 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexJailbreak: Representation Space Guided Reinforcement Learning for Interpretable LLM Jailbreaking
Jan 30, 2025



Safety alignment mechanism are essential for preventing large language models (LLMs) from generating harmful information or unethical content. However, cleverly crafted prompts can bypass these safety measures without accessing the model's internal parameters, a phenomenon known as black-box jailbreak. Existing heuristic black-box attack methods, such as genetic algorithms, suffer from limited effectiveness due to their inherent randomness, while recent reinforcement learning (RL) based methods often lack robust and informative reward signals. To address these challenges, we propose a novel black-box jailbreak method leveraging RL, which optimizes prompt generation by analyzing the embedding proximity between benign and malicious prompts. This approach ensures that the rewritten prompts closely align with the intent of the original prompts while enhancing the attack's effectiveness. Furthermore, we introduce a comprehensive jailbreak evaluation framework incorporating keywords, intent matching, and answer validation to provide a more rigorous and holistic assessment of jailbreak success. Experimental results show the superiority of our approach, achieving state-of-the-art (SOTA) performance on several prominent open and closed-source LLMs, including Qwen2.5-7B-Instruct, Llama3.1-8B-Instruct, and GPT-4o-0806. Our method sets a new benchmark in jailbreak attack effectiveness, highlighting potential vulnerabilities in LLMs. The codebase for this work is available at https://github.com/Aegis1863/xJailbreak.
AutoPatent: A Multi-Agent Framework for Automatic Patent Generation
Dec 13, 2024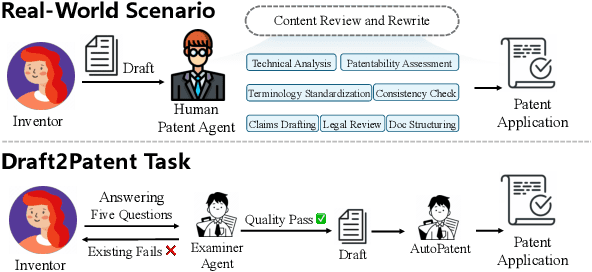
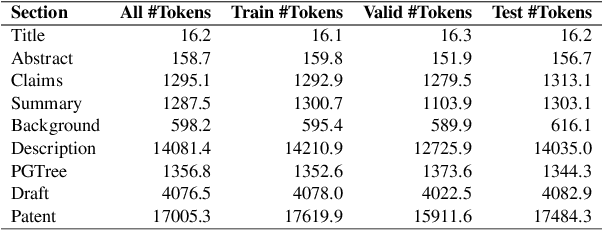
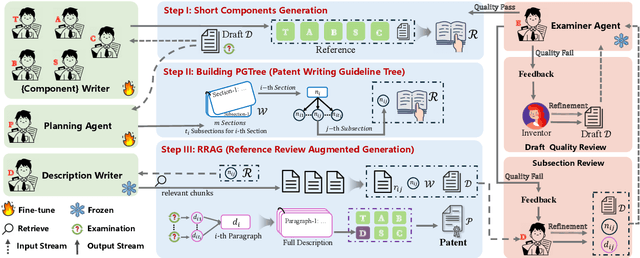
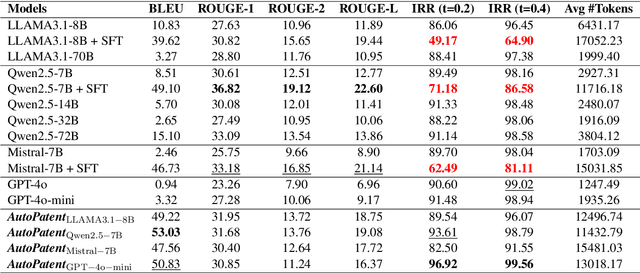
As the capabilities of Large Language Models (LLMs) continue to advance, the field of patent processing has garnered increased attention within the natural language processing community. However, the majority of research has been concentrated on classification tasks, such as patent categorization and examination, or on short text generation tasks like patent summarization and patent quizzes. In this paper, we introduce a novel and practical task known as Draft2Patent, along with its corresponding D2P benchmark, which challenges LLMs to generate full-length patents averaging 17K tokens based on initial drafts. Patents present a significant challenge to LLMs due to their specialized nature, standardized terminology, and extensive length. We propose a multi-agent framework called AutoPatent which leverages the LLM-based planner agent, writer agents, and examiner agent with PGTree and RRAG to generate lengthy, intricate, and high-quality complete patent documents. The experimental results demonstrate that our AutoPatent framework significantly enhances the ability to generate comprehensive patents across various LLMs. Furthermore, we have discovered that patents generated solely with the AutoPatent framework based on the Qwen2.5-7B model outperform those produced by larger and more powerful LLMs, such as GPT-4o, Qwen2.5-72B, and LLAMA3.1-70B, in both objective metrics and human evaluations. We will make the data and code available upon acceptance at \url{https://github.com/QiYao-Wang/AutoPatent}.
A Multi-Source Heterogeneous Knowledge Injected Prompt Learning Method for Legal Charge Prediction
Aug 05, 2024Legal charge prediction, an essential task in legal AI, seeks to assign accurate charge labels to case descriptions, attracting significant recent interest. Existing methods primarily employ diverse neural network structures for modeling case descriptions directly, failing to effectively leverage multi-source external knowledge. We propose a prompt learning framework-based method that simultaneously leverages multi-source heterogeneous external knowledge from a legal knowledge base, a conversational LLM, and related legal articles. Specifically, we match knowledge snippets in case descriptions via the legal knowledge base and encapsulate them into the input through a hard prompt template. Additionally, we retrieve legal articles related to a given case description through contrastive learning, and then obtain factual elements within the case description through a conversational LLM. We fuse the embedding vectors of soft prompt tokens with the encoding vector of factual elements to achieve knowledge-enhanced model forward inference. Experimental results show that our method achieved state-of-the-art results on CAIL-2018, the largest legal charge prediction dataset, and our method has lower data dependency. Case studies also demonstrate our method's strong interpretability.