 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning with Narrative Twins for Modeling Story Salience
Jan 12, 2026Understanding narratives requires identifying which events are most salient for a story's progression. We present a contrastive learning framework for modeling narrative salience that learns story embeddings from narrative twins: stories that share the same plot but differ in surface form. Our model is trained to distinguish a story from both its narrative twin and a distractor with similar surface features but different plot. Using the resulting embeddings, we evaluate four narratologically motivated operations for inferring salience (deletion, shifting, disruption, and summarization). Experiments on short narratives from the ROCStories corpus and longer Wikipedia plot summaries show that contrastively learned story embeddings outperform a masked-language-model baseline, and that summarization is the most reliable operation for identifying salient sentences. If narrative twins are not available, random dropout can be used to generate the twins from a single story. Effective distractors can be obtained either by prompting LLMs or, in long-form narratives, by using different parts of the same story.
Commute-Time-Optimised Graphs for GNNs
Jul 09, 2024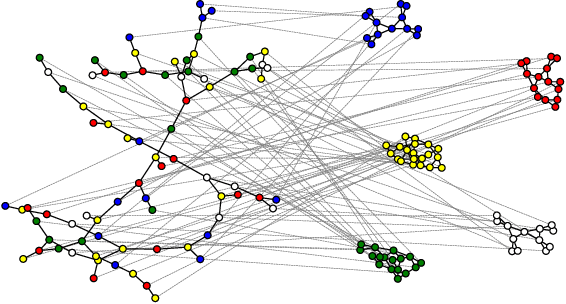
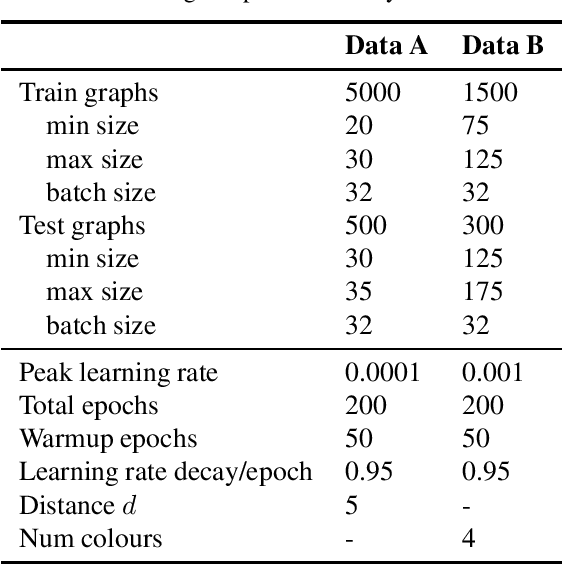
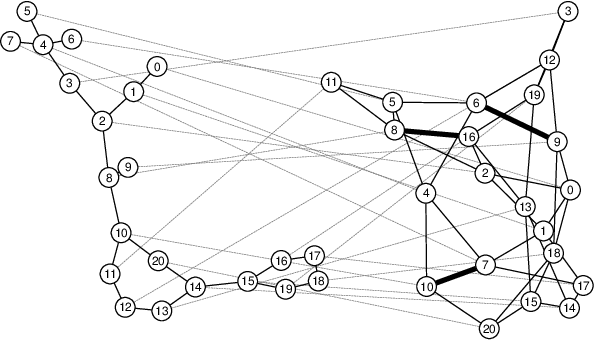

We explore graph rewiring methods that optimise commute time. Recent graph rewiring approaches facilitate long-range interactions in sparse graphs, making such rewirings commute-time-optimal $\textit{on average}$. However, when an expert prior exists on which node pairs should or should not interact, a superior rewiring would favour short commute times between these privileged node pairs. We construct two synthetic datasets with known priors reflecting realistic settings, and use these to motivate two bespoke rewiring methods that incorporate the known prior. We investigate the regimes where our rewiring improves test performance on the synthetic datasets. Finally, we perform a case study on a real-world citation graph to investigate the practical implications of our work.
