 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReBoot: Encrypted Training of Deep Neural Networks with CKKS Bootstrapping
Jun 24, 2025Growing concerns over data privacy underscore the need for deep learning methods capable of processing sensitive information without compromising confidentiality. Among privacy-enhancing technologies, Homomorphic Encryption (HE) stands out by providing post-quantum cryptographic security and end-to-end data protection, safeguarding data even during computation. While Deep Neural Networks (DNNs) have gained attention in HE settings, their use has largely been restricted to encrypted inference. Prior research on encrypted training has primarily focused on logistic regression or has relied on multi-party computation to enable model fine-tuning. This stems from the substantial computational overhead and algorithmic complexity involved in DNNs training under HE. In this paper, we present ReBoot, the first framework to enable fully encrypted and non-interactive training of DNNs. Built upon the CKKS scheme, ReBoot introduces a novel HE-compliant neural network architecture based on local error signals, specifically designed to minimize multiplicative depth and reduce noise accumulation. ReBoot employs a tailored packing strategy that leverages real-number arithmetic via SIMD operations, significantly lowering both computational and memory overhead. Furthermore, by integrating approximate bootstrapping, ReBoot learning algorithm supports effective training of arbitrarily deep multi-layer perceptrons, making it well-suited for machine learning as-a-service. ReBoot is evaluated on both image recognition and tabular benchmarks, achieving accuracy comparable to 32-bit floating-point plaintext training while enabling fully encrypted training. It improves test accuracy by up to +3.27% over encrypted logistic regression, and up to +6.83% over existing encrypted DNN frameworks, while reducing training latency by up to 8.83x. ReBoot is made available to the scientific community as a public repository.
Training Multi-Layer Binary Neural Networks With Local Binary Error Signals
Nov 28, 2024Binary Neural Networks (BNNs) hold the potential for significantly reducing computational complexity and memory demand in machine and deep learning. However, most successful training algorithms for BNNs rely on quantization-aware floating-point Stochastic Gradient Descent (SGD), with full-precision hidden weights used during training. The binarized weights are only used at inference time, hindering the full exploitation of binary operations during the training process. In contrast to the existing literature, we introduce, for the first time, a multi-layer training algorithm for BNNs that does not require the computation of back-propagated full-precision gradients. Specifically, the proposed algorithm is based on local binary error signals and binary weight updates, employing integer-valued hidden weights that serve as a synaptic metaplasticity mechanism, thereby establishing it as a neurobiologically plausible algorithm. The binary-native and gradient-free algorithm proposed in this paper is capable of training binary multi-layer perceptrons (BMLPs) with binary inputs, weights, and activations, by using exclusively XNOR, Popcount, and increment/decrement operations, hence effectively paving the way for a new class of operation-optimized training algorithms. Experimental results on BMLPs fully trained in a binary-native and gradient-free manner on multi-class image classification benchmarks demonstrate an accuracy improvement of up to +13.36% compared to the fully binary state-of-the-art solution, showing minimal accuracy degradation compared to the same architecture trained with full-precision SGD and floating-point weights, activations, and inputs. The proposed algorithm is made available to the scientific community as a public repository.
