 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLyapunov Stability-Aware Stackelberg Game for Low-Altitude Economy: A Control-Oriented Pruning-Based DRL Approach
Feb 01, 2026With the rapid expansion of the low-altitude economy, Unmanned Aerial Vehicles (UAVs) serve as pivotal aerial base stations supporting diverse services from users, ranging from latency-sensitive critical missions to bandwidth-intensive data streaming. However, the efficacy of such heterogeneous networks is often compromised by the conflict between limited onboard resources and stringent stability requirements. Moving beyond traditional throughput-centric designs, we propose a Sensing-Communication-Computing-Control closed-loop framework that explicitly models the impact of communication latency on physical control stability. To guarantee mission reliability, we leverage the Lyapunov stability theory to derive an intrinsic mapping between the state evolution of the control system and communication constraints, transforming abstract stability requirements into quantifiable resource boundaries. Then, we formulate the resource allocation problem as a Stackelberg game, where UAVs (as leaders) dynamically price resources to balance load and ensure stability, while users (as followers) optimize requests based on service urgency. Furthermore, addressing the prohibitive computational overhead of standard Deep Reinforcement Learning (DRL) on energy-constrained edge platforms, we propose a novel and lightweight pruning-based Proximal Policy Optimization (PPO) algorithm. By integrating a dynamic structured pruning mechanism, the proposed algorithm significantly compresses the neural network scale during training, enabling the UAV to rapidly approximate the game equilibrium with minimal inference latency. Simulation results demonstrate that the proposed scheme effectively secures control loop stability while maximizing system utility in dynamic low-altitude environments.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
DR.EHR: Dense Retrieval for Electronic Health Record with Knowledge Injection and Synthetic Data
Jul 24, 2025Electronic Health Records (EHRs) are pivotal in clinical practices, yet their retrieval remains a challenge mainly due to semantic gap issues. Recent advancements in dense retrieval offer promising solutions but existing models, both general-domain and biomedical-domain, fall short due to insufficient medical knowledge or mismatched training corpora. This paper introduces \texttt{DR.EHR}, a series of dense retrieval models specifically tailored for EHR retrieval. We propose a two-stage training pipeline utilizing MIMIC-IV discharge summaries to address the need for extensive medical knowledge and large-scale training data. The first stage involves medical entity extraction and knowledge injection from a biomedical knowledge graph, while the second stage employs large language models to generate diverse training data. We train two variants of \texttt{DR.EHR}, with 110M and 7B parameters, respectively. Evaluated on the CliniQ benchmark, our models significantly outperforms all existing dense retrievers, achieving state-of-the-art results. Detailed analyses confirm our models' superiority across various match and query types, particularly in challenging semantic matches like implication and abbreviation. Ablation studies validate the effectiveness of each pipeline component, and supplementary experiments on EHR QA datasets demonstrate the models' generalizability on natural language questions, including complex ones with multiple entities. This work significantly advances EHR retrieval, offering a robust solution for clinical applications.
