 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Combinatorial Experimental Design: Pareto Optimality for Decision-Making and Inference
Feb 27, 2026In this paper, we provide the first investigation into adaptive combinatorial experimental design, focusing on the trade-off between regret minimization and statistical power in combinatorial multi-armed bandits (CMAB). While minimizing regret requires repeated exploitation of high-reward arms, accurate inference on reward gaps requires sufficient exploration of suboptimal actions. We formalize this trade-off through the concept of Pareto optimality and establish equivalent conditions for Pareto-efficient learning in CMAB. We consider two relevant cases under different information structures, i.e., full-bandit feedback and semi-bandit feedback, and propose two algorithms MixCombKL and MixCombUCB respectively for these two cases. We provide theoretical guarantees showing that both algorithms are Pareto optimal, achieving finite-time guarantees on both regret and estimation error of arm gaps. Our results further reveal that richer feedback significantly tightens the attainable Pareto frontier, with the primary gains arising from improved estimation accuracy under our proposed methods. Taken together, these findings establish a principled framework for adaptive combinatorial experimentation in multi-objective decision-making.
Propagating Similarity, Mitigating Uncertainty: Similarity Propagation-enhanced Uncertainty for Multimodal Recommendation
Jan 27, 2026Multimodal Recommendation (MMR) systems are crucial for modern platforms but are often hampered by inherent noise and uncertainty in modal features, such as blurry images, diverse visual appearances, or ambiguous text. Existing methods often overlook this modality-specific uncertainty, leading to ineffective feature fusion. Furthermore, they fail to leverage rich similarity patterns among users and items to refine representations and their corresponding uncertainty estimates. To address these challenges, we propose a novel framework, Similarity Propagation-enhanced Uncertainty for Multimodal Recommendation (SPUMR). SPUMR explicitly models and mitigates uncertainty by first constructing the Modality Similarity Graph and the Collaborative Similarity Graph to refine representations from both content and behavioral perspectives. The Uncertainty-aware Preference Aggregation module then adaptively fuses the refined multimodal features, assigning greater weight to more reliable modalities. Extensive experiments on three benchmark datasets demonstrate that SPUMR achieves significant improvements over existing leading methods.
Match Made with Matrix Completion: Efficient Learning under Matching Interference
Jan 11, 2026Matching markets face increasing needs to learn the matching qualities between demand and supply for effective design of matching policies. In practice, the matching rewards are high-dimensional due to the growing diversity of participants. We leverage a natural low-rank matrix structure of the matching rewards in these two-sided markets, and propose to utilize matrix completion to accelerate reward learning with limited offline data. A unique property for matrix completion in this setting is that the entries of the reward matrix are observed with matching interference -- i.e., the entries are not observed independently but dependently due to matching or budget constraints. Such matching dependence renders unique technical challenges, such as sub-optimality or inapplicability of the existing analytical tools in the matrix completion literature, since they typically rely on sample independence. In this paper, we first show that standard nuclear norm regularization remains theoretically effective under matching interference. We provide a near-optimal Frobenius norm guarantee in this setting, coupled with a new analytical technique. Next, to guide certain matching decisions, we develop a novel ``double-enhanced'' estimator, based off the nuclear norm estimator, with a near-optimal entry-wise guarantee. Our double-enhancement procedure can apply to broader sampling schemes even with dependence, which may be of independent interest. Additionally, we extend our approach to online learning settings with matching constraints such as optimal matching and stable matching, and present improved regret bounds in matrix dimensions. Finally, we demonstrate the practical value of our methods using both synthetic data and real data of labor markets.
Statistical Inference for Matching Decisions via Matrix Completion under Dependent Missingness
Oct 30, 2025This paper studies decision-making and statistical inference for two-sided matching markets via matrix completion. In contrast to the independent sampling assumed in classical matrix completion literature, the observed entries, which arise from past matching data, are constrained by matching capacity. This matching-induced dependence poses new challenges for both estimation and inference in the matrix completion framework. We propose a non-convex algorithm based on Grassmannian gradient descent and establish near-optimal entrywise convergence rates for three canonical mechanisms, i.e., one-to-one matching, one-to-many matching with one-sided random arrival, and two-sided random arrival. To facilitate valid uncertainty quantification and hypothesis testing on matching decisions, we further develop a general debiasing and projection framework for arbitrary linear forms of the reward matrix, deriving asymptotic normality with finite-sample guarantees under matching-induced dependent sampling. Our empirical experiments demonstrate that the proposed approach provides accurate estimation, valid confidence intervals, and efficient evaluation of matching policies.