TIFeD: a Tiny Integer-based Federated learning algorithm with Direct feedback alignment
Nov 25, 2024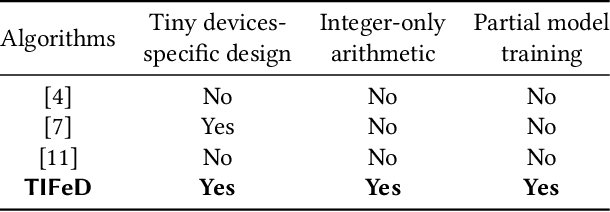
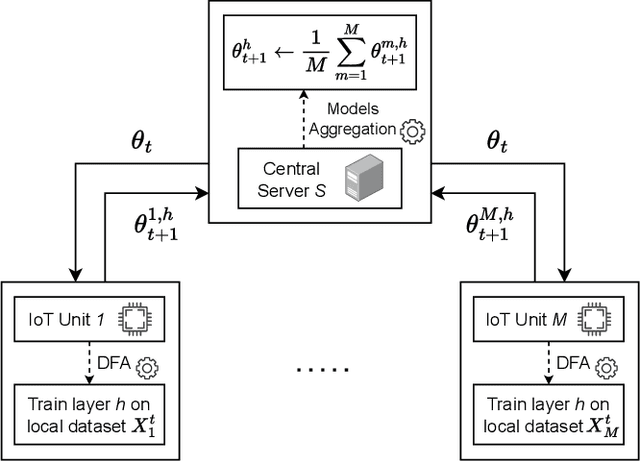

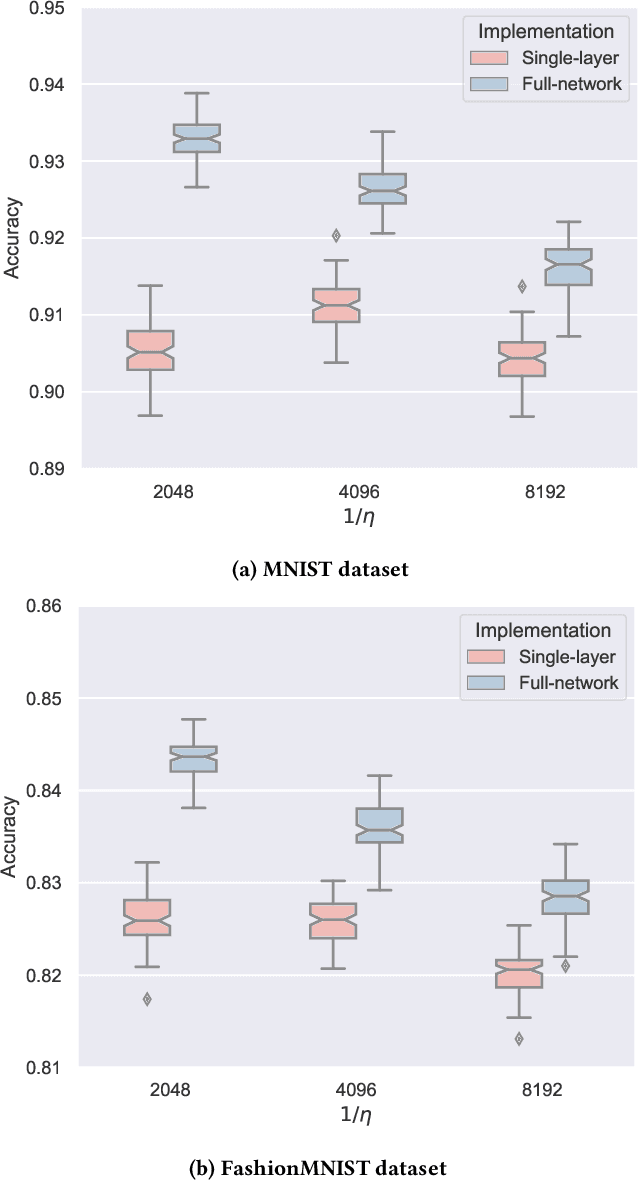
Training machine and deep learning models directly on extremely resource-constrained devices is the next challenge in the field of tiny machine learning. The related literature in this field is very limited, since most of the solutions focus only on on-device inference or model adaptation through online learning, leaving the training to be carried out on external Cloud services. An interesting technological perspective is to exploit Federated Learning (FL), which allows multiple devices to collaboratively train a shared model in a distributed way. However, the main drawback of state-of-the-art FL algorithms is that they are not suitable for running on tiny devices. For the first time in the literature, in this paper we introduce TIFeD, a Tiny Integer-based Federated learning algorithm with Direct Feedback Alignment (DFA) entirely implemented by using an integer-only arithmetic and being specifically designed to operate on devices with limited resources in terms of memory, computation and energy. Besides the traditional full-network operating modality, in which each device of the FL setting trains the entire neural network on its own local data, we propose an innovative single-layer TIFeD implementation, which enables each device to train only a portion of the neural network model and opens the door to a new way of distributing the learning procedure across multiple devices. The experimental results show the feasibility and effectiveness of the proposed solution. The proposed TIFeD algorithm, with its full-network and single-layer implementations, is made available to the scientific community as a public repository.
NITRO-D: Native Integer-only Training of Deep Convolutional Neural Networks
Jul 16, 2024Quantization has become increasingly pivotal in addressing the steadily increasing computational and memory requirements of Deep Neural Networks (DNNs). By reducing the number of bits used to represent weights and activations (typically from 32-bit floating-point to 16-bit or 8-bit integers), quantization reduces the memory footprint, energy consumption, and execution time of DNN models. However, traditional quantization methods typically focus on the inference of DNNs, while the training process still relies on floating-point operations. To date, only one work in the literature has addressed integer-only training for Multi-Layer Perceptron (MLP) architectures. This work introduces NITRO-D, a new framework for training arbitrarily deep integer-only Convolutional Neural Networks (CNNs) that operate entirely< in the integer-only domain for both training and inference. NITRO-D is the first framework in the literature enabling the training of integer-only CNNs without the need to introduce a quantization scheme. Specifically, NITRO-D introduces a novel architecture integrating multiple integer local-loss blocks, which include the proposed NITRO Scaling Layer and the NITRO-ReLU activation function. Additionally, it introduces a novel integer-only learning algorithm derived from Local Error Signals (LES), utilizing IntegerSGD, an optimizer specifically designed to operate in an integer-only context. NITRO-D is implemented in an open-source Python library. Extensive experimental evaluations demonstrate its effectiveness across several state-of-the-art image recognition datasets. Results show significant performance improvements from 2.47% to 5.96% for integer-only MLP architectures over the state-of-the-art solution, and the capability of training integer-only CNN architectures with minimal accuracy degradation from -0.15% to -4.22% compared to floating-point LES.