Bi-LSTM based Multi-Agent DRL with Computation-aware Pruning for Agent Twins Migration in Vehicular Embodied AI Networks
May 09, 2025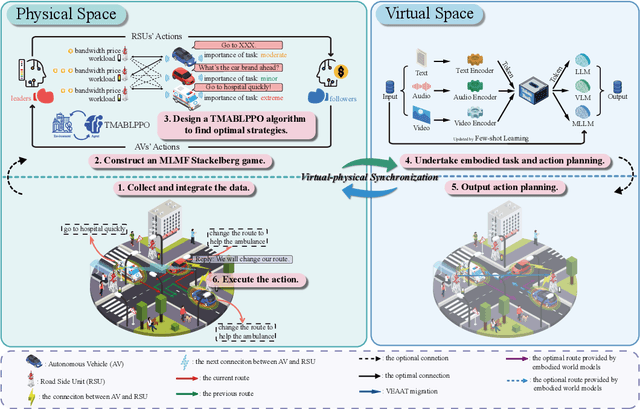
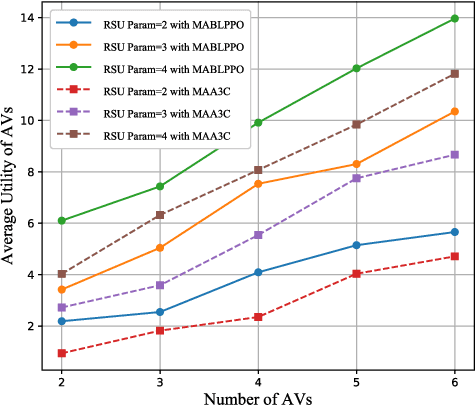
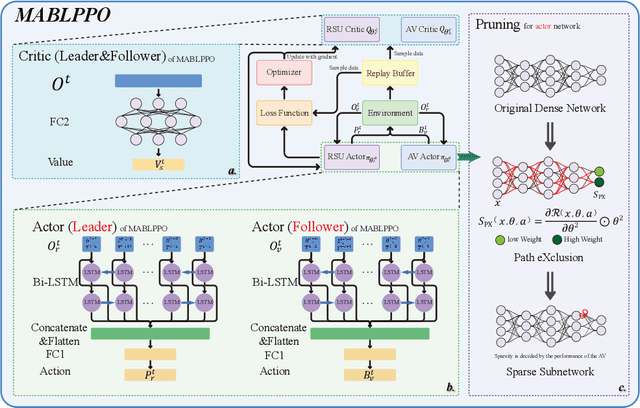
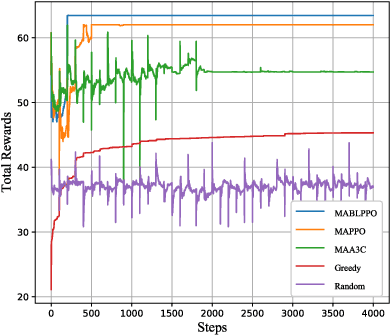
With the advancement of large language models and embodied Artificial Intelligence (AI) in the intelligent transportation scenarios, the combination of them in intelligent transportation spawns the Vehicular Embodied AI Network (VEANs). In VEANs, Autonomous Vehicles (AVs) are typical agents whose local advanced AI applications are defined as vehicular embodied AI agents, enabling capabilities such as environment perception and multi-agent collaboration. Due to computation latency and resource constraints, the local AI applications and services running on vehicular embodied AI agents need to be migrated, and subsequently referred to as vehicular embodied AI agent twins, which drive the advancement of vehicular embodied AI networks to offload intensive tasks to Roadside Units (RSUs), mitigating latency problems while maintaining service quality. Recognizing workload imbalance among RSUs in traditional approaches, we model AV-RSU interactions as a Stackelberg game to optimize bandwidth resource allocation for efficient migration. A Tiny Multi-Agent Bidirectional LSTM Proximal Policy Optimization (TMABLPPO) algorithm is designed to approximate the Stackelberg equilibrium through decentralized coordination. Furthermore, a personalized neural network pruning algorithm based on Path eXclusion (PX) dynamically adapts to heterogeneous AV computation capabilities by identifying task-critical parameters in trained models, reducing model complexity with less performance degradation. Experimental validation confirms the algorithm's effectiveness in balancing system load and minimizing delays, demonstrating significant improvements in vehicular embodied AI agent deployment.
