 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
DigiData: Training and Evaluating General-Purpose Mobile Control Agents
Nov 11, 2025AI agents capable of controlling user interfaces have the potential to transform human interaction with digital devices. To accelerate this transformation, two fundamental building blocks are essential: high-quality datasets that enable agents to achieve complex and human-relevant goals, and robust evaluation methods that allow researchers and practitioners to rapidly enhance agent performance. In this paper, we introduce DigiData, a large-scale, high-quality, diverse, multi-modal dataset designed for training mobile control agents. Unlike existing datasets, which derive goals from unstructured interactions, DigiData is meticulously constructed through comprehensive exploration of app features, resulting in greater diversity and higher goal complexity. Additionally, we present DigiData-Bench, a benchmark for evaluating mobile control agents on real-world complex tasks. We demonstrate that the commonly used step-accuracy metric falls short in reliably assessing mobile control agents and, to address this, we propose dynamic evaluation protocols and AI-powered evaluations as rigorous alternatives for agent assessment. Our contributions aim to significantly advance the development of mobile control agents, paving the way for more intuitive and effective human-device interactions.
Benchmarking Egocentric Multimodal Goal Inference for Assistive Wearable Agents
Oct 25, 2025There has been a surge of interest in assistive wearable agents: agents embodied in wearable form factors (e.g., smart glasses) who take assistive actions toward a user's goal/query (e.g. "Where did I leave my keys?"). In this work, we consider the important complementary problem of inferring that goal from multi-modal contextual observations. Solving this "goal inference" problem holds the promise of eliminating the effort needed to interact with such an agent. This work focuses on creating WAGIBench, a strong benchmark to measure progress in solving this problem using vision-language models (VLMs). Given the limited prior work in this area, we collected a novel dataset comprising 29 hours of multimodal data from 348 participants across 3,477 recordings, featuring ground-truth goals alongside accompanying visual, audio, digital, and longitudinal contextual observations. We validate that human performance exceeds model performance, achieving 93% multiple-choice accuracy compared with 84% for the best-performing VLM. Generative benchmark results that evaluate several families of modern vision-language models show that larger models perform significantly better on the task, yet remain far from practical usefulness, as they produce relevant goals only 55% of the time. Through a modality ablation, we show that models benefit from extra information in relevant modalities with minimal performance degradation from irrelevant modalities.