Fundamental Antisymmetric Mode Acoustic Resonator in Periodically Poled Piezoelectric Film Lithium Niobate
Aug 27, 2023
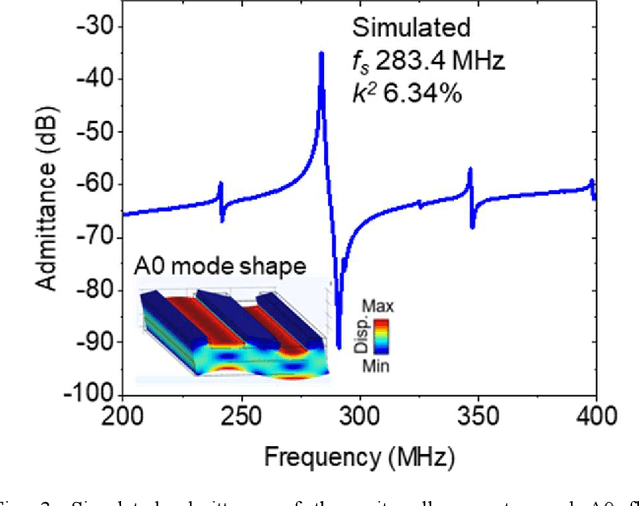

Radio frequency (RF) acoustic resonators have long been used for signal processing and sensing. Devices that integrate acoustic resonators benefit from their slow phase velocity (vp), in the order of 3 to 10 km/s, which allows miniaturization of the device. Regarding the subject of small form factor, acoustic resonators that operate at the so-called fundamental antisymmetric mode (A0), feature even slower vp (1 to 3 km/s), which allows for smaller devices. This work reports the design and fabrication of A0 mode resonators leveraging the advantages of periodically poled piezoelectricity (P3F) lithium niobate, which includes a pair of piezoelectric layers with opposite polarizations to mitigate the charge cancellation arising from opposite stress of A0 in the top and bottom piezoelectric layers. The fabricated device shows a quality factor (Q) of 800 and an electromechanical coupling (k2) of 3.29, resulting in a high figure of merit (FoM, Q times k2) of 26.3 at the resonant frequency of 294 MHz, demonstrating the first efficient A0 device in P3F platforms. The proposed A0 platform could enable miniature signal processing, sensing, and ultrasound transducer applications upon optimization.
A 5.3 GHz Al0.76Sc0.24N Two-Dimensional Resonant Rods Resonator with a kt2 of 23.9%
