 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentCollab: A Self-Evaluation-Driven Collaboration Paradigm for Efficient LLM Agents
Mar 27, 2026Autonomous agents powered by large language models (LLMs) perform complex tasks through long-horizon reasoning and tool interaction, where a fundamental trade-off arises between execution efficiency and reasoning robustness. Models at different capability-cost levels offer complementary advantages: lower-cost models enable fast execution but may struggle on difficult reasoning segments, while stronger models provide more robust reasoning at higher computational cost. We present AgentCollab, a self-driven collaborative inference framework that dynamically coordinates models with different reasoning capacities during agent execution. Instead of relying on external routing modules, the framework uses the agent's own self-reflection signal to determine whether the current reasoning trajectory is making meaningful progress, and escalates control to a stronger reasoning tier only when necessary. To further stabilize long-horizon execution, we introduce a difficulty-aware cumulative escalation strategy that allocates additional reasoning budget based on recent failure signals. In our experiments, we instantiate this framework using a two-level small-large model setting. Experiments on diverse multi-step agent benchmarks show that AgentCollab consistently improves the accuracy-efficiency Pareto frontier of LLM agents.
MemDLM: Memory-Enhanced DLM Training
Mar 23, 2026Diffusion Language Models (DLMs) offer attractive advantages over Auto-Regressive (AR) models, such as full-attention parallel decoding and flexible generation. However, they suffer from a notable train-inference mismatch: DLMs are trained with a static, single-step masked prediction objective, but deployed through a multi-step progressive denoising trajectory. We propose MemDLM (Memory-Enhanced DLM), which narrows this gap by embedding a simulated denoising process into training via Bi-level Optimization. An inner loop updates a set of fast weights, forming a Parametric Memory that captures the local trajectory experience of each sample, while an outer loop updates the base model conditioned on this memory. By offloading memorization pressure from token representations to parameters, MemDLM yields faster convergence and lower training loss. Moreover, the inner loop can be re-enabled at inference time as an adaptation step, yielding additional gains on long-context understanding. We find that, when activated at inference time, this Parametric Memory acts as an emergent in-weight retrieval mechanism, helping MemDLM further reduce token-level attention bottlenecks on challenging Needle-in-a-Haystack retrieval tasks. Code: https://github.com/JarvisPei/MemDLM.
Unleashing Low-Bit Inference on Ascend NPUs: A Comprehensive Evaluation of HiFloat Formats
Feb 13, 2026As LLMs scale, low-bit floating-point formats like MXFP and NVFP4 offer new opportunities for precision and efficiency. In this work, we evaluate HiFloat (HiF8 and HiF4), a family of formats tailored for Ascend NPUs. Through rigorous comparison across weight-activation and KV-cache tasks, we provide three key insights: (1) INT8 suits narrow-range data, while floating-point formats excel with high-variance data; (2) in 4-bit regimes, HiF4's hierarchical scaling prevents the accuracy collapse seen in integer formats; and (3) HiFloat is fully compatible with state-of-the-art post-training quantization frameworks. Overall, HiFloat provides a solution for high-efficiency LLM inference on NPUs.
DLLM Agent: See Farther, Run Faster
Feb 07, 2026Diffusion large language models (DLLMs) have emerged as an alternative to autoregressive (AR) decoding with appealing efficiency and modeling properties, yet their implications for agentic multi-step decision making remain underexplored. We ask a concrete question: when the generation paradigm is changed but the agent framework and supervision are held fixed, do diffusion backbones induce systematically different planning and tool-use behaviors, and do these differences translate into end-to-end efficiency gains? We study this in a controlled setting by instantiating DLLM and AR backbones within the same agent workflow (DeepDiver) and performing matched agent-oriented fine-tuning on the same trajectory data, yielding diffusion-backed DLLM Agents and directly comparable AR agents. Across benchmarks and case studies, we find that, at comparable accuracy, DLLM Agents are on average over 30% faster end to end than AR agents, with some cases exceeding 8x speedup. Conditioned on correct task completion, DLLM Agents also require fewer interaction rounds and tool invocations, consistent with higher planner hit rates that converge earlier to a correct action path with less backtracking. We further identify two practical considerations for deploying diffusion backbones in tool-using agents. First, naive DLLM policies are more prone to structured tool-call failures, necessitating stronger tool-call-specific training to emit valid schemas and arguments. Second, for multi-turn inputs interleaving context and action spans, diffusion-style span corruption requires aligned attention masking to avoid spurious context-action information flow; without such alignment, performance degrades. Finally, we analyze attention dynamics across workflow stages and observe paradigm-specific coordination patterns, suggesting stronger global planning signals in diffusion-backed agents.
