 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthSoM-Twin: A Multi-Modal Sensing-Communication Digital-Twin Dataset for Sim2Real Transfer via Synesthesia of Machines
Nov 14, 2025



This paper constructs a novel multi-modal sensing-communication digital-twin dataset, named SynthSoM-Twin, which is spatio-temporally consistent with the real world, for Sim2Real transfer via Synesthesia of Machines (SoM). To construct the SynthSoM-Twin dataset, we propose a new framework that can extend the quantity and missing modality of existing real-world multi-modal sensing-communication dataset. Specifically, we exploit multi-modal sensing-assisted object detection and tracking algorithms to ensure spatio-temporal consistency of static objects and dynamic objects across real world and simulation environments. The constructed scenario is imported into three high-fidelity simulators, i.e., AirSim, WaveFarer, and Sionna RT. The SynthSoM-Twin dataset contains spatio-temporally consistent data with the real world, including 66,868 snapshots of synthetic RGB images, depth maps, light detection and ranging (LiDAR) point clouds, millimeter wave (mmWave) radar point clouds, and large-scale and small-scale channel fading data. To validate the utility of SynthSoM-Twin dataset, we conduct Sim2Real transfer investigation by implementing two cross-modal downstream tasks via cross-modal generative models (CMGMs), i.e., cross-modal channel generation model and multi-modal sensing-assisted beam generation model. Based on the downstream tasks, we explore the threshold of real-world data injection that can achieve a decent trade-off between real-world data usage and models' practical performance. Experimental results show that the model training on the SynthSoM-Twin dataset achieves a decent practical performance, and the injection of real-world data further facilitates Sim2Real transferability. Based on the SynthSoM-Twin dataset, injecting less than 15% of real-world data can achieve similar and even better performance compared to that trained with all the real-world data only.
Diffusion-based Auction Mechanism for Efficient Resource Management in 6G-enabled Vehicular Metaverses
Nov 01, 2024The rise of 6G-enable Vehicular Metaverses is transforming the automotive industry by integrating immersive, real-time vehicular services through ultra-low latency and high bandwidth connectivity. In 6G-enable Vehicular Metaverses, vehicles are represented by Vehicle Twins (VTs), which serve as digital replicas of physical vehicles to support real-time vehicular applications such as large Artificial Intelligence (AI) model-based Augmented Reality (AR) navigation, called VT tasks. VT tasks are resource-intensive and need to be offloaded to ground Base Stations (BSs) for fast processing. However, high demand for VT tasks and limited resources of ground BSs, pose significant resource allocation challenges, particularly in densely populated urban areas like intersections. As a promising solution, Unmanned Aerial Vehicles (UAVs) act as aerial edge servers to dynamically assist ground BSs in handling VT tasks, relieving resource pressure on ground BSs. However, due to high mobility of UAVs, there exists information asymmetry regarding VT task demands between UAVs and ground BSs, resulting in inefficient resource allocation of UAVs. To address these challenges, we propose a learning-based Modified Second-Bid (MSB) auction mechanism to optimize resource allocation between ground BSs and UAVs by accounting for VT task latency and accuracy. Moreover, we design a diffusion-based reinforcement learning algorithm to optimize the price scaling factor, maximizing the total surplus of resource providers and minimizing VT task latency. Finally, simulation results demonstrate that the proposed diffusion-based MSB auction outperforms traditional baselines, providing better resource distribution and enhanced service quality for vehicular users.
Generative AI for Accessible and Inclusive Extended Reality
Oct 31, 2024Artificial Intelligence-Generated Content (AIGC) has the potential to transform how people build and interact with virtual environments. Within this paper, we discuss potential benefits but also challenges that AIGC has for the creation of inclusive and accessible virtual environments. Specifically, we touch upon the decreased need for 3D modeling expertise, benefits of symbolic-only as well as multimodal input, 3D content editing, and 3D model accessibility as well as foundation model-specific challenges.
Analyzing Multimodal Interaction Strategies for LLM-Assisted Manipulation of 3D Scenes
Oct 29, 2024



As more applications of large language models (LLMs) for 3D content for immersive environments emerge, it is crucial to study user behaviour to identify interaction patterns and potential barriers to guide the future design of immersive content creation and editing systems which involve LLMs. In an empirical user study with 12 participants, we combine quantitative usage data with post-experience questionnaire feedback to reveal common interaction patterns and key barriers in LLM-assisted 3D scene editing systems. We identify opportunities for improving natural language interfaces in 3D design tools and propose design recommendations for future LLM-integrated 3D content creation systems. Through an empirical study, we demonstrate that LLM-assisted interactive systems can be used productively in immersive environments.
