 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo Hybrid: From Theory to Practice and Back
Apr 07, 2026Recent work has demonstrated the potential of non-transformer language models, especially linear recurrent neural networks (RNNs) and hybrid models that mix recurrence and attention. Yet there is no consensus on whether the potential benefits of these new architectures justify the risk and effort of scaling them up. To address this, we provide evidence for the advantages of hybrid models over pure transformers on several fronts. First, theoretically, we show that hybrid models do not merely inherit the expressivity of transformers and linear RNNs, but can express tasks beyond both, such as code execution. Putting this theory to practice, we train Olmo Hybrid, a 7B-parameter model largely comparable to Olmo 3 7B but with the sliding window layers replaced by Gated DeltaNet layers. We show that Olmo Hybrid outperforms Olmo 3 across standard pretraining and mid-training evaluations, demonstrating the benefit of hybrid models in a controlled, large-scale setting. We find that the hybrid model scales significantly more efficiently than the transformer, explaining its higher performance. However, its unclear why greater expressivity on specific formal problems should result in better scaling or superior performance on downstream tasks unrelated to those problems. To explain this apparent gap, we return to theory and argue why increased expressivity should translate to better scaling efficiency, completing the loop. Overall, our results suggest that hybrid models mixing attention and recurrent layers are a powerful extension to the language modeling paradigm: not merely to reduce memory during inference, but as a fundamental way to obtain more expressive models that scale better during pretraining.
Bolmo: Byteifying the Next Generation of Language Models
Dec 17, 2025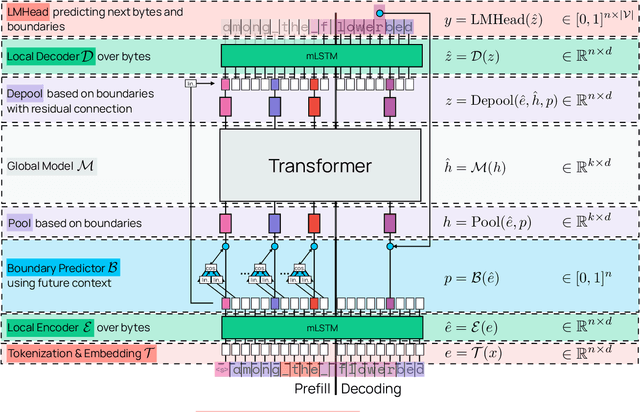
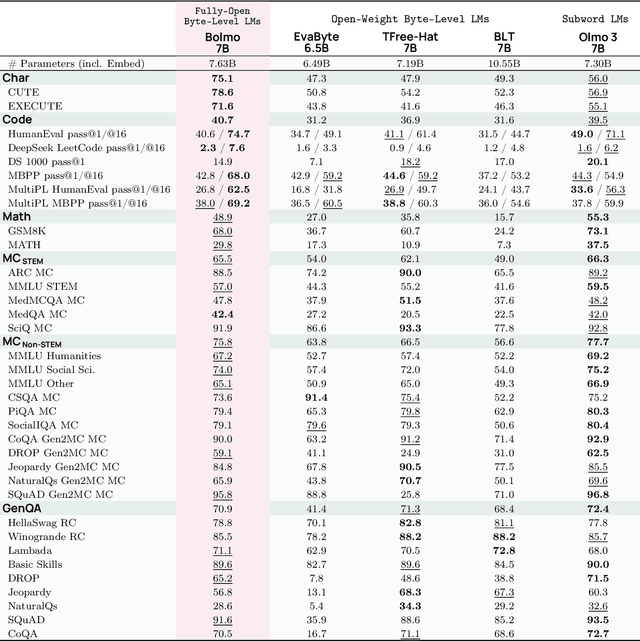
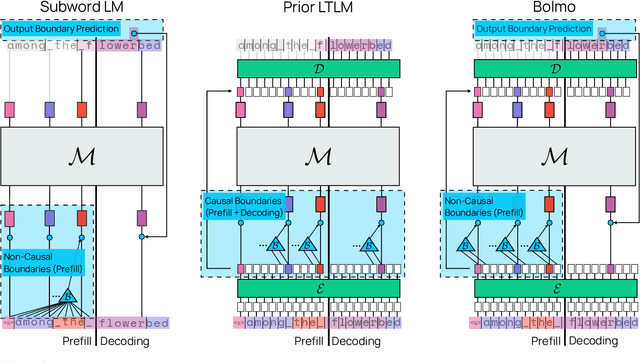
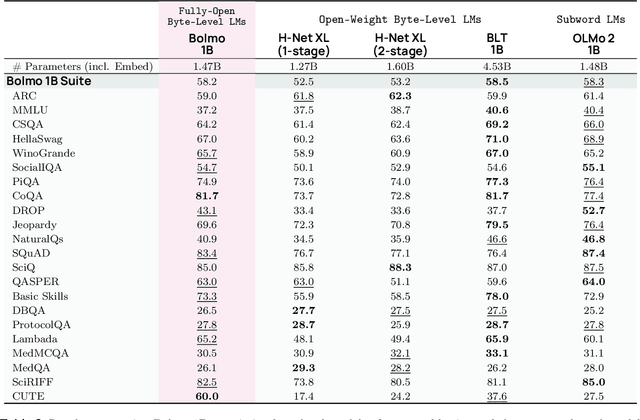
We introduce Bolmo, the first family of competitive fully open byte-level language models (LMs) at the 1B and 7B parameter scales. In contrast to prior research on byte-level LMs, which focuses predominantly on training from scratch, we train Bolmo by byteifying existing subword-level LMs. Byteification enables overcoming the limitations of subword tokenization - such as insufficient character understanding and efficiency constraints due to the fixed subword vocabulary - while performing at the level of leading subword-level LMs. Bolmo is specifically designed for byteification: our architecture resolves a mismatch between the