Revisiting Judge Decoding from First Principles via Training-Free Distributional Divergence
Jan 08, 2026Judge Decoding accelerates LLM inference by relaxing the strict verification of Speculative Decoding, yet it typically relies on expensive and noisy supervision. In this work, we revisit this paradigm from first principles, revealing that the ``criticality'' scores learned via costly supervision are intrinsically encoded in the draft-target distributional divergence. We theoretically prove a structural correspondence between learned linear judges and Kullback-Leibler (KL) divergence, demonstrating they rely on the same underlying logit primitives. Guided by this, we propose a simple, training-free verification mechanism based on KL divergence. Extensive experiments across reasoning and coding benchmarks show that our method matches or outperforms complex trained judges (e.g., AutoJudge), offering superior robustness to domain shifts and eliminating the supervision bottleneck entirely.
Towards Efficient Agents: A Co-Design of Inference Architecture and System
Dec 20, 2025The rapid development of large language model (LLM)-based agents has unlocked new possibilities for autonomous multi-turn reasoning and tool-augmented decision-making. However, their real-world deployment is hindered by severe inefficiencies that arise not from isolated model inference, but from the systemic latency accumulated across reasoning loops, context growth, and heterogeneous tool interactions. This paper presents AgentInfer, a unified framework for end-to-end agent acceleration that bridges inference optimization and architectural design. We decompose the problem into four synergistic components: AgentCollab, a hierarchical dual-model reasoning framework that balances large- and small-model usage through dynamic role assignment; AgentSched, a cache-aware hybrid scheduler that minimizes latency under heterogeneous request patterns; AgentSAM, a suffix-automaton-based speculative decoding method that reuses multi-session semantic memory to achieve low-overhead inference acceleration; and AgentCompress, a semantic compression mechanism that asynchronously distills and reorganizes agent memory without disrupting ongoing reasoning. Together, these modules form a Self-Evolution Engine capable of sustaining efficiency and cognitive stability throughout long-horizon reasoning tasks. Experiments on the BrowseComp-zh and DeepDiver benchmarks demonstrate that through the synergistic collaboration of these methods, AgentInfer reduces ineffective token consumption by over 50%, achieving an overall 1.8-2.5 times speedup with preserved accuracy. These results underscore that optimizing for agentic task completion-rather than merely per-token throughput-is the key to building scalable, efficient, and self-improving intelligent systems.