Apr 11, 2022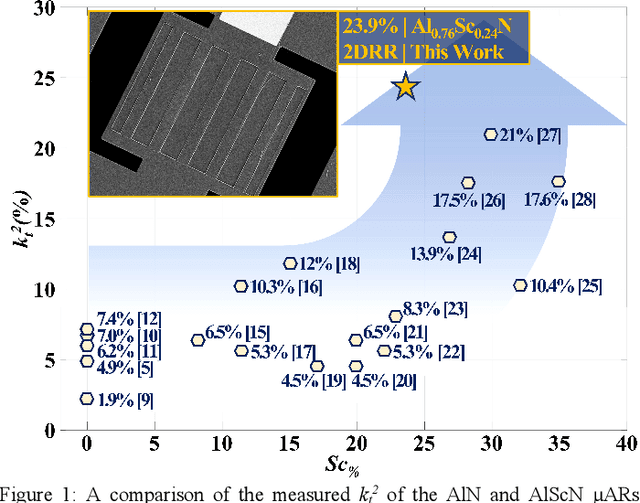
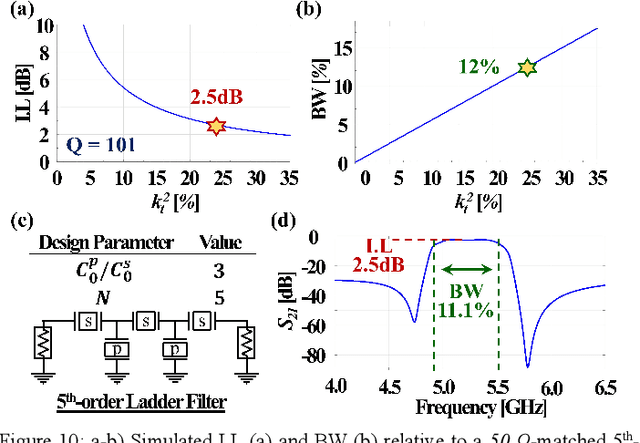
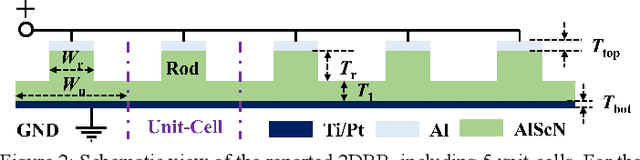
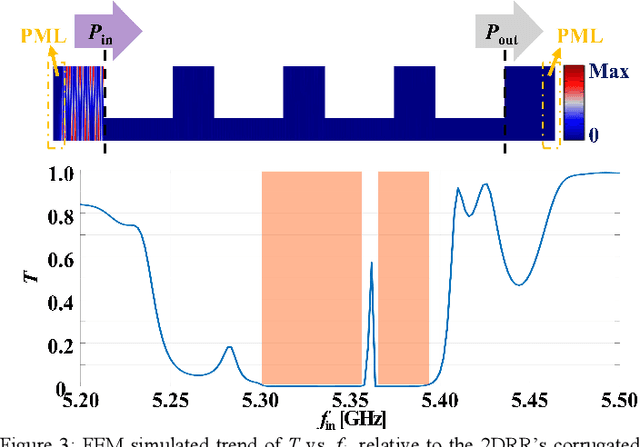
This work reports on the measured performance of an Aluminum Scandium Nitride (AlScN) Two-Dimensional Resonant Rods resonator (2DRR), fabricated by using a Sc-doping concentration of 24%, characterized by a low off-resonance impedance (~25 Ohm) and exhibiting a record electromechanical coupling coefficient (kt2) of 23.9% for AlScN resonators. In order to achieve such performance, we identified and relied on optimized deposition and etching processes for highly-doped AlScN films, aiming at achieving high crystalline quality, low density of abnormally oriented grains in the 2DRR's active region and sharp lateral sidewalls. Also, the 2DRR's unit-cell has been acoustically engineered to maximize the piezo-generated mechanical energy within each rod and to ensure a low transduction of spurious modes around resonance. Due to its unprecedented kt2, the reported 2DRR opens exciting scenarios towards the development of next generation monolithic integrated radio-frequency (RF) filtering components. In fact, we show that 5th-order 2DRR-based ladder filters with fractional bandwidths (BW) of ~11%, insertion-loss (I.L) values of ~2.5 dB and with >30 dB out-of-band rejections can now be envisioned, paving an unprecedented path towards the development of ultra-wide band (UWB) filters for next-generation Super-High-Frequency (SHF) radio front-ends.
