 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Image Generation for Vocabulary Learning Using the Keyword Method
Jan 28, 2025



The 'keyword method' is an effective technique for learning vocabulary of a foreign language. It involves creating a memorable visual link between what a word means and what its pronunciation in a foreign language sounds like in the learner's native language. However, these memorable visual links remain implicit in the people's mind and are not easy to remember for a large set of words. To enhance the memorisation and recall of the vocabulary, we developed an application that combines the keyword method with text-to-image generators to externalise the memorable visual links into visuals. These visuals represent additional stimuli during the memorisation process. To explore the effectiveness of this approach we first run a pilot study to investigate how difficult it is to externalise the descriptions of mental visualisations of memorable links, by asking participants to write them down. We used these descriptions as prompts for text-to-image generator (DALL-E2) to convert them into images and asked participants to select their favourites. Next, we compared different text-to-image generators (DALL-E2, Midjourney, Stable and Latent Diffusion) to evaluate the perceived quality of the generated images by each. Despite heterogeneous results, participants mostly preferred images generated by DALL-E2, which was used also for the final study. In this study, we investigated whether providing such images enhances the retention of vocabulary being learned, compared to the keyword method only. Our results indicate that people did not encounter difficulties describing their visualisations of memorable links and that providing corresponding images significantly improves memory retention.
Generative AI for Accessible and Inclusive Extended Reality
Oct 31, 2024Artificial Intelligence-Generated Content (AIGC) has the potential to transform how people build and interact with virtual environments. Within this paper, we discuss potential benefits but also challenges that AIGC has for the creation of inclusive and accessible virtual environments. Specifically, we touch upon the decreased need for 3D modeling expertise, benefits of symbolic-only as well as multimodal input, 3D content editing, and 3D model accessibility as well as foundation model-specific challenges.
Analyzing Multimodal Interaction Strategies for LLM-Assisted Manipulation of 3D Scenes
Oct 29, 2024



As more applications of large language models (LLMs) for 3D content for immersive environments emerge, it is crucial to study user behaviour to identify interaction patterns and potential barriers to guide the future design of immersive content creation and editing systems which involve LLMs. In an empirical user study with 12 participants, we combine quantitative usage data with post-experience questionnaire feedback to reveal common interaction patterns and key barriers in LLM-assisted 3D scene editing systems. We identify opportunities for improving natural language interfaces in 3D design tools and propose design recommendations for future LLM-integrated 3D content creation systems. Through an empirical study, we demonstrate that LLM-assisted interactive systems can be used productively in immersive environments.
Large Language Model-assisted Speech and Pointing Benefits Multiple 3D Object Selection in Virtual Reality
Oct 28, 2024Selection of occluded objects is a challenging problem in virtual reality, even more so if multiple objects are involved. With the advent of new artificial intelligence technologies, we explore the possibility of leveraging large language models to assist multi-object selection tasks in virtual reality via a multimodal speech and raycast interaction technique. We validate the findings in a comparative user study (n=24), where participants selected target objects in a virtual reality scene with different levels of scene perplexity. The performance metrics and user experience metrics are compared against a mini-map based occluded object selection technique that serves as the baseline. Results indicate that the introduced technique, AssistVR, outperforms the baseline technique when there are multiple target objects. Contrary to the common belief for speech interfaces, AssistVR was able to outperform the baseline even when the target objects were difficult to reference verbally. This work demonstrates the viability and interaction potential of an intelligent multimodal interactive system powered by large laguage models. Based on the results, we discuss the implications for design of future intelligent multimodal interactive systems in immersive environments.