expressivity of prior byte-level architectures and subword-level LMs, which makes it possible to employ an effective exact distillation objective between Bolmo and the source subword model. This allows for converting a subword-level LM to a byte-level LM by investing less than 1\% of a typical pretraining token budget. Bolmo substantially outperforms all prior byte-level LMs of comparable size, and outperforms the source subword-level LMs on character understanding and, in some cases, coding, while coming close to matching the original LMs' performance on other tasks. Furthermore, we show that Bolmo can achieve inference speeds competitive with subword-level LMs by training with higher token compression ratios, and can be cheaply and effectively post-trained by leveraging the existing ecosystem around the source subword-level LM. Our results finally make byte-level LMs a practical choice competitive with subword-level LMs across a wide set of use cases.
Cross-Tokenizer Distillation via Approximate Likelihood Matching
Mar 27, 2025Distillation has shown remarkable success in transferring knowledge from a Large Language Model (LLM) teacher to a student LLM. However, current distillation methods predominantly require the same tokenizer between the teacher and the student, restricting their applicability to only a small subset of teacher-student pairs. In this work, we develop a cross-tokenizer distillation method to solve this crucial deficiency. Our method is the first to enable cross-tokenizer distillation without a next-token prediction loss as the main objective, instead purely maximizing the student predictions' similarity to the teacher's predictions (known as pure distillation), while also being robust to large mismatches between the teacher and the student tokenizer function and vocabulary. Empirically, our method enables substantially improved performance as tested on two use cases. First, we show that viewing tokenizer transfer as self-distillation enables unprecedently effective transfer across tokenizers. We transfer (subword-level) Llama and Gemma models to byte-level tokenization more effectively than prior methods transfer to a similar subword tokenizer under a comparable training budget. Transferring different base models to the same tokenizer also enables ensembling them (e.g., via averaging their predicted probabilities) which boosts performance. Second, we use our cross-tokenizer distillation method to distil a large maths-specialized LLM into a smaller model, achieving competitive maths problem-solving performance. Overall, our results make substantial strides toward better adaptability and enhanced interaction between different LLMs.
