 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplacing Parameters with Preferences: Federated Alignment of Heterogeneous Vision-Language Models
Jan 31, 2026VLMs have broad potential in privacy-sensitive domains such as healthcare and finance, yet strict data-sharing constraints render centralized training infeasible. FL mitigates this issue by enabling decentralized training, but practical deployments face challenges due to client heterogeneity in computational resources, application requirements, and model architectures. We argue that while replacing data with model parameters characterizes the present of FL, replacing parameters with preferences represents a more scalable and privacy-preserving future. Motivated by this perspective, we propose MoR, a federated alignment framework based on GRPO with Mixture-of-Rewards for heterogeneous VLMs. MoR initializes a visual foundation model as a KL-regularized reference, while each client locally trains a reward model from local preference annotations, capturing specific evaluation signals without exposing raw data. To reconcile heterogeneous rewards, we introduce a routing-based fusion mechanism that adaptively aggregates client reward signals. Finally, the server performs GRPO with this mixed reward to optimize the base VLM. Experiments on three public VQA benchmarks demonstrate that MoR consistently outperforms federated alignment baselines in generalization, robustness, and cross-client adaptability. Our approach provides a scalable solution for privacy-preserving alignment of heterogeneous VLMs under federated settings.
FedDTRE: Federated Dialogue Generation Models Powered by Trustworthiness Evaluation
Oct 09, 2025With the rapid development of artificial intelligence, dialogue systems have become a prominent form of human-computer interaction. However, traditional centralized or fully local training approaches face challenges in balancing privacy preservation and personalization due to data privacy concerns and heterogeneous device capabilities. Federated learning, as a representative distributed paradigm, offers a promising solution. However, existing methods often suffer from overfitting under limited client data and tend to forget global information after multiple training rounds, leading to poor generalization. To address these issues, we propose FedDTRE, a Federated adaptive aggregation strategy for Dialogue generation based on Trustworthiness Evaluation. Instead of directly replacing local models with the global model, FedDTRE leverages trustworthiness scores of both global and local models on a fairness-oriented evaluation dataset to dynamically regulate the global model's contribution during local updates. Experimental results demonstrate that FedDTRE can improve dialogue model performance and enhance the quality of dialogue generation.
AutoPatent: A Multi-Agent Framework for Automatic Patent Generation
Dec 13, 2024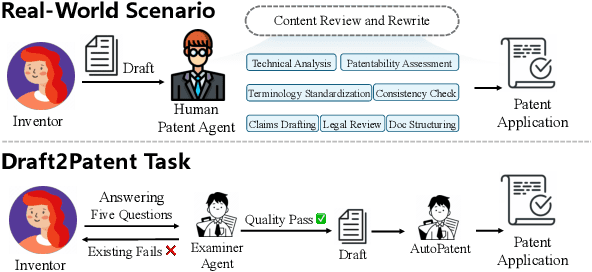
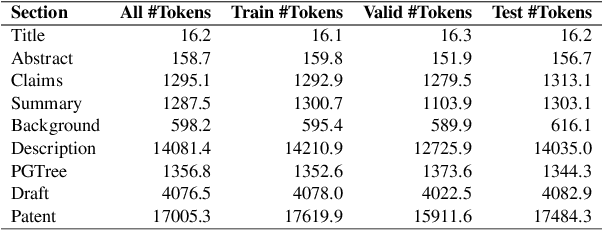
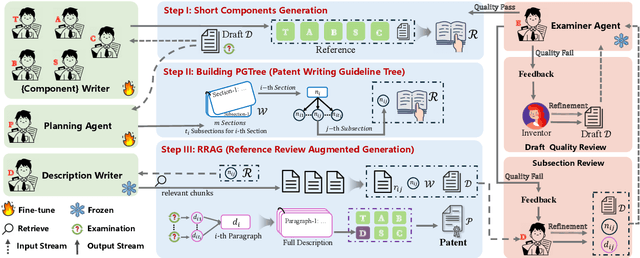
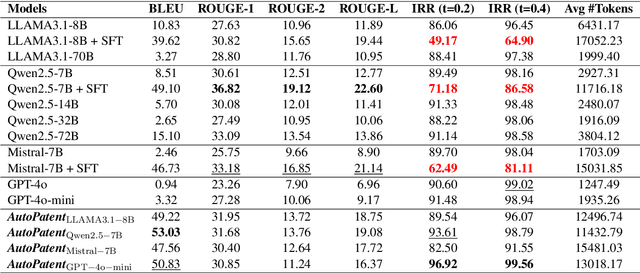
As the capabilities of Large Language Models (LLMs) continue to advance, the field of patent processing has garnered increased attention within the natural language processing community. However, the majority of research has been concentrated on classification tasks, such as patent categorization and examination, or on short text generation tasks like patent summarization and patent quizzes. In this paper, we introduce a novel and practical task known as Draft2Patent, along with its corresponding D2P benchmark, which challenges LLMs to generate full-length patents averaging 17K tokens based on initial drafts. Patents present a significant challenge to LLMs due to their specialized nature, standardized terminology, and extensive length. We propose a multi-agent framework called AutoPatent which leverages the LLM-based planner agent, writer agents, and examiner agent with PGTree and RRAG to generate lengthy, intricate, and high-quality complete patent documents. The experimental results demonstrate that our AutoPatent framework significantly enhances the ability to generate comprehensive patents across various LLMs. Furthermore, we have discovered that patents generated solely with the AutoPatent framework based on the Qwen2.5-7B model outperform those produced by larger and more powerful LLMs, such as GPT-4o, Qwen2.5-72B, and LLAMA3.1-70B, in both objective metrics and human evaluations. We will make the data and code available upon acceptance at \url{https://github.com/QiYao-Wang/AutoPatent}.