Efficient Pose Tracking from Natural Features in Standard Web Browsers
Apr 23, 2018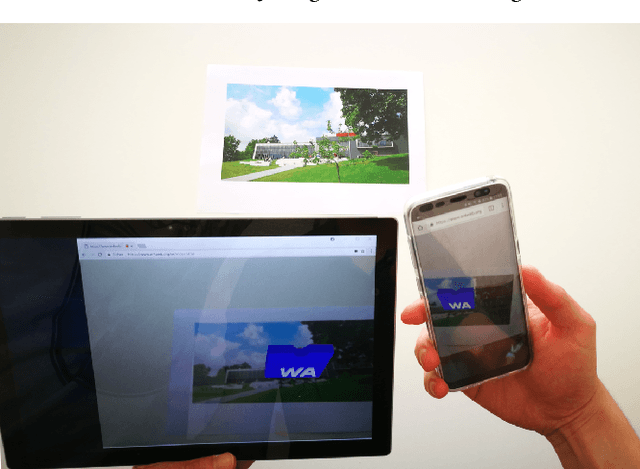
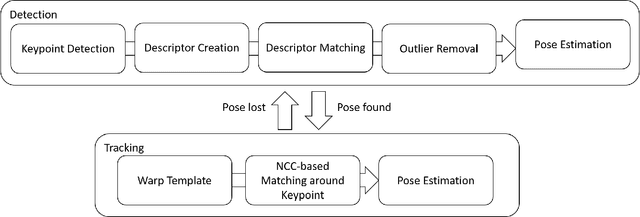
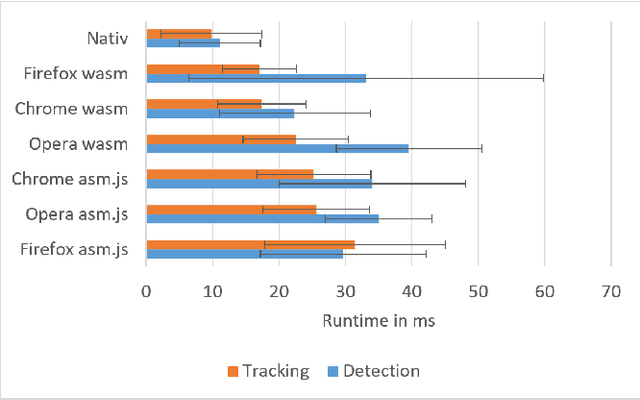
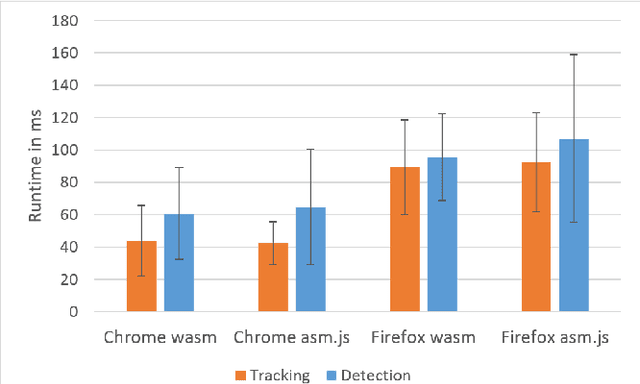
Computer Vision-based natural feature tracking is at the core of modern Augmented Reality applications. Still, Web-based Augmented Reality typically relies on location-based sensing (using GPS and orientation sensors) or marker-based approaches to solve the pose estimation problem. We present an implementation and evaluation of an efficient natural feature tracking pipeline for standard Web browsers using HTML5 and WebAssembly. Our system can track image targets at real-time frame rates tablet PCs (up to 60 Hz) and smartphones (up to 25 Hz).
BodyDigitizer: An Open Source Photogrammetry-based 3D Body Scanner
Oct 28, 2017
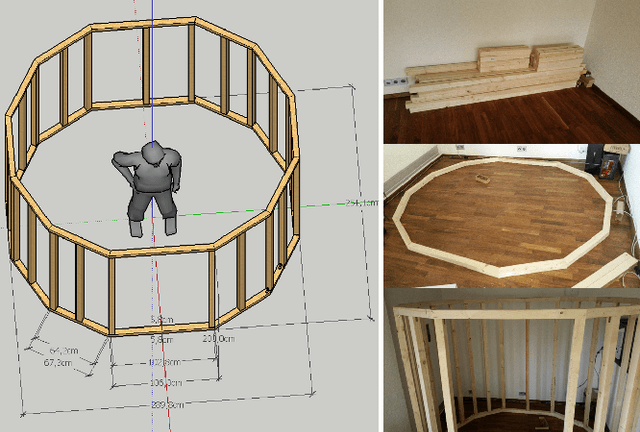

With the rising popularity of Augmented and Virtual Reality, there is a need for representing humans as virtual avatars in various application domains ranging from remote telepresence, games to medical applications. Besides explicitly modelling 3D avatars, sensing approaches that create person-specific avatars are becoming popular. However, affordable solutions typically suffer from a low visual quality and professional solution are often too expensive to be deployed in nonprofit projects. We present an open-source project, BodyDigitizer, which aims at providing both build instructions and configuration software for a high-resolution photogrammetry-based 3D body scanner. Our system encompasses up to 96 Rasperry PI cameras, active LED lighting, a sturdy frame construction and open-source configuration software. %We demonstrate the applicability of the body scanner in a nonprofit Mixed Reality health project. The detailed build instruction and software are available at http://www.bodydigitizer.org.