Retrofitting (Large) Language Models with Dynamic Tokenization
Nov 27, 2024Current language models (LMs) use a fixed, static subword tokenizer. This choice, often taken for granted, typically results in degraded efficiency and capabilities in languages other than English, and makes it challenging to apply LMs to new domains or languages. To address these issues, we propose retrofitting LMs with dynamic tokenization: a way to dynamically decide on token boundaries based on the input text. For encoder-style models, we introduce a subword-merging algorithm inspired by byte-pair encoding (BPE), but at a batch level. We merge frequent subword sequences in a batch, then apply a pretrained embedding-prediction hypernetwork to compute the token embeddings on-the-fly. When applied with word-level boundaries, this on average reduces token sequence lengths by >20% across 14 languages on XNLI with XLM-R while degrading its task performance by less than 2%. For decoder-style models, we apply dynamic tokenization in two ways: 1) for prefilling, maintaining performance of Mistral-7B almost completely with up to 40% sequence reduction - relative to the word-level; and 2) via an approximate nearest neighbor index, achieving fast generation with a one million token vocabulary, demonstrating scalability to even larger, dynamic vocabularies. Overall, our findings show that dynamic tokenization substantially improves inference speed and promotes fairness across languages, making a leap towards overcoming the limitations of static tokenization and enabling more equitable and adaptable LMs.
Segment Any Text: A Universal Approach for Robust, Efficient and Adaptable Sentence Segmentation
Jun 24, 2024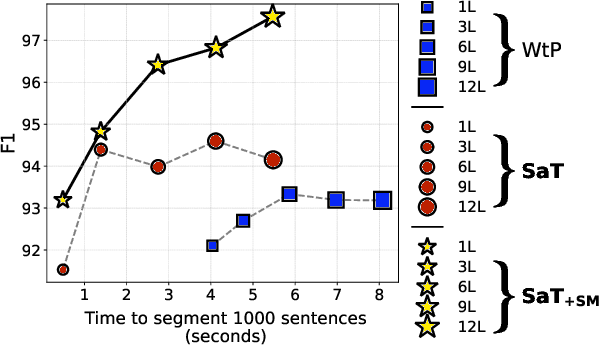
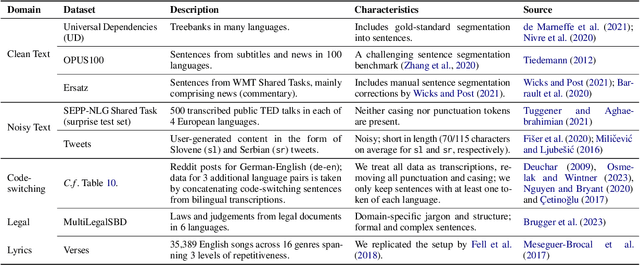
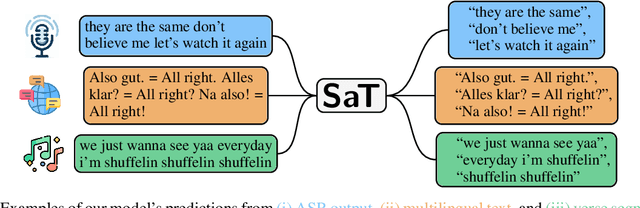
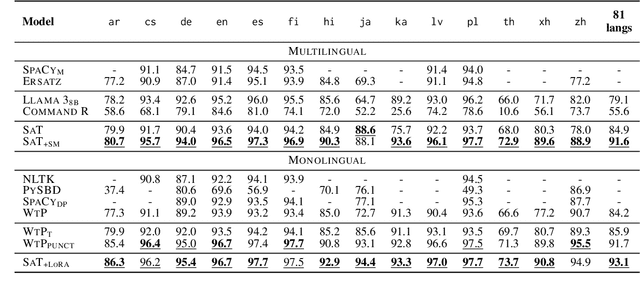
Segmenting text into sentences plays an early and crucial role in many NLP systems. This is commonly achieved by using rule-based or statistical methods relying on lexical features such as punctuation. Although some recent works no longer exclusively rely on punctuation, we find that no prior method achieves all of (i) robustness to missing punctuation, (ii) effective adaptability to new domains, and (iii) high efficiency. We introduce a new model - Segment any Text (SaT) - to solve this problem. To enhance robustness, we propose a new pretraining scheme that ensures less reliance on punctuation. To address adaptability, we introduce an extra stage of parameter-efficient fine-tuning, establishing state-of-the-art performance in distinct domains such as verses from lyrics and legal documents. Along the way, we introduce architectural modifications that result in a threefold gain in speed over the previous state of the art and solve spurious reliance on context far in the future. Finally, we introduce a variant of our model with fine-tuning on a diverse, multilingual mixture of sentence-segmented data, acting as a drop-in replacement and enhancement for existing segmentation tools. Overall, our contributions provide a universal approach for segmenting any text. Our method outperforms all baselines - including strong LLMs - across 8 corpora spanning diverse domains and languages, especially in practically relevant situations where text is poorly formatted. Our models and code, including documentation, are available at https://huggingface.co/segment-any-text under the MIT license.
