 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interactive Video World Modeling: Frontiers, Challenges, Benchmarks, and Future Trends
May 31, 2026With rapid development of large language models and diffusion-based content generation, world modeling has attracted increasing research attention, benefiting various downstream domains such as game engines, embodied AI, autonomous driving, etc. Through explicitly incorporating user actions into world state transition, recent literature empowers world modeling with interactivity in an action-conditioned video or 3D generation paradigm, further enhancing controllability over world evolutions and facilitating users to freely traverse, manipulate, navigate, and personalize the state evolution. In this paper, we aim to systematically review recent research trends, technical developments, evaluation benchmarks, and also propose future potential directions in interactive world modeling. Specifically, we first summarize recent efforts and trends in terms of application scenarios, world state evolution, and scene modality. Afterwards, we delve into three crucial technical challenges, including action-conditioned controllability, long-horizon interactions and memory, and action-following responsiveness for real-time interactivity. Furthermore, we also thoroughly compare existing benchmarks and metrics in four specific application fields: open-world exploration, game engine, autonomous driving, and robotics. Finally, we discuss several promising future directions in achieving next-generation interactive world modeling. The corresponding repository is publicly available at: https://github.com/liujiuming123/Awesome-Interactive-World-Model.
MyoInteract: A Framework for Fast Prototyping of Biomechanical HCI Tasks using Reinforcement Learning
Feb 16, 2026Reinforcement learning (RL)-based biomechanical simulations have the potential to revolutionise HCI research and interaction design, but currently lack usability and interpretability. Using the Human Action Cycle as a design lens, we identify key limitations of biomechanical RL frameworks and develop MyoInteract, a novel framework for fast prototyping of biomechanical HCI tasks. MyoInteract allows designers to setup tasks, user models, and training parameters from an easy-to-use GUI within minutes. It trains and evaluates muscle-actuated simulated users within minutes, reducing training times by up to 98%. A workshop study with 12 interaction designers revealed that MyoInteract allowed novices in biomechanical RL to successfully setup, train, and assess goal-directed user movements within a single session. By transforming biomechanical RL from a days-long expert task into an accessible hour-long workflow, this work significantly lowers barriers to entry and accelerates iteration cycles in HCI biomechanics research.
Cost-Aware Bayesian Optimization for Prototyping Interactive Devices
Feb 02, 2026Deciding which idea is worth prototyping is a central concern in iterative design. A prototype should be produced when the expected improvement is high and the cost is low. However, this is hard to decide, because costs can vary drastically: a simple parameter tweak may take seconds, while fabricating hardware consumes material and energy. Such asymmetries, can discourage a designer from exploring the design space. In this paper, we present an extension of cost-aware Bayesian optimization to account for diverse prototyping costs. The method builds on the power of Bayesian optimization and requires only a minimal modification to the acquisition function. The key idea is to use designer-estimated costs to guide sampling toward more cost-effective prototypes. In technical evaluations, the method achieved comparable utility to a cost-agnostic baseline while requiring only ${\approx}70\%$ of the cost; under strict budgets, it outperformed the baseline threefold. A within-subjects study with 12 participants in a realistic joystick design task demonstrated similar benefits. These results show that accounting for prototyping costs can make Bayesian optimization more compatible with real-world design projects.
ImageTalk: Designing a Multimodal AAC Text Generation System Driven by Image Recognition and Natural Language Generation
Dec 10, 2025People living with Motor Neuron Disease (plwMND) frequently encounter speech and motor impairments that necessitate a reliance on augmentative and alternative communication (AAC) systems. This paper tackles the main challenge that traditional symbol-based AAC systems offer a limited vocabulary, while text entry solutions tend to exhibit low communication rates. To help plwMND articulate their needs about the system efficiently and effectively, we iteratively design and develop a novel multimodal text generation system called ImageTalk through a tailored proxy-user-based and an end-user-based design phase. The system demonstrates pronounced keystroke savings of 95.6%, coupled with consistent performance and high user satisfaction. We distill three design guidelines for AI-assisted text generation systems design and outline four user requirement levels tailored for AAC purposes, guiding future research in this field.
X-LeBench: A Benchmark for Extremely Long Egocentric Video Understanding
Jan 12, 2025Long-form egocentric video understanding provides rich contextual information and unique insights into long-term human behaviors, holding significant potential for applications in embodied intelligence, long-term activity analysis, and personalized assistive technologies. However, existing benchmark datasets primarily focus on single, short-duration videos or moderately long videos up to dozens of minutes, leaving a substantial gap in evaluating extensive, ultra-long egocentric video recordings. To address this, we introduce X-LeBench, a novel benchmark dataset specifically crafted for evaluating tasks on extremely long egocentric video recordings. Leveraging the advanced text processing capabilities of large language models (LLMs), X-LeBench develops a life-logging simulation pipeline that produces realistic, coherent daily plans aligned with real-world video data. This approach enables the flexible integration of synthetic daily plans with real-world footage from Ego4D-a massive-scale egocentric video dataset covers a wide range of daily life scenarios-resulting in 432 simulated video life logs that mirror realistic daily activities in contextually rich scenarios. The video life-log durations span from 23 minutes to 16.4 hours. The evaluation of several baseline systems and multimodal large language models (MLLMs) reveals their poor performance across the board, highlighting the inherent challenges of long-form egocentric video understanding and underscoring the need for more advanced models.