Large Language Model-assisted Speech and Pointing Benefits Multiple 3D Object Selection in Virtual Reality
Oct 28, 2024Selection of occluded objects is a challenging problem in virtual reality, even more so if multiple objects are involved. With the advent of new artificial intelligence technologies, we explore the possibility of leveraging large language models to assist multi-object selection tasks in virtual reality via a multimodal speech and raycast interaction technique. We validate the findings in a comparative user study (n=24), where participants selected target objects in a virtual reality scene with different levels of scene perplexity. The performance metrics and user experience metrics are compared against a mini-map based occluded object selection technique that serves as the baseline. Results indicate that the introduced technique, AssistVR, outperforms the baseline technique when there are multiple target objects. Contrary to the common belief for speech interfaces, AssistVR was able to outperform the baseline even when the target objects were difficult to reference verbally. This work demonstrates the viability and interaction potential of an intelligent multimodal interactive system powered by large laguage models. Based on the results, we discuss the implications for design of future intelligent multimodal interactive systems in immersive environments.
Diffusion-based Reinforcement Learning for Dynamic UAV-assisted Vehicle Twins Migration in Vehicular Metaverses
Jun 08, 2024



Air-ground integrated networks can relieve communication pressure on ground transportation networks and provide 6G-enabled vehicular Metaverses services offloading in remote areas with sparse RoadSide Units (RSUs) coverage and downtown areas where users have a high demand for vehicular services. Vehicle Twins (VTs) are the digital twins of physical vehicles to enable more immersive and realistic vehicular services, which can be offloaded and updated on RSU, to manage and provide vehicular Metaverses services to passengers and drivers. The high mobility of vehicles and the limited coverage of RSU signals necessitate VT migration to ensure service continuity when vehicles leave the signal coverage of RSUs. However, uneven VT task migration might overload some RSUs, which might result in increased service latency, and thus impactive immersive experiences for users. In this paper, we propose a dynamic Unmanned Aerial Vehicle (UAV)-assisted VT migration framework in air-ground integrated networks, where UAVs act as aerial edge servers to assist ground RSUs during VT task offloading. In this framework, we propose a diffusion-based Reinforcement Learning (RL) algorithm, which can efficiently make immersive VT migration decisions in UAV-assisted vehicular networks. To balance the workload of RSUs and improve VT migration quality, we design a novel dynamic path planning algorithm based on a heuristic search strategy for UAVs. Simulation results show that the diffusion-based RL algorithm with UAV-assisted performs better than other baseline schemes.
Multi-attribute Auction-based Resource Allocation for Twins Migration in Vehicular Metaverses: A GPT-based DRL Approach
Jun 08, 2024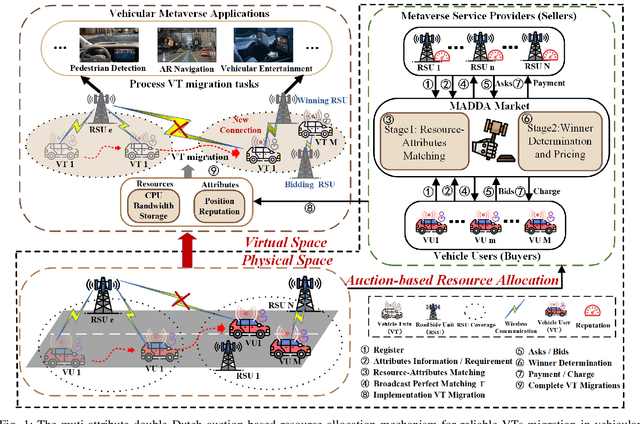
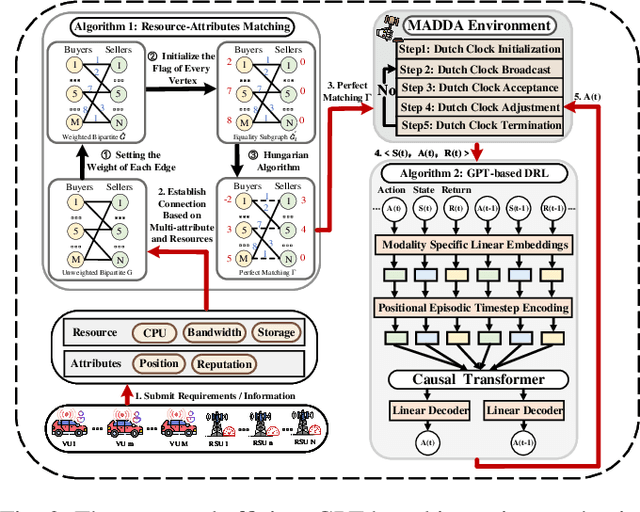
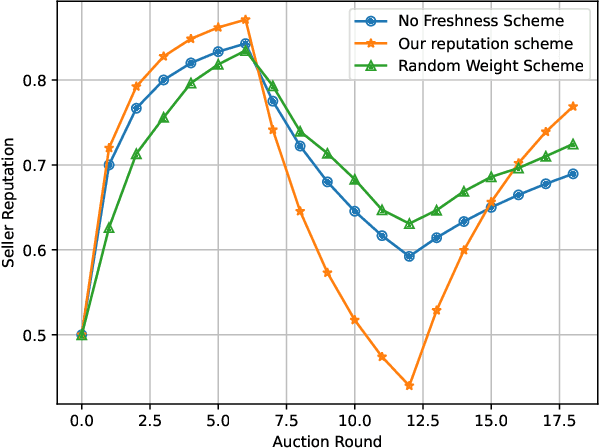
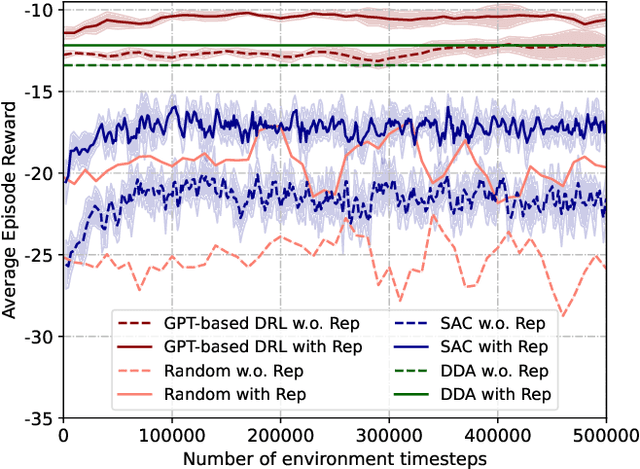
Vehicular Metaverses are developed to enhance the modern automotive industry with an immersive and safe experience among connected vehicles and roadside infrastructures, e.g., RoadSide Units (RSUs). For seamless synchronization with virtual spaces, Vehicle Twins (VTs) are constructed as digital representations of physical entities. However, resource-intensive VTs updating and high mobility of vehicles require intensive computation, communication, and storage resources, especially for their migration among RSUs with limited coverages. To address these issues, we propose an attribute-aware auction-based mechanism to optimize resource allocation during VTs migration by considering both price and non-monetary attributes, e.g., location and reputation. In this mechanism, we propose a two-stage matching for vehicular users and Metaverse service providers in multi-attribute resource markets. First, the resource attributes matching algorithm obtains the resource attributes perfect matching, namely, buyers and sellers can participate in a double Dutch auction (DDA). Then, we train a DDA auctioneer using a generative pre-trained transformer (GPT)-based deep reinforcement learning (DRL) algorithm to adjust the auction clocks efficiently during the auction process. We compare the performance of social welfare and auction information exchange costs with state-of-the-art baselines under different settings. Simulation results show that our proposed GPT-based DRL auction schemes have better performance than others.