IPBench: Benchmarking the Knowledge of Large Language Models in Intellectual Property
Apr 22, 2025

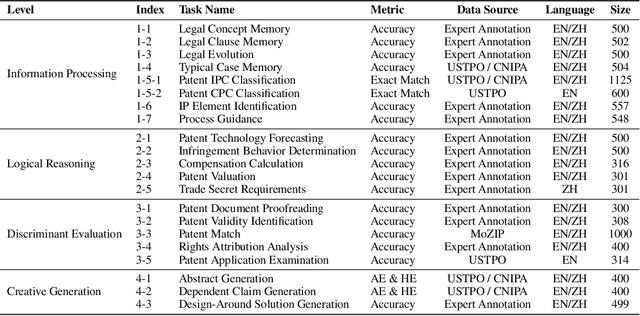
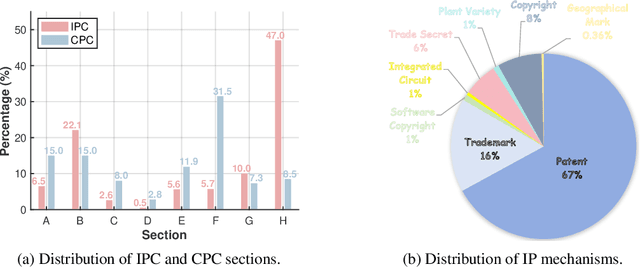
Intellectual Property (IP) is a unique domain that integrates technical and legal knowledge, making it inherently complex and knowledge-intensive. As large language models (LLMs) continue to advance, they show great potential for processing IP tasks, enabling more efficient analysis, understanding, and generation of IP-related content. However, existing datasets and benchmarks either focus narrowly on patents or cover limited aspects of the IP field, lacking alignment with real-world scenarios. To bridge this gap, we introduce the first comprehensive IP task taxonomy and a large, diverse bilingual benchmark, IPBench, covering 8 IP mechanisms and 20 tasks. This benchmark is designed to evaluate LLMs in real-world intellectual property applications, encompassing both understanding and generation. We benchmark 16 LLMs, ranging from general-purpose to domain-specific models, and find that even the best-performing model achieves only 75.8% accuracy, revealing substantial room for improvement. Notably, open-source IP and law-oriented models lag behind closed-source general-purpose models. We publicly release all data and code of IPBench and will continue to update it with additional IP-related tasks to better reflect real-world challenges in the intellectual property domain.
IPEval: A Bilingual Intellectual Property Agency Consultation Evaluation Benchmark for Large Language Models
Jun 18, 2024
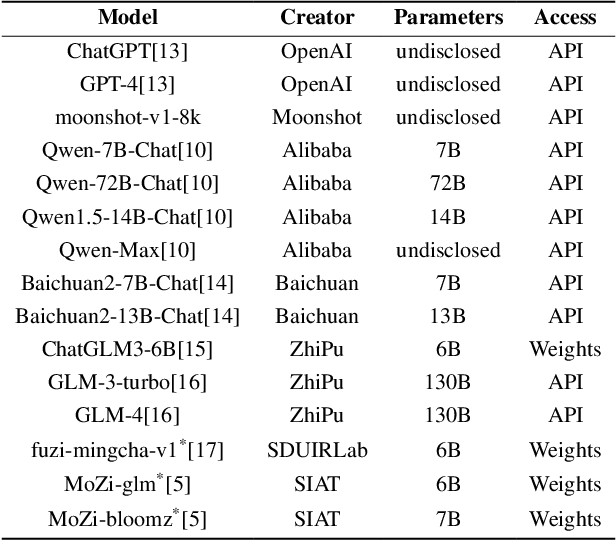
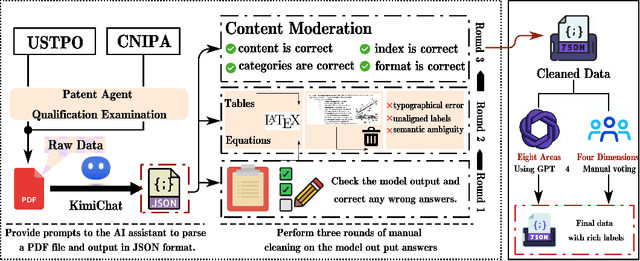
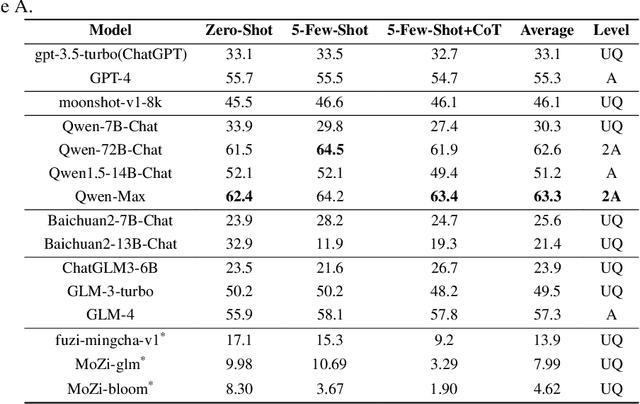
The rapid development of Large Language Models (LLMs) in vertical domains, including intellectual property (IP), lacks a specific evaluation benchmark for assessing their understanding, application, and reasoning abilities. To fill this gap, we introduce IPEval, the first evaluation benchmark tailored for IP agency and consulting tasks. IPEval comprises 2657 multiple-choice questions across four major dimensions: creation, application, protection, and management of IP. These questions span patent rights (inventions, utility models, designs), trademarks, copyrights, trade secrets, and other related laws. Evaluation methods include zero-shot, 5-few-shot, and Chain of Thought (CoT) for seven LLM types, predominantly in English or Chinese. Results show superior English performance by models like GPT series and Qwen series, while Chinese-centric LLMs excel in Chinese tests, albeit specialized IP LLMs lag behind general-purpose ones. Regional and temporal aspects of IP underscore the need for LLMs to grasp legal nuances and evolving laws. IPEval aims to accurately gauge LLM capabilities in IP and spur development of specialized models. Website: \url{https://ipeval.github.io/}