Human-inspired Perspectives: A Survey on AI Long-term Memory
Nov 01, 2024


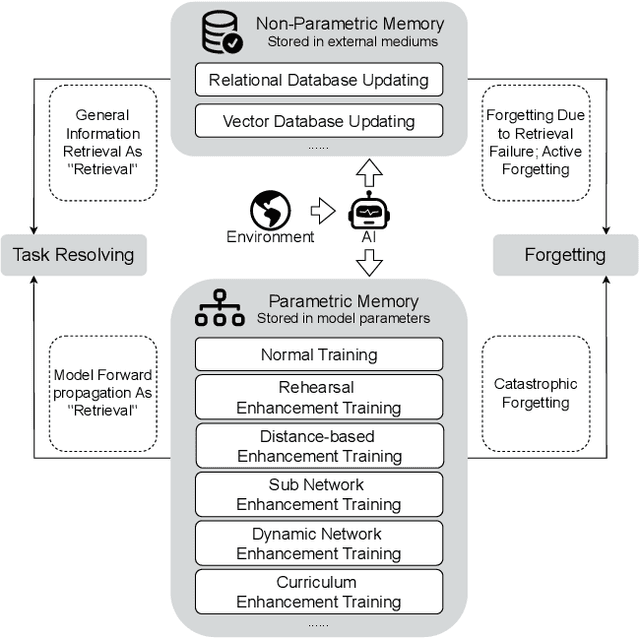
With the rapid advancement of AI systems, their abilities to store, retrieve, and utilize information over the long term - referred to as long-term memory - have become increasingly significant. These capabilities are crucial for enhancing the performance of AI systems across a wide range of tasks. However, there is currently no comprehensive survey that systematically investigates AI's long-term memory capabilities, formulates a theoretical framework, and inspires the development of next-generation AI long-term memory systems. This paper begins by systematically introducing the mechanisms of human long-term memory, then explores AI long-term memory mechanisms, establishing a mapping between the two. Based on the mapping relationships identified, we extend the current cognitive architectures and propose the Cognitive Architecture of Self-Adaptive Long-term Memory (SALM). SALM provides a theoretical framework for the practice of AI long-term memory and holds potential for guiding the creation of next-generation long-term memory driven AI systems. Finally, we delve into the future directions and application prospects of AI long-term memory.
Generative AI for Accessible and Inclusive Extended Reality
Oct 31, 2024Artificial Intelligence-Generated Content (AIGC) has the potential to transform how people build and interact with virtual environments. Within this paper, we discuss potential benefits but also challenges that AIGC has for the creation of inclusive and accessible virtual environments. Specifically, we touch upon the decreased need for 3D modeling expertise, benefits of symbolic-only as well as multimodal input, 3D content editing, and 3D model accessibility as well as foundation model-specific challenges.
Analyzing Multimodal Interaction Strategies for LLM-Assisted Manipulation of 3D Scenes
Oct 29, 2024



As more applications of large language models (LLMs) for 3D content for immersive environments emerge, it is crucial to study user behaviour to identify interaction patterns and potential barriers to guide the future design of immersive content creation and editing systems which involve LLMs. In an empirical user study with 12 participants, we combine quantitative usage data with post-experience questionnaire feedback to reveal common interaction patterns and key barriers in LLM-assisted 3D scene editing systems. We identify opportunities for improving natural language interfaces in 3D design tools and propose design recommendations for future LLM-integrated 3D content creation systems. Through an empirical study, we demonstrate that LLM-assisted interactive systems can be used productively in immersive environments.
Large Language Model-assisted Speech and Pointing Benefits Multiple 3D Object Selection in Virtual Reality
Oct 28, 2024Selection of occluded objects is a challenging problem in virtual reality, even more so if multiple objects are involved. With the advent of new artificial intelligence technologies, we explore the possibility of leveraging large language models to assist multi-object selection tasks in virtual reality via a multimodal speech and raycast interaction technique. We validate the findings in a comparative user study (n=24), where participants selected target objects in a virtual reality scene with different levels of scene perplexity. The performance metrics and user experience metrics are compared against a mini-map based occluded object selection technique that serves as the baseline. Results indicate that the introduced technique, AssistVR, outperforms the baseline technique when there are multiple target objects. Contrary to the common belief for speech interfaces, AssistVR was able to outperform the baseline even when the target objects were difficult to reference verbally. This work demonstrates the viability and interaction potential of an intelligent multimodal interactive system powered by large laguage models. Based on the results, we discuss the implications for design of future intelligent multimodal interactive systems in immersive environments.
Swarm manipulation: An efficient and accurate technique for multi-object manipulation in virtual reality
Oct 24, 2024The theory of swarm control shows promise for controlling multiple objects, however, scalability is hindered by cost constraints, such as hardware and infrastructure. Virtual Reality (VR) can overcome these limitations, but research on swarm interaction in VR is limited. This paper introduces a novel Swarm Manipulation interaction technique and compares it with two baseline techniques: Virtual Hand and Controller (ray-casting). We evaluated these techniques in a user study ($N$ = 12) in three tasks (selection, rotation, and resizing) across five conditions. Our results indicate that Swarm Manipulation yielded superior performance, with significantly faster speeds in most conditions across the three tasks. It notably reduced resizing size deviations but introduced a trade-off between speed and accuracy in the rotation task. Additionally, we conducted a follow-up user study ($N$ = 6) using Swarm Manipulation in two complex VR scenarios and obtained insights through semi-structured interviews, shedding light on optimized swarm control mechanisms and perceptual changes induced by this interaction paradigm. These results demonstrate the potential of the Swarm Manipulation technique to enhance the usability and user experience in VR compared to conventional manipulation techniques. In future studies, we aim to understand and improve swarm interaction via internal swarm particle cooperation.