IPEval: A Bilingual Intellectual Property Agency Consultation Evaluation Benchmark for Large Language Models
Jun 18, 2024
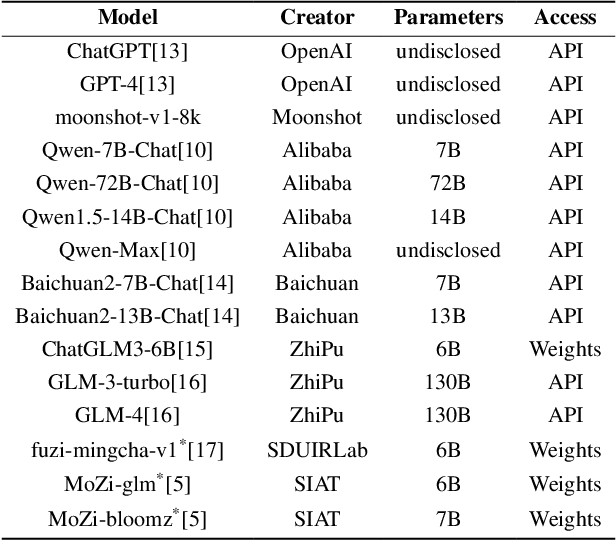
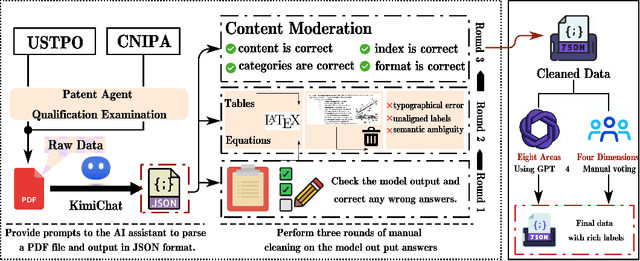
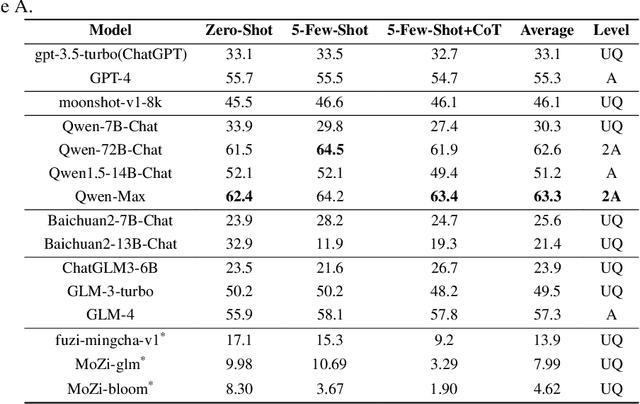
The rapid development of Large Language Models (LLMs) in vertical domains, including intellectual property (IP), lacks a specific evaluation benchmark for assessing their understanding, application, and reasoning abilities. To fill this gap, we introduce IPEval, the first evaluation benchmark tailored for IP agency and consulting tasks. IPEval comprises 2657 multiple-choice questions across four major dimensions: creation, application, protection, and management of IP. These questions span patent rights (inventions, utility models, designs), trademarks, copyrights, trade secrets, and other related laws. Evaluation methods include zero-shot, 5-few-shot, and Chain of Thought (CoT) for seven LLM types, predominantly in English or Chinese. Results show superior English performance by models like GPT series and Qwen series, while Chinese-centric LLMs excel in Chinese tests, albeit specialized IP LLMs lag behind general-purpose ones. Regional and temporal aspects of IP underscore the need for LLMs to grasp legal nuances and evolving laws. IPEval aims to accurately gauge LLM capabilities in IP and spur development of specialized models. Website: \url{https://ipeval.github.io/}