A Survey of Calibration Methods for Optical See-Through Head-Mounted Displays
Sep 13, 2017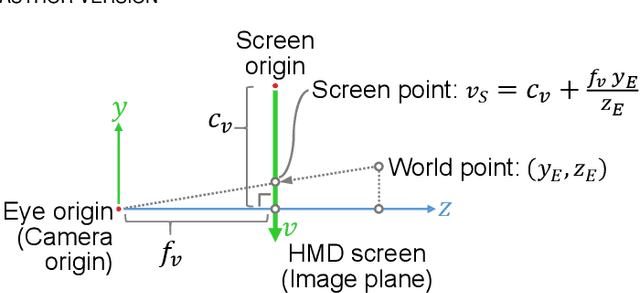
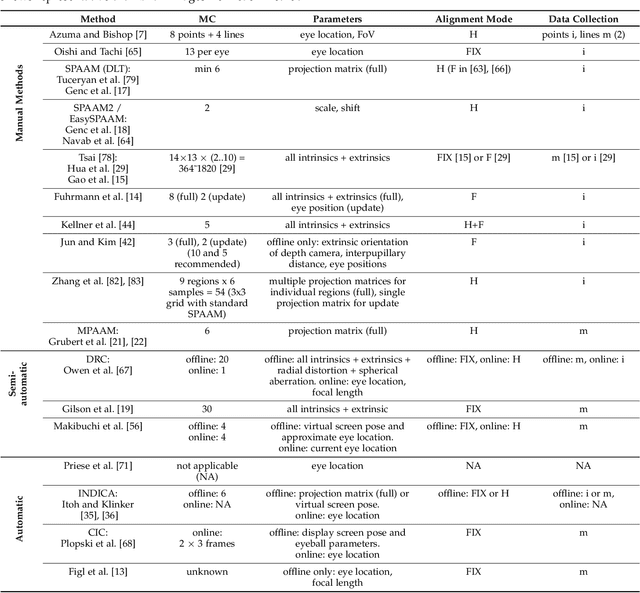
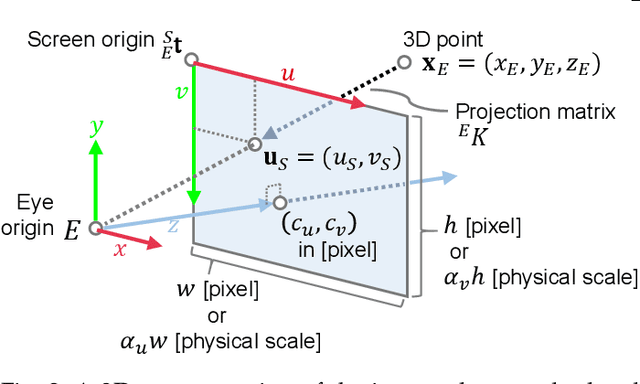
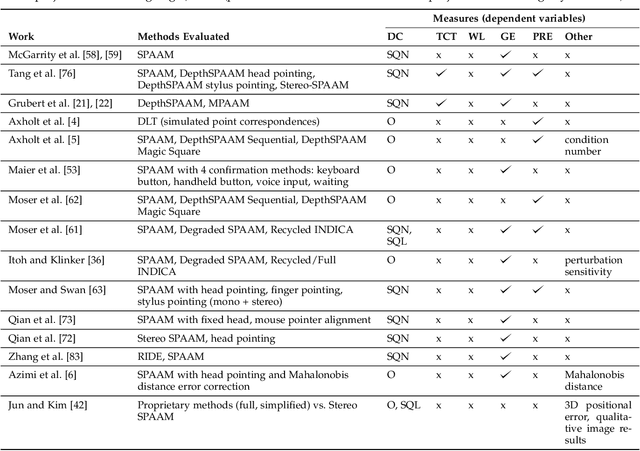
Optical see-through head-mounted displays (OST HMDs) are a major output medium for Augmented Reality, which have seen significant growth in popularity and usage among the general public due to the growing release of consumer-oriented models, such as the Microsoft Hololens. Unlike Virtual Reality headsets, OST HMDs inherently support the addition of computer-generated graphics directly into the light path between a user's eyes and their view of the physical world. As with most Augmented and Virtual Reality systems, the physical position of an OST HMD is typically determined by an external or embedded 6-Degree-of-Freedom tracking system. However, in order to properly render virtual objects, which are perceived as spatially aligned with the physical environment, it is also necessary to accurately measure the position of the user's eyes within the tracking system's coordinate frame. For over 20 years, researchers have proposed various calibration methods to determine this needed eye position. However, to date, there has not been a comprehensive overview of these procedures and their requirements. Hence, this paper surveys the field of calibration methods for OST HMDs. Specifically, it provides insights into the fundamentals of calibration techniques, and presents an overview of both manual and automatic approaches, as well as evaluation methods and metrics. Finally, it also identifies opportunities for future research. % relative to the tracking coordinate system, and, hence, its position in 3D space.