Diffusion-based Auction Mechanism for Efficient Resource Management in 6G-enabled Vehicular Metaverses
Nov 01, 2024The rise of 6G-enable Vehicular Metaverses is transforming the automotive industry by integrating immersive, real-time vehicular services through ultra-low latency and high bandwidth connectivity. In 6G-enable Vehicular Metaverses, vehicles are represented by Vehicle Twins (VTs), which serve as digital replicas of physical vehicles to support real-time vehicular applications such as large Artificial Intelligence (AI) model-based Augmented Reality (AR) navigation, called VT tasks. VT tasks are resource-intensive and need to be offloaded to ground Base Stations (BSs) for fast processing. However, high demand for VT tasks and limited resources of ground BSs, pose significant resource allocation challenges, particularly in densely populated urban areas like intersections. As a promising solution, Unmanned Aerial Vehicles (UAVs) act as aerial edge servers to dynamically assist ground BSs in handling VT tasks, relieving resource pressure on ground BSs. However, due to high mobility of UAVs, there exists information asymmetry regarding VT task demands between UAVs and ground BSs, resulting in inefficient resource allocation of UAVs. To address these challenges, we propose a learning-based Modified Second-Bid (MSB) auction mechanism to optimize resource allocation between ground BSs and UAVs by accounting for VT task latency and accuracy. Moreover, we design a diffusion-based reinforcement learning algorithm to optimize the price scaling factor, maximizing the total surplus of resource providers and minimizing VT task latency. Finally, simulation results demonstrate that the proposed diffusion-based MSB auction outperforms traditional baselines, providing better resource distribution and enhanced service quality for vehicular users.
Generative Diffusion-based Contract Design for Efficient AI Twins Migration in Vehicular Embodied AI Networks
Oct 02, 2024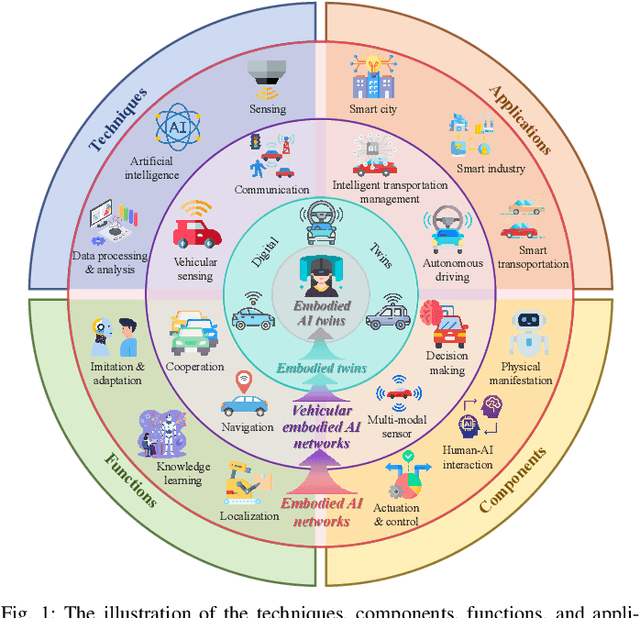
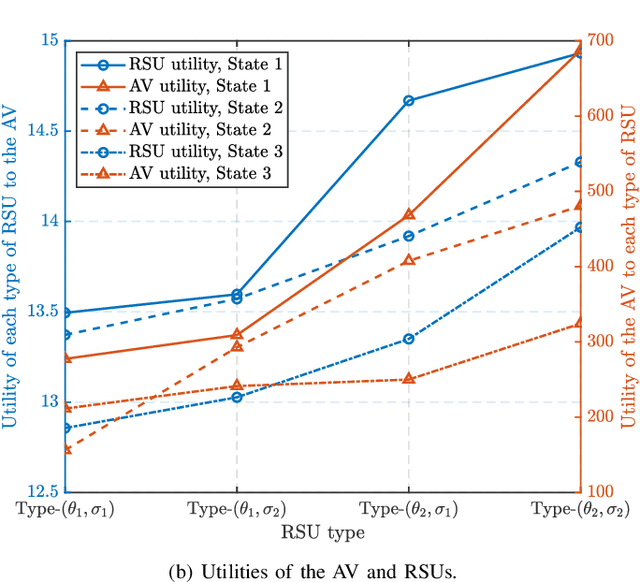
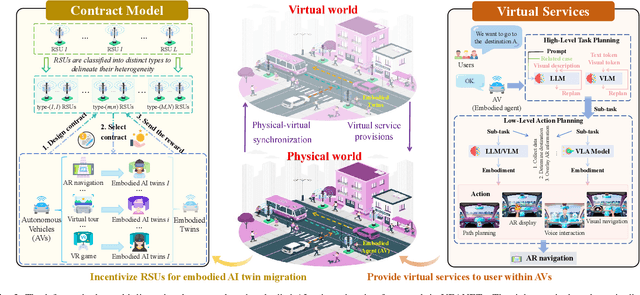
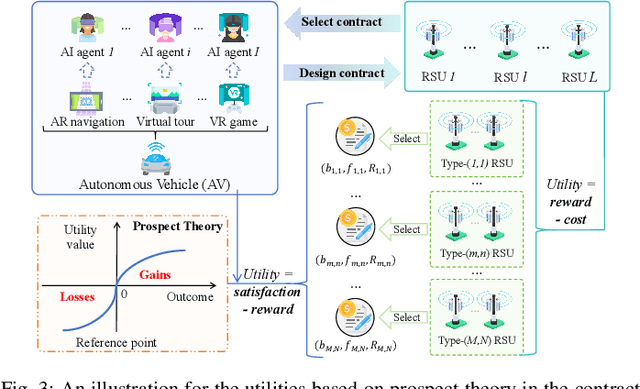