Stochastic Bandits with ReLU Neural Networks
May 12, 2024We study the stochastic bandit problem with ReLU neural network structure. We show that a $\tilde{O}(\sqrt{T})$ regret guarantee is achievable by considering bandits with one-layer ReLU neural networks; to the best of our knowledge, our work is the first to achieve such a guarantee. In this specific setting, we propose an OFU-ReLU algorithm that can achieve this upper bound. The algorithm first explores randomly until it reaches a linear regime, and then implements a UCB-type linear bandit algorithm to balance exploration and exploitation. Our key insight is that we can exploit the piecewise linear structure of ReLU activations and convert the problem into a linear bandit in a transformed feature space, once we learn the parameters of ReLU relatively accurately during the exploration stage. To remove dependence on model parameters, we design an OFU-ReLU+ algorithm based on a batching strategy, which can provide the same theoretical guarantee.
Jointly Explicit and Implicit Cross-Modal Interaction Network for Anterior Chamber Inflammation Diagnosis
Dec 19, 2023



Uveitis demands the precise diagnosis of anterior chamber inflammation (ACI) for optimal treatment. However, current diagnostic methods only rely on a limited single-modal disease perspective, which leads to poor performance. In this paper, we investigate a promising yet challenging way to fuse multimodal data for ACI diagnosis. Notably, existing fusion paradigms focus on empowering implicit modality interactions (i.e., self-attention and its variants), but neglect to inject explicit modality interactions, especially from clinical knowledge and imaging property. To this end, we propose a jointly Explicit and implicit Cross-Modal Interaction Network (EiCI-Net) for Anterior Chamber Inflammation Diagnosis that uses anterior segment optical coherence tomography (AS-OCT) images, slit-lamp images, and clinical data jointly. Specifically, we first develop CNN-Based Encoders and Tabular Processing Module (TPM) to extract efficient feature representations in different modalities. Then, we devise an Explicit Cross-Modal Interaction Module (ECIM) to generate attention maps as a kind of explicit clinical knowledge based on the tabular feature maps, then integrated them into the slit-lamp feature maps, allowing the CNN-Based Encoder to focus on more effective informativeness of the slit-lamp images. After that, the Implicit Cross-Modal Interaction Module (ICIM), a transformer-based network, further implicitly enhances modality interactions. Finally, we construct a considerable real-world dataset from our collaborative hospital and conduct sufficient experiments to demonstrate the superior performance of our proposed EiCI-Net compared with the state-of-the-art classification methods in various metrics.