Zero-Shot Tokenizer Transfer
May 13, 2024

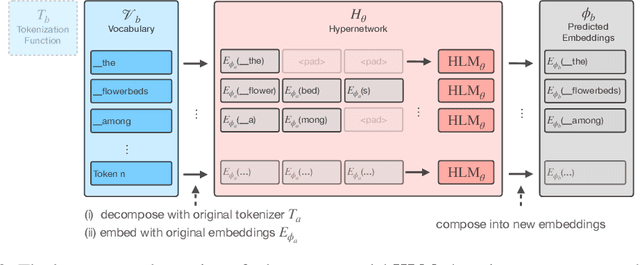

Language models (LMs) are bound to their tokenizer, which maps raw text to a sequence of vocabulary items (tokens). This restricts their flexibility: for example, LMs trained primarily on English may still perform well in other natural and programming languages, but have vastly decreased efficiency due to their English-centric tokenizer. To mitigate this, we should be able to swap the original LM tokenizer with an arbitrary one, on the fly, without degrading performance. Hence, in this work we define a new problem: Zero-Shot Tokenizer Transfer (ZeTT). The challenge at the core of ZeTT is finding embeddings for the tokens in the vocabulary of the new tokenizer. Since prior heuristics for initializing embeddings often perform at chance level in a ZeTT setting, we propose a new solution: we train a hypernetwork taking a tokenizer as input and predicting the corresponding embeddings. We empirically demonstrate that the hypernetwork generalizes to new tokenizers both with encoder (e.g., XLM-R) and decoder LLMs (e.g., Mistral-7B). Our method comes close to the original models' performance in cross-lingual and coding tasks while markedly reducing the length of the tokenized sequence. We also find that the remaining gap can be quickly closed by continued training on less than 1B tokens. Finally, we show that a ZeTT hypernetwork trained for a base (L)LM can also be applied to fine-tuned variants without extra training. Overall, our results make substantial strides toward detaching LMs from their tokenizer.
Where's the Point? Self-Supervised Multilingual Punctuation-Agnostic Sentence Segmentation
May 30, 2023

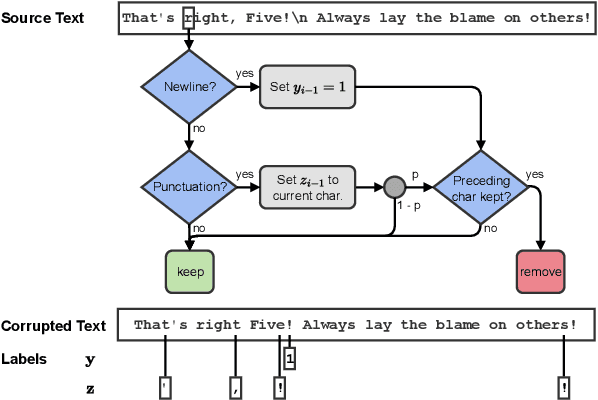
Many NLP pipelines split text into sentences as one of the crucial preprocessing steps. Prior sentence segmentation tools either rely on punctuation or require a considerable amount of sentence-segmented training data: both central assumptions might fail when porting sentence segmenters to diverse languages on a massive scale. In this work, we thus introduce a multilingual punctuation-agnostic sentence segmentation method, currently covering 85 languages, trained in a self-supervised fashion on unsegmented text, by making use of newline characters which implicitly perform segmentation into paragraphs. We further propose an approach that adapts our method to the segmentation in a given corpus by using only a small number (64-256) of sentence-segmented examples. The main results indicate that our method outperforms all the prior best sentence-segmentation tools by an average of 6.1% F1 points. Furthermore, we demonstrate that proper sentence segmentation has a point: the use of a (powerful) sentence segmenter makes a considerable difference for a downstream application such as machine translation (MT). By using our method to match sentence segmentation to the segmentation used during training of MT models, we achieve an average improvement of 2.3 BLEU points over the best prior segmentation tool, as well as massive gains over a trivial segmenter that splits text into equally sized blocks.
