchmark dataset specifically crafted for evaluating tasks on extremely long egocentric video recordings. Leveraging the advanced text processing capabilities of large language models (LLMs), X-LeBench develops a life-logging simulation pipeline that produces realistic, coherent daily plans aligned with real-world video data. This approach enables the flexible integration of synthetic daily plans with real-world footage from Ego4D-a massive-scale egocentric video dataset covers a wide range of daily life scenarios-resulting in 432 simulated video life logs that mirror realistic daily activities in contextually rich scenarios. The video life-log durations span from 23 minutes to 16.4 hours. The evaluation of several baseline systems and multimodal large language models (MLLMs) reveals their poor performance across the board, highlighting the inherent challenges of long-form egocentric video understanding and underscoring the need for more advanced models.
CULTURE3D: Cultural Landmarks and Terrain Dataset for 3D Applications
Jan 12, 2025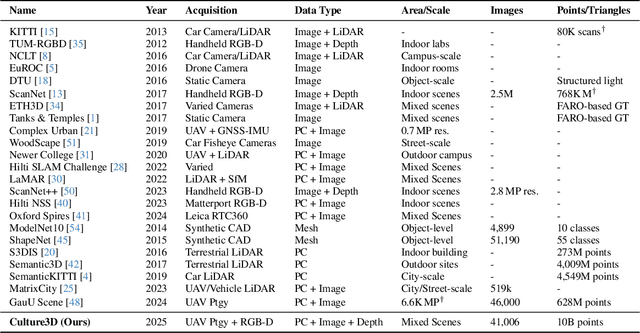
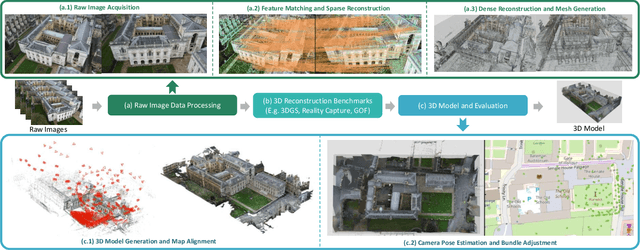
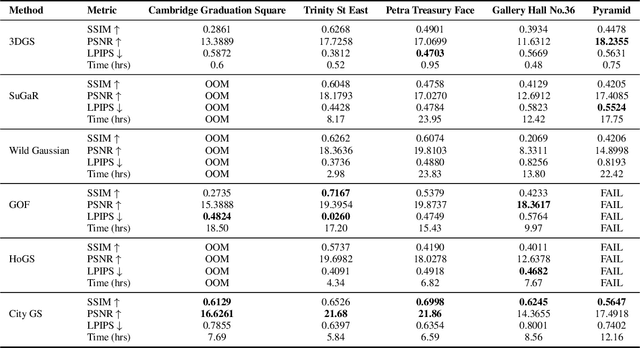

In this paper, we present a large-scale fine-grained dataset using high-resolution images captured from locations worldwide. Compared to existing datasets, our dataset offers a significantly larger size and includes a higher level of detail, making it uniquely suited for fine-grained 3D applications. Notably, our dataset is built using drone-captured aerial imagery, which provides a more accurate perspective for capturing real-world site layouts and architectural structures. By reconstructing environments with these detailed images, our dataset supports applications such as the COLMAP format for Gaussian Splatting and the Structure-from-Motion (SfM) method. It is compatible with widely-used techniques including SLAM, Multi-View Stereo, and Neural Radiance Fields (NeRF), enabling accurate 3D reconstructions and point clouds. This makes it a benchmark for reconstruction and segmentation tasks. The dataset enables seamless integration with multi-modal data, supporting a range of 3D applications, from architectural reconstruction to virtual tourism. Its flexibility promotes innovation, facilitating breakthroughs in 3D modeling and analysis.
Lucia: A Temporal Computing Platform for Contextual Intelligence
Nov 19, 2024The rapid evolution of artificial intelligence, especially through multi-modal large language models, has redefined user interactions, enabling responses that are contextually rich and human-like. As AI becomes an integral part of daily life, a new frontier has emerged: developing systems that not only understand spatial and sensory data but also interpret temporal contexts to build long-term, personalized memories. This report introduces Lucia, an open-source Temporal Computing Platform designed to enhance human cognition by capturing and utilizing continuous contextual memory. Lucia introduces a lightweight, wearable device that excels in both comfort and real-time data accessibility, distinguishing itself from existing devices that typically prioritize either wearability or perceptual capabilities alone. By recording and interpreting daily activities over time, Lucia enables users to access a robust temporal memory, enhancing cognitive processes such as decision-making and memory recall.