Optimal Heterogeneous Collaborative Linear Regression and Contextual Bandits
Jun 09, 2023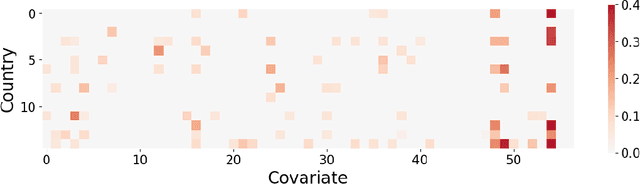

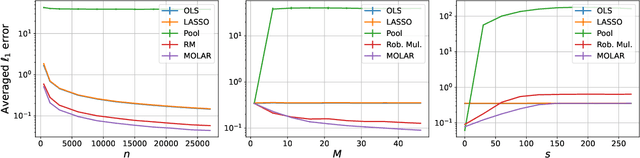
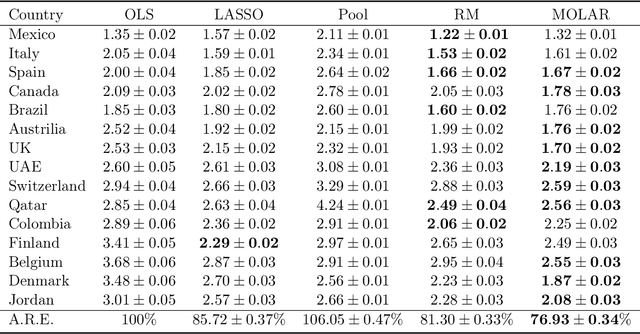
Large and complex datasets are often collected from several, possibly heterogeneous sources. Collaborative learning methods improve efficiency by leveraging commonalities across datasets while accounting for possible differences among them. Here we study collaborative linear regression and contextual bandits, where each instance's associated parameters are equal to a global parameter plus a sparse instance-specific term. We propose a novel two-stage estimator called MOLAR that leverages this structure by first constructing an entry-wise median of the instances' linear regression estimates, and then shrinking the instance-specific estimates towards the median. MOLAR improves the dependence of the estimation error on the data dimension, compared to independent least squares estimates. We then apply MOLAR to develop methods for sparsely heterogeneous collaborative contextual bandits, which lead to improved regret guarantees compared to independent bandit methods. We further show that our methods are minimax optimal by providing a number of lower bounds. Finally, we support the efficiency of our methods by performing experiments on both synthetic data and the PISA dataset on student educational outcomes from heterogeneous countries.
Learning Across Bandits in High Dimension via Robust Statistics
Dec 28, 2021
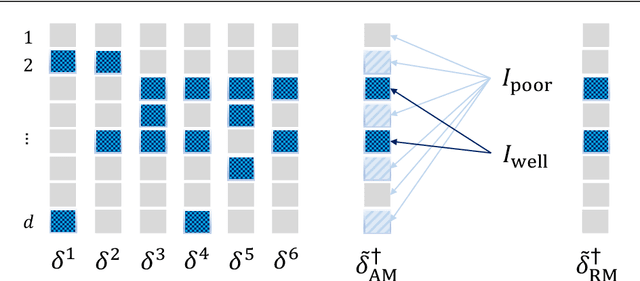
Decision-makers often face the "many bandits" problem, where one must simultaneously learn across related but heterogeneous contextual bandit instances. For instance, a large retailer may wish to dynamically learn product demand across many stores to solve pricing or inventory problems, making it desirable to learn jointly for stores serving similar customers; alternatively, a hospital network may wish to dynamically learn patient risk across many providers to allocate personalized interventions, making it desirable to learn jointly for hospitals serving similar patient populations. We study the setting where the unknown parameter in each bandit instance can be decomposed into a global parameter plus a sparse instance-specific term. Then, we propose a novel two-stage estimator that exploits this structure in a sample-efficient way by using a combination of robust statistics (to learn across similar instances) and LASSO regression (to debias the results). We embed this estimator within a bandit algorithm, and prove that it improves asymptotic regret bounds in the context dimension $d$; this improvement is exponential for data-poor instances. We further demonstrate how our results depend on the underlying network structure of bandit instances.