TrimR: Verifier-based Training-Free Thinking Compression for Efficient Test-Time Scaling
May 22, 2025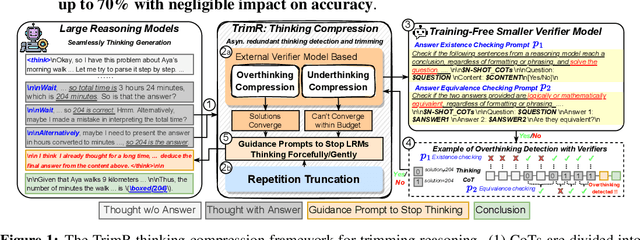
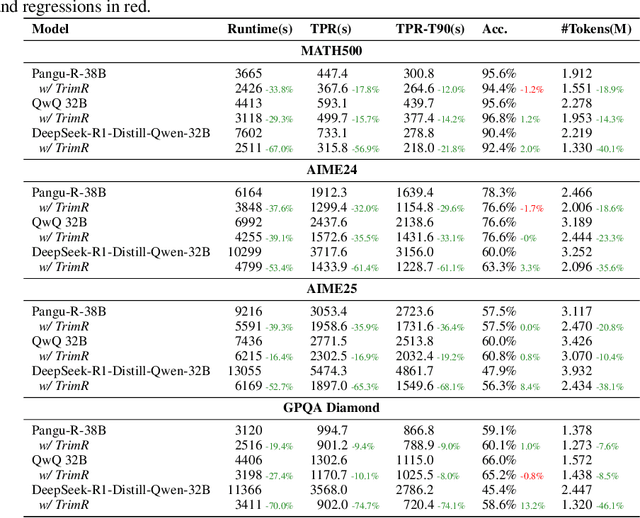
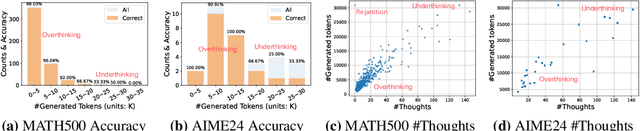
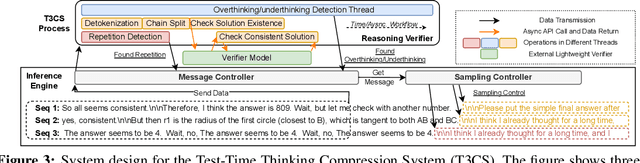
Large Reasoning Models (LRMs) demonstrate exceptional capability in tackling complex mathematical, logical, and coding tasks by leveraging extended Chain-of-Thought (CoT) reasoning. Test-time scaling methods, such as prolonging CoT with explicit token-level exploration, can push LRMs' accuracy boundaries, but they incur significant decoding overhead. A key inefficiency source is LRMs often generate redundant thinking CoTs, which demonstrate clear structured overthinking and underthinking patterns. Inspired by human cognitive reasoning processes and numerical optimization theories, we propose TrimR, a verifier-based, training-free, efficient framework for dynamic CoT compression to trim reasoning and enhance test-time scaling, explicitly tailored for production-level deployment. Our method employs a lightweight, pretrained, instruction-tuned verifier to detect and truncate redundant intermediate thoughts of LRMs without any LRM or verifier fine-tuning. We present both the core algorithm and asynchronous online system engineered for high-throughput industrial applications. Empirical evaluations on Ascend NPUs and vLLM show that our framework delivers substantial gains in inference efficiency under large-batch workloads. In particular, on the four MATH500, AIME24, AIME25, and GPQA benchmarks, the reasoning runtime of Pangu-R-38B, QwQ-32B, and DeepSeek-R1-Distill-Qwen-32B is improved by up to 70% with negligible impact on accuracy.
Improved Fine-Tuning of Large Multimodal Models for Hateful Meme Detection
Feb 18, 2025Hateful memes have become a significant concern on the Internet, necessitating robust automated detection systems. While large multimodal models have shown strong generalization across various tasks, they exhibit poor generalization to hateful meme detection due to the dynamic nature of memes tied to emerging social trends and breaking news. Recent work further highlights the limitations of conventional supervised fine-tuning for large multimodal models in this context. To address these challenges, we propose Large Multimodal Model Retrieval-Guided Contrastive Learning (LMM-RGCL), a novel two-stage fine-tuning framework designed to improve both in-domain accuracy and cross-domain generalization. Experimental results on six widely used meme classification datasets demonstrate that LMM-RGCL achieves state-of-the-art performance, outperforming agent-based systems such as VPD-PALI-X-55B. Furthermore, our method effectively generalizes to out-of-domain memes under low-resource settings, surpassing models like GPT-4o.