Towards Around-Device Interaction using Corneal Imaging
Sep 04, 2017

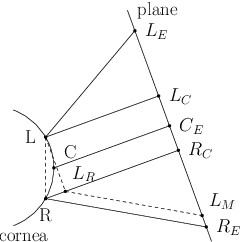

Around-device interaction techniques aim at extending the input space using various sensing modalities on mobile and wearable devices. In this paper, we present our work towards extending the input area of mobile devices using front-facing device-centered cameras that capture reflections in the human eye. As current generation mobile devices lack high resolution front-facing cameras we study the feasibility of around-device interaction using corneal reflective imaging based on a high resolution camera. We present a workflow, a technical prototype and an evaluation, including a migration path from high resolution to low resolution imagers. Our study indicates, that under optimal conditions a spatial sensing resolution of 5 cm in the vicinity of a mobile phone is possible.
Feasibility of Corneal Imaging for Handheld Augmented Reality
Sep 04, 2017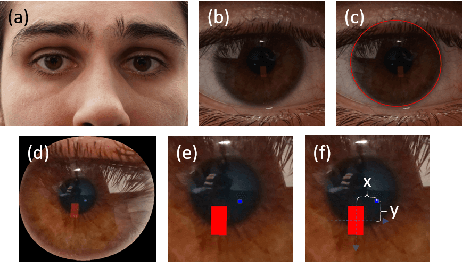
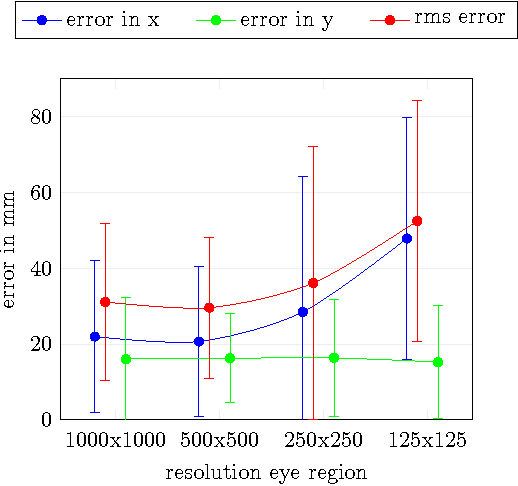
Smartphones are a popular device class for mobile Augmented Reality but suffer from a limited input space. Around-device interaction techniques aim at extending this input space using various sensing modalities. In this paper we present our work towards extending the input area of mobile devices using front-facing device-centered cameras that capture reflections in the cornea. As current generation mobile devices lack high resolution front-facing cameras, we study the feasibility of around-device interaction using corneal reflective imaging based on a high resolution camera. We present a workflow, a technical prototype and a feasibility evaluation.