 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom scratch to silver: Creating trustworthy training data for patent-SDG classification using Large Language Models
Sep 11, 2025Classifying patents by their relevance to the UN Sustainable Development Goals (SDGs) is crucial for tracking how innovation addresses global challenges. However, the absence of a large, labeled dataset limits the use of supervised learning. Existing methods, such as keyword searches, transfer learning, and citation-based heuristics, lack scalability and generalizability. This paper frames patent-to-SDG classification as a weak supervision problem, using citations from patents to SDG-tagged scientific publications (NPL citations) as a noisy initial signal. To address its sparsity and noise, we develop a composite labeling function (LF) that uses large language models (LLMs) to extract structured concepts, namely functions, solutions, and applications, from patents and SDG papers based on a patent ontology. Cross-domain similarity scores are computed and combined using a rank-based retrieval approach. The LF is calibrated via a custom positive-only loss that aligns with known NPL-SDG links without penalizing discovery of new SDG associations. The result is a silver-standard, soft multi-label dataset mapping patents to SDGs, enabling the training of effective multi-label regression models. We validate our approach through two complementary strategies: (1) internal validation against held-out NPL-based labels, where our method outperforms several baselines including transformer-based models, and zero-shot LLM; and (2) external validation using network modularity in patent citation, co-inventor, and co-applicant graphs, where our labels reveal greater thematic, cognitive, and organizational coherence than traditional technological classifications. These results show that weak supervision and semantic alignment can enhance SDG classification at scale.
Leveraging Domain Knowledge for Inclusive and Bias-aware Humanitarian Response Entry Classification
May 30, 2023Accurate and rapid situation analysis during humanitarian crises is critical to delivering humanitarian aid efficiently and is fundamental to humanitarian imperatives and the Leave No One Behind (LNOB) principle. This data analysis can highly benefit from language processing systems, e.g., by classifying the text data according to a humanitarian ontology. However, approaching this by simply fine-tuning a generic large language model (LLM) involves considerable practical and ethical issues, particularly the lack of effectiveness on data-sparse and complex subdomains, and the encoding of societal biases and unwanted associations. In this work, we aim to provide an effective and ethically-aware system for humanitarian data analysis. We approach this by (1) introducing a novel architecture adjusted to the humanitarian analysis framework, (2) creating and releasing a novel humanitarian-specific LLM called HumBert, and (3) proposing a systematic way to measure and mitigate biases. Our experiments' results show the better performance of our approach on zero-shot and full-training settings in comparison with strong baseline models, while also revealing the existence of biases in the resulting LLMs. Utilizing a targeted counterfactual data augmentation approach, we significantly reduce these biases without compromising performance.
HumSet: Dataset of Multilingual Information Extraction and Classification for Humanitarian Crisis Response
Oct 10, 2022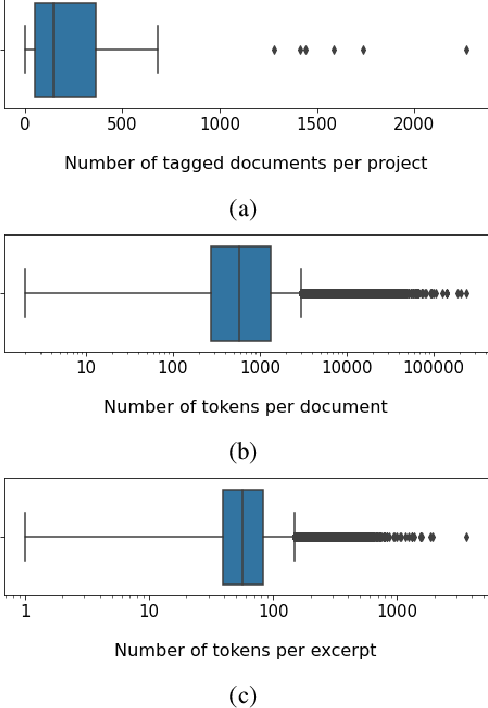

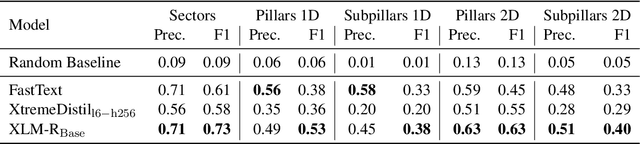
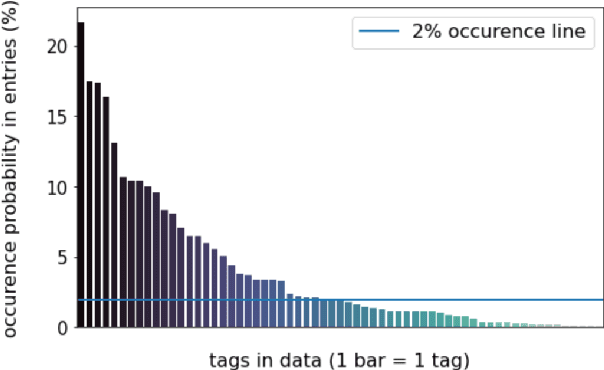
Timely and effective response to humanitarian crises requires quick and accurate analysis of large amounts of text data - a process that can highly benefit from expert - assisted NLP systems trained on validated and annotated data in the humanitarian response domain. To enable creation of such NLP systems, we introduce and release HumSet, a novel and rich multilingual dataset of humanitarian response documents annotated by experts in the humanitarian response community. The dataset provides documents in three languages (English, French, Spanish) and covers a variety of humanitarian crises from 2018 to 2021 across the globe. For each document, HumSet provides selected snippets (entries) as well as assigned classes to each entry annotated using common humanitarian information analysis frameworks. HumSet also provides novel and challenging entry extraction and multi-label entry classification tasks. In this paper, we take a first step towards approaching these tasks and conduct a set of experiments on Pre-trained Language Models (PLM) to establish strong baselines for future research in this domain. The dataset is available at The dataset is available at https: //blog.thedeep.io/humset/.