CompoundPiece: Evaluating and Improving Decompounding Performance of Language Models
May 23, 2023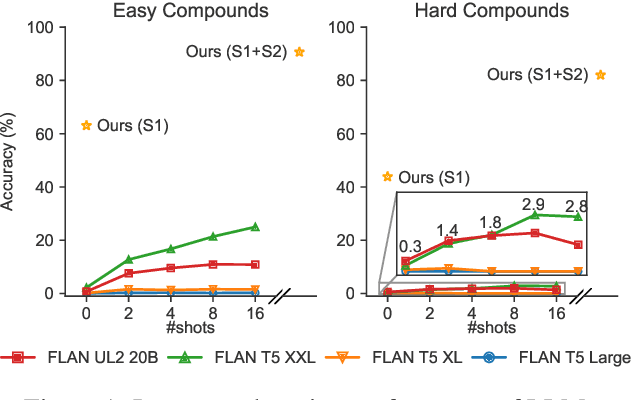
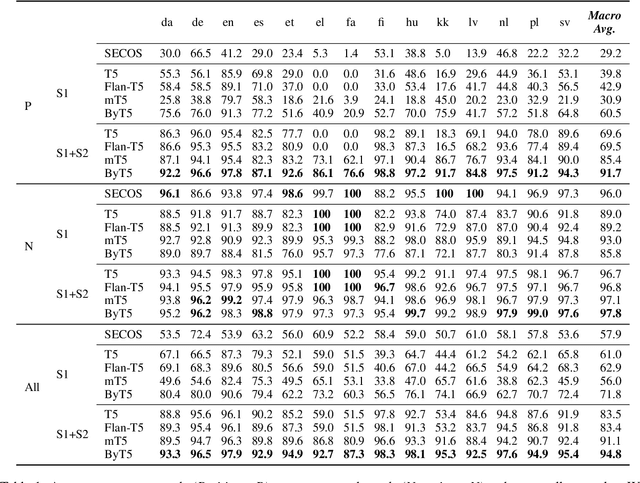

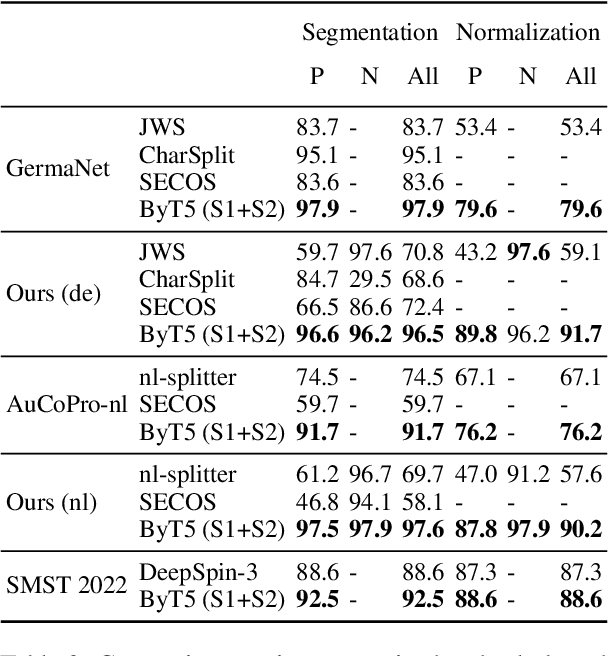
While many languages possess processes of joining two or more words to create compound words, previous studies have been typically limited only to languages with excessively productive compound formation (e.g., German, Dutch) and there is no public dataset containing compound and non-compound words across a large number of languages. In this work, we systematically study decompounding, the task of splitting compound words into their constituents, at a wide scale. We first address the data gap by introducing a dataset of 255k compound and non-compound words across 56 diverse languages obtained from Wiktionary. We then use this dataset to evaluate an array of Large Language Models (LLMs) on the decompounding task. We find that LLMs perform poorly, especially on words which are tokenized unfavorably by subword tokenization. We thus introduce a novel methodology to train dedicated models for decompounding. The proposed two-stage procedure relies on a fully self-supervised objective in the first stage, while the second, supervised learning stage optionally fine-tunes the model on the annotated Wiktionary data. Our self-supervised models outperform the prior best unsupervised decompounding models by 13.9% accuracy on average. Our fine-tuned models outperform all prior (language-specific) decompounding tools. Furthermore, we use our models to leverage decompounding during the creation of a subword tokenizer, which we refer to as CompoundPiece. CompoundPiece tokenizes compound words more favorably on average, leading to improved performance on decompounding over an otherwise equivalent model using SentencePiece tokenization.