Embodied AI is a rapidly advancing field that bridges the gap between cyberspace and physical space, enabling a wide range of applications. This evolution has led to the development of the Vehicular Embodied AI NETwork (VEANET), where advanced AI capabilities are integrated into vehicular systems to enhance autonomous operations and decision-making. Embodied agents, such as Autonomous Vehicles (AVs), are autonomous entities that can perceive their environment and take actions to achieve specific goals, actively interacting with the physical world. Embodied twins are digital models of these embodied agents, with various embodied AI twins for intelligent applications in cyberspace. In VEANET, embodied AI twins act as in-vehicle AI assistants to perform diverse tasks supporting autonomous driving using generative AI models. Due to limited computational resources of AVs, these AVs often offload computationally intensive tasks, such as constructing and updating embodied AI twins, to nearby RSUs. However, since the rapid mobility of AVs and the limited provision coverage of a single RSU, embodied AI twins require dynamic migrations from current RSU to other RSUs in real-time, resulting in the challenge of selecting suitable RSUs for efficient embodied AI twins migrations. Given information asymmetry, AVs cannot know the detailed information of RSUs. To this end, in this paper, we construct a multi-dimensional contract theoretical model between AVs and alternative RSUs. Considering that AVs may exhibit irrational behavior, we utilize prospect theory instead of expected utility theory to model the actual utilities of AVs. Finally, we employ a generative diffusion model-based algorithm to identify the optimal contract designs. Compared with traditional deep reinforcement learning algorithms, numerical results demonstrate the effectiveness of the proposed scheme.
Tiny Multi-Agent DRL for Twins Migration in UAV Metaverses: A Multi-Leader Multi-Follower Stackelberg Game Approach
Jan 18, 2024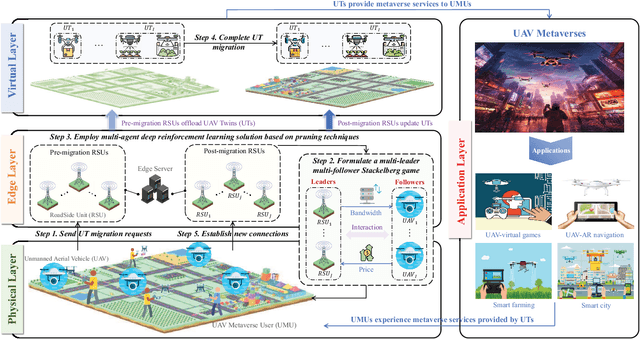
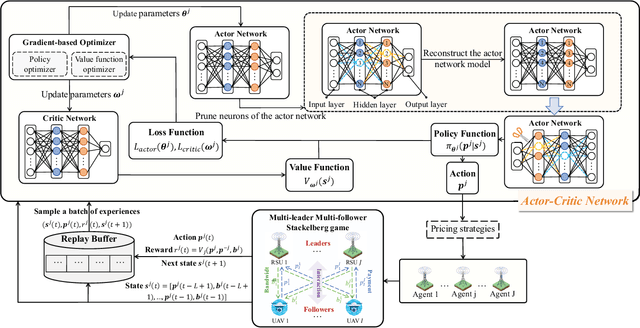
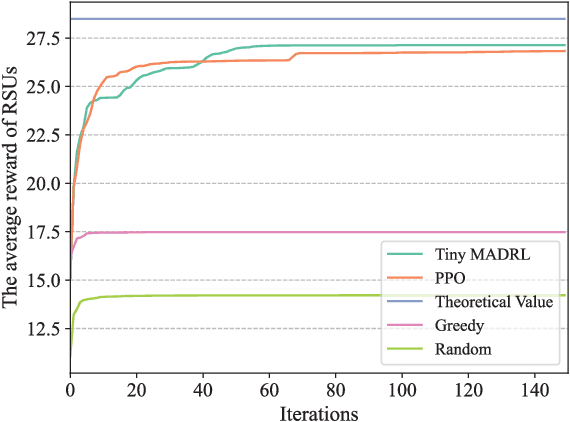
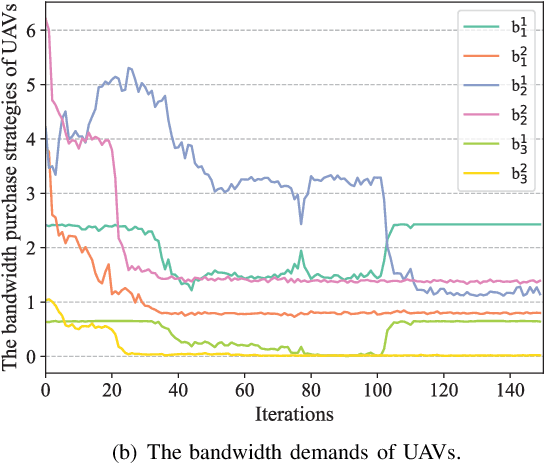
The synergy between Unmanned Aerial Vehicles (UAVs) and metaverses is giving rise to an emerging paradigm named UAV metaverses, which create a unified ecosystem that blends physical and virtual spaces, transforming drone interaction and virtual exploration. UAV Twins (UTs), as the digital twins of UAVs that revolutionize UAV applications by making them more immersive, realistic, and informative, are deployed and updated on ground base stations, e.g., RoadSide