Multi-Agent Deep Reinforcement Learning for Dynamic Avatar Migration in AIoT-enabled Vehicular Metaverses with Trajectory Prediction
Jun 26, 2023Avatars, as promising digital assistants in Vehicular Metaverses, can enable drivers and passengers to immerse in 3D virtual spaces, serving as a practical emerging example of Artificial Intelligence of Things (AIoT) in intelligent vehicular environments. The immersive experience is achieved through seamless human-avatar interaction, e.g., augmented reality navigation, which requires intensive resources that are inefficient and impractical to process on intelligent vehicles locally. Fortunately, offloading avatar tasks to RoadSide Units (RSUs) or cloud servers for remote execution can effectively reduce resource consumption. However, the high mobility of vehicles, the dynamic workload of RSUs, and the heterogeneity of RSUs pose novel challenges to making avatar migration decisions. To address these challenges, in this paper, we propose a dynamic migration framework for avatar tasks based on real-time trajectory prediction and Multi-Agent Deep Reinforcement Learning (MADRL). Specifically, we propose a model to predict the future trajectories of intelligent vehicles based on their historical data, indicating the future workloads of RSUs.Based on the expected workloads of RSUs, we formulate the avatar task migration problem as a long-term mixed integer programming problem. To tackle this problem efficiently, the problem is transformed into a Partially Observable Markov Decision Process (POMDP) and solved by multiple DRL agents with hybrid continuous and discrete actions in decentralized. Numerical results demonstrate that our proposed algorithm can effectively reduce the latency of executing avatar tasks by around 25% without prediction and 30% with prediction and enhance user immersive experiences in the AIoT-enabled Vehicular Metaverse (AeVeM).
Generative AI-empowered Simulation for Autonomous Driving in Vehicular Mixed Reality Metaverses
Feb 16, 2023In the vehicular mixed reality (MR) Metaverse, the distance between physical and virtual entities can be overcome by fusing the physical and virtual environments with multi-dimensional communications in autonomous driving systems. Assisted by digital twin (DT) technologies, connected autonomous vehicles (AVs), roadside units (RSU), and virtual simulators can maintain the vehicular MR Metaverse via digital simulations for sharing data and making driving decisions collaboratively. However, large-scale traffic and driving simulation via realistic data collection and fusion from the physical world for online prediction and offline training in autonomous driving systems are difficult and costly. In this paper, we propose an autonomous driving architecture, where generative AI is leveraged to synthesize unlimited conditioned traffic and driving data in simulations for improving driving safety and traffic efficiency. First, we propose a multi-task DT offloading model for the reliable execution of heterogeneous DT tasks with different requirements at RSUs. Then, based on the preferences of AV's DTs and collected realistic data, virtual simulators can synthesize unlimited conditioned driving and traffic datasets to further improve robustness. Finally, we propose a multi-task enhanced auction-based mechanism to provide fine-grained incentives for RSUs in providing resources for autonomous driving. The property analysis and experimental results demonstrate that the proposed mechanism and architecture are strategy-proof and effective, respectively.
Augmented Reality on the Large Scene Based on a Markerless Registration Framework
Mar 07, 2020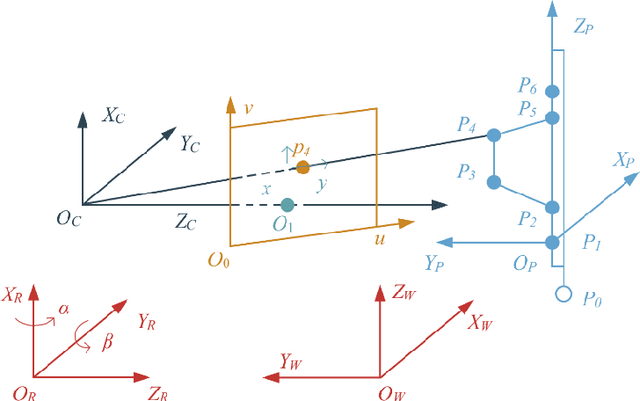

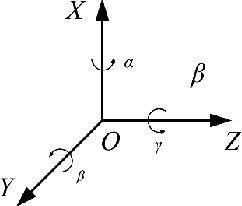
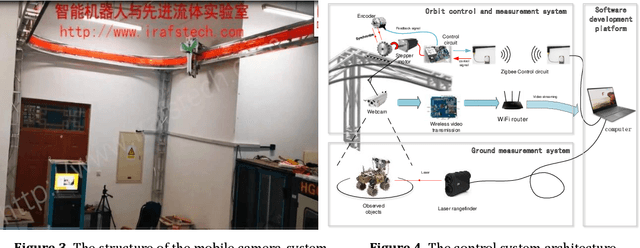
In this paper, a mobile camera positioning method based on forward and inverse kinematics of robot is proposed, which can realize far point positioning of imaging position and attitude tracking in large scene enhancement. Orbit precision motion through the framework overhead cameras and combining with the ground system of sensor array object such as mobile robot platform of various sensors, realize the good 3 d image registration, solve any artifacts that is mobile robot in the large space position initialization problem, effectively implement the large space no marks augmented reality, human-computer interaction, and information summary. Finally, the feasibility and effectiveness of the method are verified by experiments.