HumSet: Dataset of Multilingual Information Extraction and Classification for Humanitarian Crisis Response
Oct 10, 2022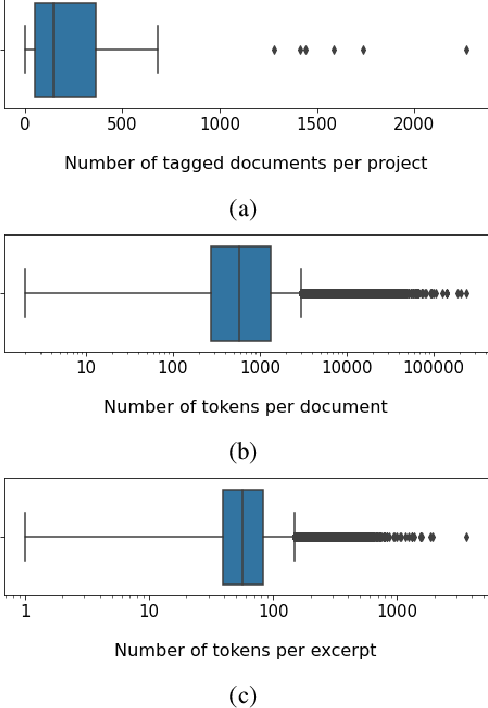

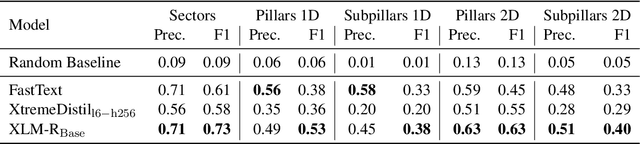
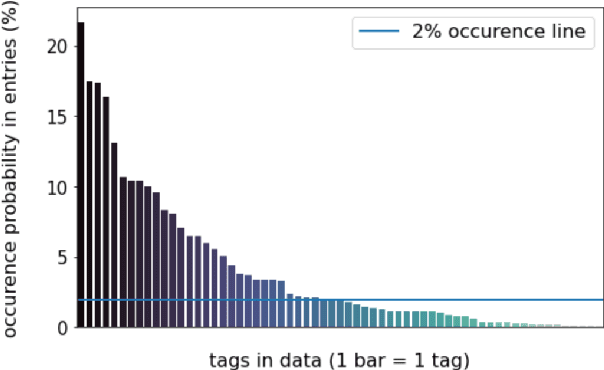
Timely and effective response to humanitarian crises requires quick and accurate analysis of large amounts of text data - a process that can highly benefit from expert - assisted NLP systems trained on validated and annotated data in the humanitarian response domain. To enable creation of such NLP systems, we introduce and release HumSet, a novel and rich multilingual dataset of humanitarian response documents annotated by experts in the humanitarian response community. The dataset provides documents in three languages (English, French, Spanish) and covers a variety of humanitarian crises from 2018 to 2021 across the globe. For each document, HumSet provides selected snippets (entries) as well as assigned classes to each entry annotated using common humanitarian information analysis frameworks. HumSet also provides novel and challenging entry extraction and multi-label entry classification tasks. In this paper, we take a first step towards approaching these tasks and conduct a set of experiments on Pre-trained Language Models (PLM) to establish strong baselines for future research in this domain. The dataset is available at The dataset is available at https: //blog.thedeep.io/humset/.