A 5.3 GHz Al0.76Sc0.24N Two-Dimensional Resonant Rods Resonator with a kt2 of 23.9%
Apr 11, 2022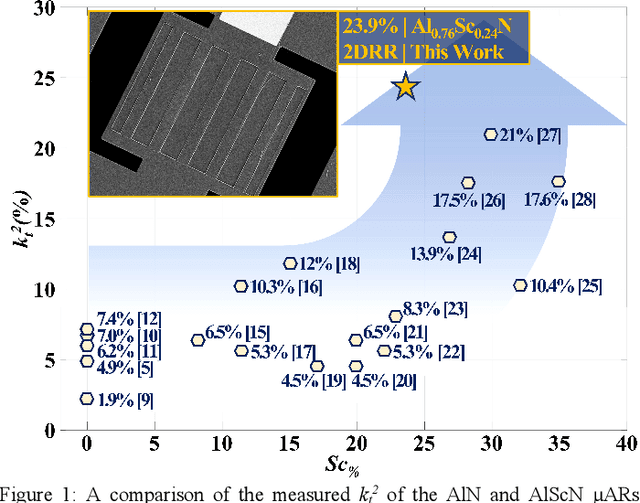
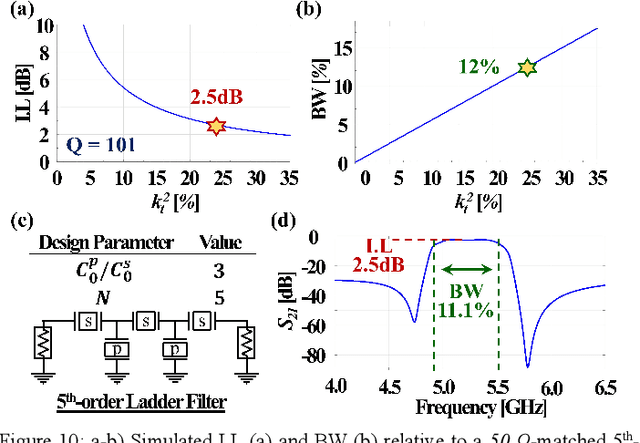
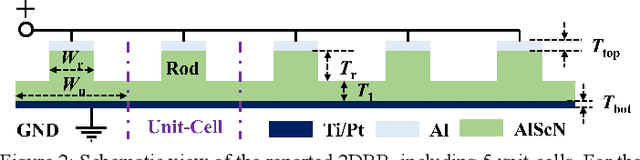
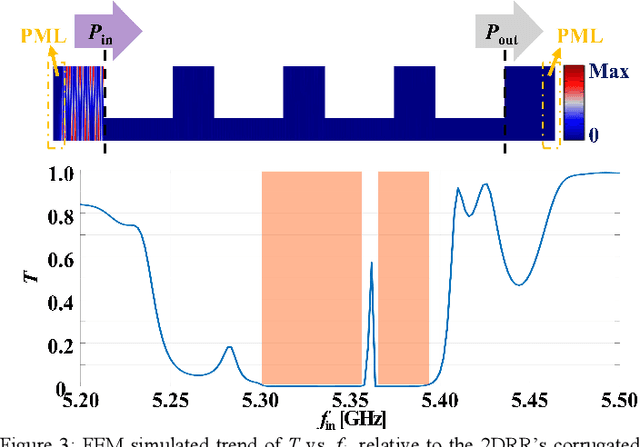
This work reports on the measured performance of an Aluminum Scandium Nitride (AlScN) Two-Dimensional Resonant Rods resonator (2DRR), fabricated by using a Sc-doping concentration of 24%, characterized by a low off-resonance impedance (~25 Ohm) and exhibiting a record electromechanical coupling coefficient (kt2) of 23.9% for AlScN resonators. In order to achieve such performance, we identified and relied on optimized deposition and etching processes for highly-doped AlScN films, aiming at achieving high crystalline quality, low density of abnormally oriented grains in the 2DRR's active region and sharp lateral sidewalls. Also, the 2DRR's unit-cell has been acoustically engineered to maximize the piezo-generated mechanical energy within each rod and to ensure a low transduction of spurious modes around resonance. Due to its unprecedented kt2, the reported 2DRR opens exciting scenarios towards the development of next generation monolithic integrated radio-frequency (RF) filtering components. In fact, we show that 5th-order 2DRR-based ladder filters with fractional bandwidths (BW) of ~11%, insertion-loss (I.L) values of ~2.5 dB and with >30 dB out-of-band rejections can now be envisioned, paving an unprecedented path towards the development of ultra-wide band (UWB) filters for next-generation Super-High-Frequency (SHF) radio front-ends.
Group-Sparse Matrix Factorization for Transfer Learning of Word Embeddings
Apr 18, 2021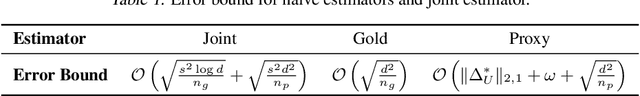
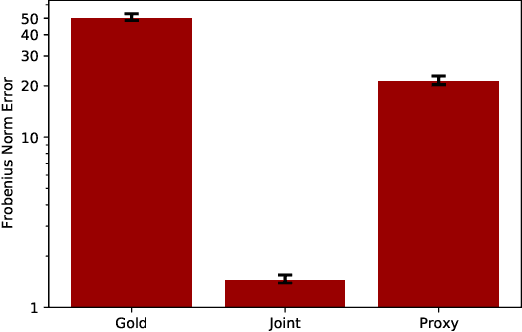
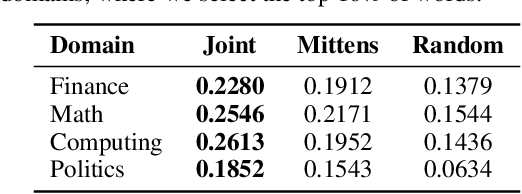
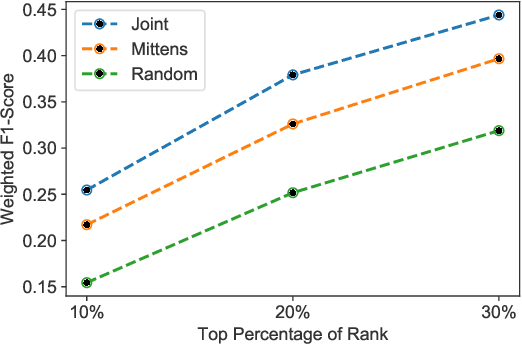
Sparse regression has recently been applied to enable transfer learning from very limited data. We study an extension of this approach to unsupervised learning -- in particular, learning word embeddings from unstructured text corpora using low-rank matrix factorization. Intuitively, when transferring word embeddings to a new domain, we expect that the embeddings change for only a small number of words -- e.g., the ones with novel meanings in that domain. We propose a novel group-sparse penalty that exploits this sparsity to perform transfer learning when there is very little text data available in the target domain -- e.g., a single article of text. We prove generalization bounds for our algorithm. Furthermore, we empirically evaluate its effectiveness, both in terms of prediction accuracy in downstream tasks as well as the interpretability of the results.