Top-Rank-Focused Adaptive Vote Collection for the Evaluation of Domain-Specific Semantic Models
Oct 09, 2020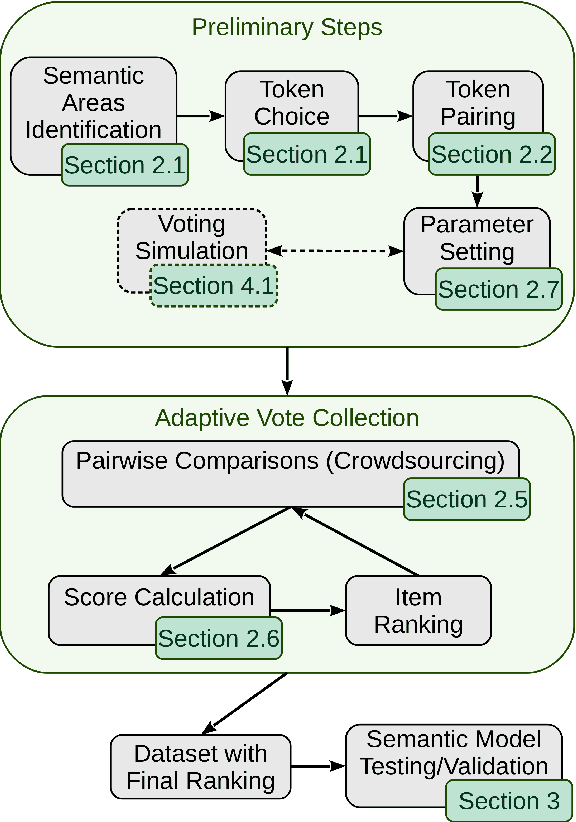
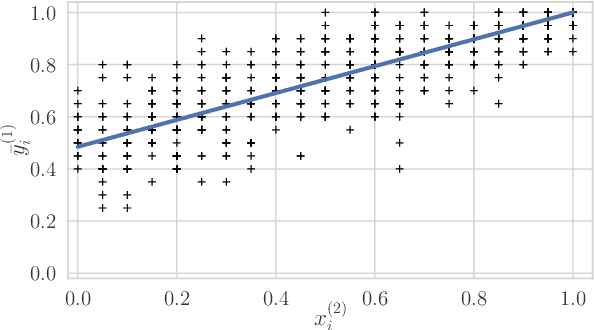
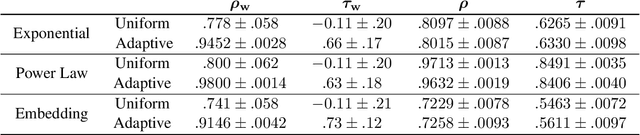
The growth of domain-specific applications of semantic models, boosted by the recent achievements of unsupervised embedding learning algorithms, demands domain-specific evaluation datasets. In many cases, content-based recommenders being a prime example, these models are required to rank words or texts according to their semantic relatedness to a given concept, with particular focus on top ranks. In this work, we give a threefold contribution to address these requirements: (i) we define a protocol for the construction, based on adaptive pairwise comparisons, of a relatedness-based evaluation dataset tailored on the available resources and optimized to be particularly accurate in top-rank evaluation; (ii) we define appropriate metrics, extensions of well-known ranking correlation coefficients, to evaluate a semantic model via the aforementioned dataset by taking into account the greater significance of top ranks. Finally, (iii) we define a stochastic transitivity model to simulate semantic-driven pairwise comparisons, which confirms the effectiveness of the proposed dataset construction protocol.