WECHSEL: Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models
Dec 13, 2021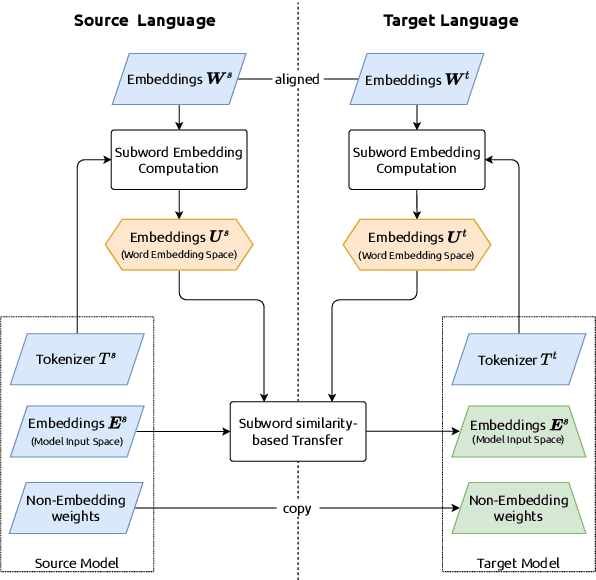
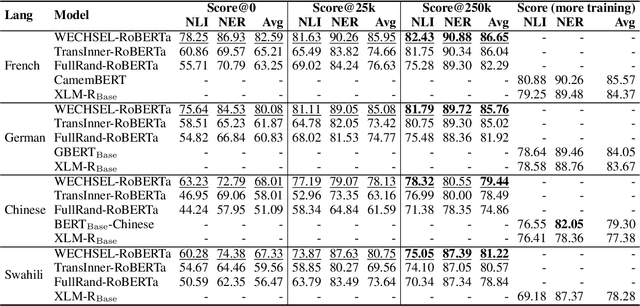
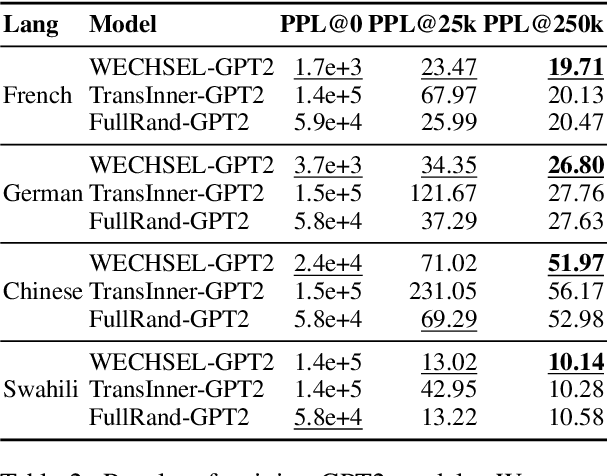
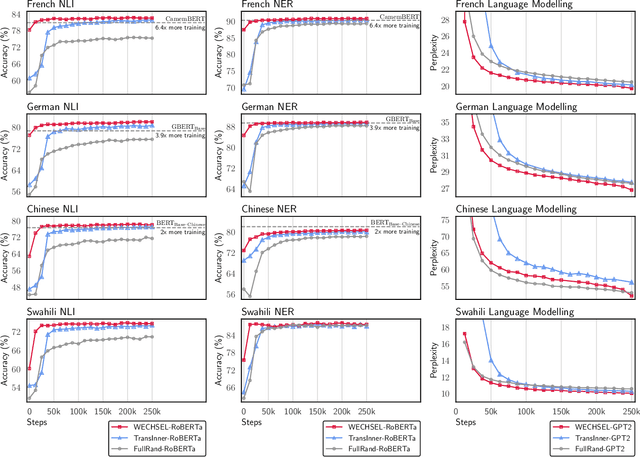
Recently, large pretrained language models (LMs) have gained popularity. Training these models requires ever more computational resources and most of the existing models are trained on English text only. It is exceedingly expensive to train these models in other languages. To alleviate this problem, we introduce a method -- called WECHSEL -- to transfer English models to new languages. We exchange the tokenizer of the English model with a tokenizer in the target language and initialize token embeddings such that they are close to semantically similar English tokens by utilizing multilingual static word embeddings covering English and the target language. We use WECHSEL to transfer GPT-2 and RoBERTa models to 4 other languages (French, German, Chinese and Swahili). WECHSEL improves over a previously proposed method for cross-lingual parameter transfer and outperforms models of comparable size trained from scratch in the target language with up to 64x less training effort. Our method makes training large language models for new languages more accessible and less damaging to the environment. We make our code and models publicly available.