Units (RSUs), to offer metaverse services for UAV Metaverse Users (UMUs). Due to the dynamic mobility of UAVs and limited communication coverages of RSUs, it is essential to perform real-time UT migration to ensure seamless immersive experiences for UMUs. However, selecting appropriate RSUs and optimizing the required bandwidth is challenging for achieving reliable and efficient UT migration. To address the challenges, we propose a tiny machine learning-based Stackelberg game framework based on pruning techniques for efficient UT migration in UAV metaverses. Specifically, we formulate a multi-leader multi-follower Stackelberg model considering a new immersion metric of UMUs in the utilities of UAVs. Then, we design a Tiny Multi-Agent Deep Reinforcement Learning (Tiny MADRL) algorithm to obtain the tiny networks representing the optimal game solution. Specifically, the actor-critic network leverages the pruning techniques to reduce the number of network parameters and achieve model size and computation reduction, allowing for efficient implementation of Tiny MADRL. Numerical results demonstrate that our proposed schemes have better performance than traditional schemes.
Deep Sketch-Based Modeling: Tips and Tricks
Nov 17, 2020



Deep image-based modeling received lots of attention in recent years, yet the parallel problem of sketch-based modeling has only been briefly studied, often as a potential application. In this work, for the first time, we identify the main differences between sketch and image inputs: (i) style variance, (ii) imprecise perspective, and (iii) sparsity. We discuss why each of these differences can pose a challenge, and even make a certain class of image-based methods inapplicable. We study alternative solutions to address each of the difference. By doing so, we drive out a few important insights: (i) sparsity commonly results in an incorrect prediction of foreground versus background, (ii) diversity of human styles, if not taken into account, can lead to very poor generalization properties, and finally (iii) unless a dedicated sketching interface is used, one can not expect sketches to match a perspective of a fixed viewpoint. Finally, we compare a set of representative deep single-image modeling solutions and show how their performance can be improved to tackle sketch input by taking into consideration the identified critical differences.