Segment Any Text: A Universal Approach for Robust, Efficient and Adaptable Sentence Segmentation
Jun 24, 2024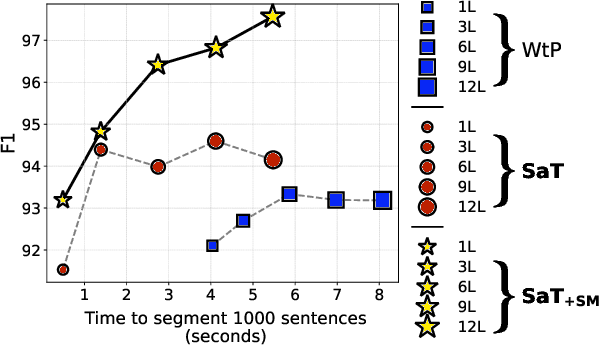
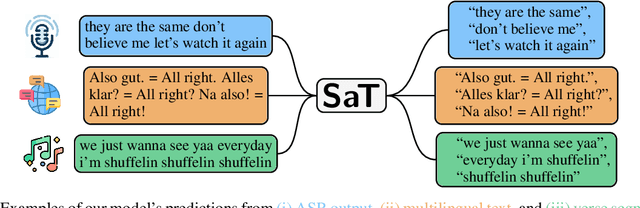
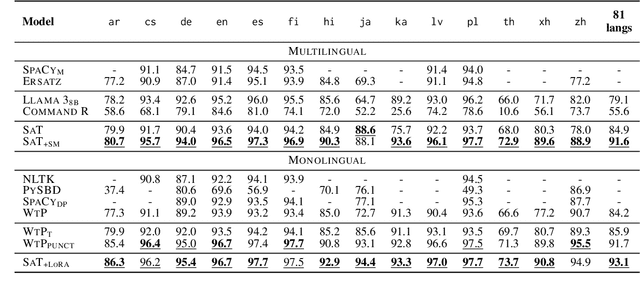
Segmenting text into sentences plays an early and crucial role in many NLP systems. This is commonly achieved by using rule-based or statistical methods relying on lexical features such as punctuation. Although some recent works no longer exclusively rely on punctuation, we find that no prior method achieves all of (i) robustness to missing punctuation, (ii) effective adaptability to new domains, and (iii) high efficiency. We introduce a new model - Segment any Text (SaT) - to solve this problem. To enhance robustness, we propose a new pretraining scheme that ensures less reliance on punctuation. To address adaptability, we introduce an extra stage of parameter-efficient fine-tuning, establishing state-of-the-art performance in distinct domains such as verses from lyrics and legal documents. Along the way, we introduce architectural modifications that result in a threefold gain in speed over the previous state of the art and solve spurious reliance on context far in the future. Finally, we introduce a variant of our model with fine-tuning on a diverse, multilingual mixture of sentence-segmented data, acting as a drop-in replacement and enhancement for existing segmentation tools. Overall, our contributions provide a universal approach for segmenting any text. Our method outperforms all baselines - including strong LLMs - across 8 corpora spanning diverse domains and languages, especially in practically relevant situations where text is poorly formatted. Our models and code, including documentation, are available at https://huggingface.co/segment-any-text under the MIT license.
Few-Shot VQA with Frozen LLMs: A Tale of Two Approaches
Mar 17, 2024Two approaches have emerged to input images into large language models (LLMs). The first is to caption images into natural language. The second is to map image feature embeddings into the domain of the LLM and pass the mapped embeddings directly to the LLM. The majority of recent few-shot multimodal work reports performance using architectures that employ variations of one of these two approaches. But they overlook an important comparison between them. We design a controlled and focused experiment to compare these two approaches to few-shot visual question answering (VQA) with LLMs. Our findings indicate that for Flan-T5 XL, a 3B parameter LLM, connecting visual embeddings directly to the LLM embedding space does not guarantee improved performance over using image captions. In the zero-shot regime, we find using textual image captions is better. In the few-shot regimes, how the in-context examples are selected determines which is better.