Top-Rank-Focused Adaptive Vote Collection for the Evaluation of Domain-Specific Semantic Models
Oct 09, 2020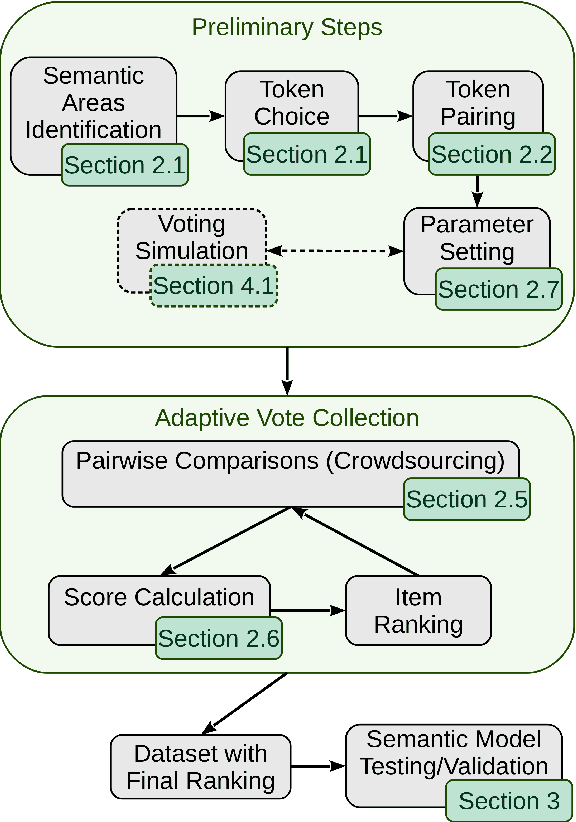
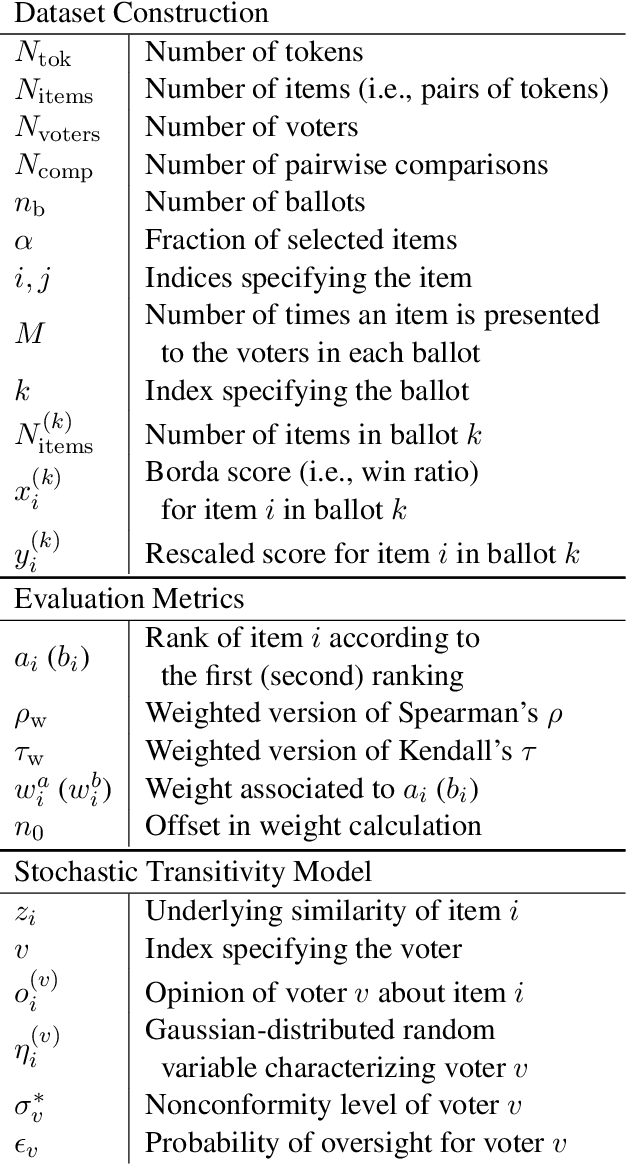
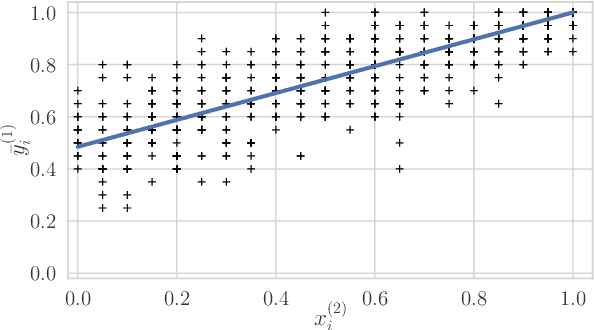
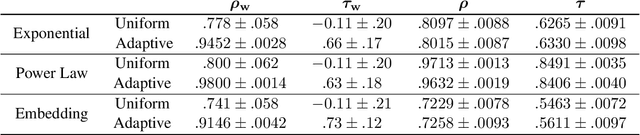
The growth of domain-specific applications of semantic models, boosted by the recent achievements of unsupervised embedding learning algorithms, demands domain-specific evaluation datasets. In many cases, content-based recommenders being a prime example, these models are required to rank words or texts according to their semantic relatedness to a given concept, with particular focus on top ranks. In this work, we give a threefold contribution to address these requirements: (i) we define a protocol for the construction, based on adaptive pairwise comparisons, of a relatedness-based evaluation dataset tailored on the available resources and optimized to be particularly accurate in top-rank evaluation; (ii) we define appropriate metrics, extensions of well-known ranking correlation coefficients, to evaluate a semantic model via the aforementioned dataset by taking into account the greater significance of top ranks. Finally, (iii) we define a stochastic transitivity model to simulate semantic-driven pairwise comparisons, which confirms the effectiveness of the proposed dataset construction protocol.