CULTURE3D: Cultural Landmarks and Terrain Dataset for 3D Applications
Jan 12, 2025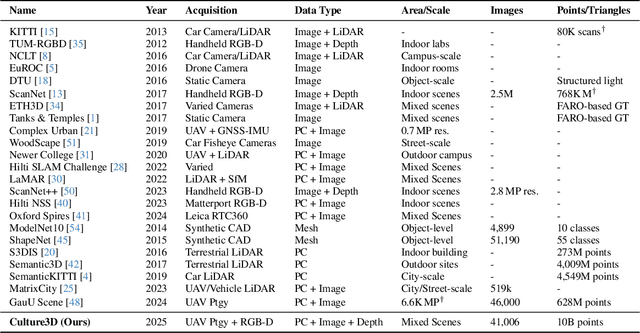
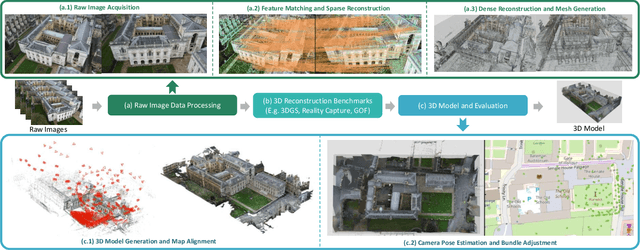
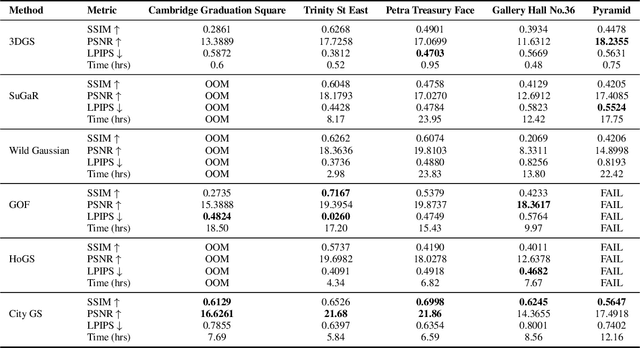

In this paper, we present a large-scale fine-grained dataset using high-resolution images captured from locations worldwide. Compared to existing datasets, our dataset offers a significantly larger size and includes a higher level of detail, making it uniquely suited for fine-grained 3D applications. Notably, our dataset is built using drone-captured aerial imagery, which provides a more accurate perspective for capturing real-world site layouts and architectural structures. By reconstructing environments with these detailed images, our dataset supports applications such as the COLMAP format for Gaussian Splatting and the Structure-from-Motion (SfM) method. It is compatible with widely-used techniques including SLAM, Multi-View Stereo, and Neural Radiance Fields (NeRF), enabling accurate 3D reconstructions and point clouds. This makes it a benchmark for reconstruction and segmentation tasks. The dataset enables seamless integration with multi-modal data, supporting a range of 3D applications, from architectural reconstruction to virtual tourism. Its flexibility promotes innovation, facilitating breakthroughs in 3D modeling and analysis.
X-LeBench: A Benchmark for Extremely Long Egocentric Video Understanding
Jan 12, 2025Long-form egocentric video understanding provides rich contextual information and unique insights into long-term human behaviors, holding significant potential for applications in embodied intelligence, long-term activity analysis, and personalized assistive technologies. However, existing benchmark datasets primarily focus on single, short-duration videos or moderately long videos up to dozens of minutes, leaving a substantial gap in evaluating extensive, ultra-long egocentric video recordings. To address this, we introduce X-LeBench, a novel benchmark dataset specifically crafted for evaluating tasks on extremely long egocentric video recordings. Leveraging the advanced text processing capabilities of large language models (LLMs), X-LeBench develops a life-logging simulation pipeline that produces realistic, coherent daily plans aligned with real-world video data. This approach enables the flexible integration of synthetic daily plans with real-world footage from Ego4D-a massive-scale egocentric video dataset covers a wide range of daily life scenarios-resulting in 432 simulated video life logs that mirror realistic daily activities in contextually rich scenarios. The video life-log durations span from 23 minutes to 16.4 hours. The evaluation of several baseline systems and multimodal large language models (MLLMs) reveals their poor performance across the board, highlighting the inherent challenges of long-form egocentric video understanding and underscoring the need for more advanced models.