 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Domain Knowledge for Inclusive and Bias-aware Humanitarian Response Entry Classification
May 30, 2023Accurate and rapid situation analysis during humanitarian crises is critical to delivering humanitarian aid efficiently and is fundamental to humanitarian imperatives and the Leave No One Behind (LNOB) principle. This data analysis can highly benefit from language processing systems, e.g., by classifying the text data according to a humanitarian ontology. However, approaching this by simply fine-tuning a generic large language model (LLM) involves considerable practical and ethical issues, particularly the lack of effectiveness on data-sparse and complex subdomains, and the encoding of societal biases and unwanted associations. In this work, we aim to provide an effective and ethically-aware system for humanitarian data analysis. We approach this by (1) introducing a novel architecture adjusted to the humanitarian analysis framework, (2) creating and releasing a novel humanitarian-specific LLM called HumBert, and (3) proposing a systematic way to measure and mitigate biases. Our experiments' results show the better performance of our approach on zero-shot and full-training settings in comparison with strong baseline models, while also revealing the existence of biases in the resulting LLMs. Utilizing a targeted counterfactual data augmentation approach, we significantly reduce these biases without compromising performance.
HumSet: Dataset of Multilingual Information Extraction and Classification for Humanitarian Crisis Response
Oct 10, 2022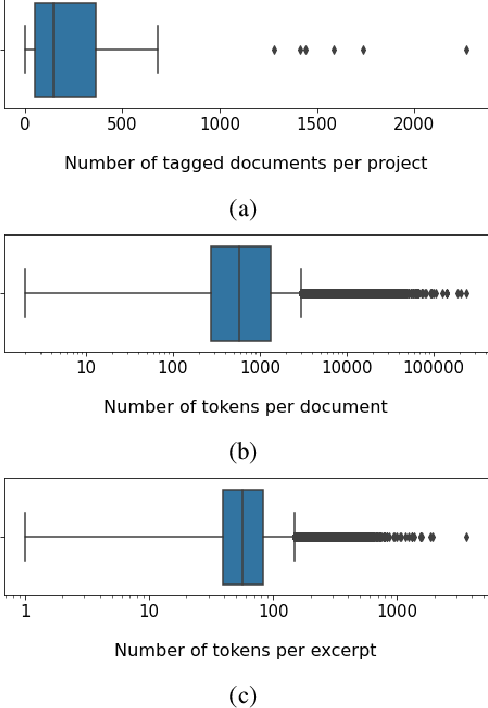

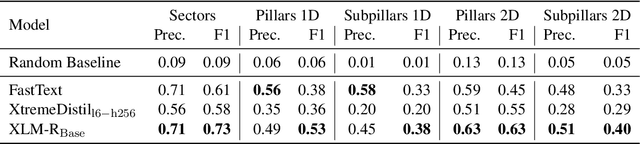
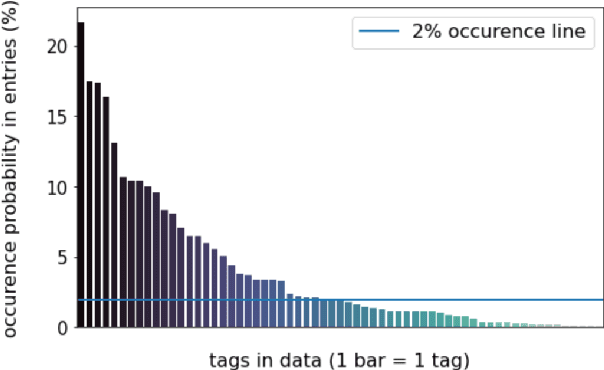
Timely and effective response to humanitarian crises requires quick and accurate analysis of large amounts of text data - a process that can highly benefit from expert - assisted NLP systems trained on validated and annotated data in the humanitarian response domain. To enable creation of such NLP systems, we introduce and release HumSet, a novel and rich multilingual dataset of humanitarian response documents annotated by experts in the humanitarian response community. The dataset provides documents in three languages (English, French, Spanish) and covers a variety of humanitarian crises from 2018 to 2021 across the globe. For each document, HumSet provides selected snippets (entries) as well as assigned classes to each entry annotated using common humanitarian information analysis frameworks. HumSet also provides novel and challenging entry extraction and multi-label entry classification tasks. In this paper, we take a first step towards approaching these tasks and conduct a set of experiments on Pre-trained Language Models (PLM) to establish strong baselines for future research in this domain. The dataset is available at The dataset is available at https: //blog.thedeep.io/humset/.