 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKG2QA: Knowledge Graph-enhanced Retrieval-Augmented Generation for Communication Standards Question Answering
Jun 08, 2025There are many types of standards in the field of communication. The traditional consulting model has a long cycle and relies on the knowledge and experience of experts, making it difficult to meet the rapidly developing technological demands. This paper combines the fine-tuning of large language models with the construction of knowledge graphs to implement an intelligent consultation and question-answering system for communication standards. The experimental results show that after LoRA tuning on the constructed dataset of 6,587 questions and answers in the field of communication standards, Qwen2.5-7B-Instruct demonstrates outstanding professional capabilities in the field of communication standards on the test set. BLEU-4 rose from 18.8564 to 66.8993, and evaluation indicators such as ROUGE also increased significantly, outperforming the fine-tuning effect of the comparison model Llama-3-8B-Instruct. Based on the ontology framework containing 6 entity attributes and 10 relation attributes, a knowledge graph of the communication standard domain containing 13,906 entities and 13,524 relations was constructed, showing a relatively good query accuracy rate. The intelligent consultation and question-answering system enables the fine-tuned model on the server side to access the locally constructed knowledge graph and conduct graphical retrieval of key information first, which is conducive to improving the question-answering effect. The evaluation using DeepSeek as the Judge on the test set shows that our RAG framework enables the fine-tuned model to improve the scores at all five angles, with an average score increase of 2.26%. And combined with web services and API interfaces, it has achieved very good results in terms of interaction experience and back-end access, and has very good practical application value.
ForPKG-1.0: A Framework for Constructing Forestry Policy Knowledge Graph and Application Analysis
Nov 17, 2024A policy knowledge graph can provide decision support for tasks such as project compliance, policy analysis, and intelligent question answering, and can also serve as an external knowledge base to assist the reasoning process of related large language models. Although there have been many related works on knowledge graphs, there is currently a lack of research on the construction methods of policy knowledge graphs. This paper, focusing on the forestry field, designs a complete policy knowledge graph construction framework, including: firstly, proposing a fine-grained forestry policy domain ontology; then, proposing an unsupervised policy information extraction method, and finally, constructing a complete forestry policy knowledge graph. The experimental results show that the proposed ontology has good expressiveness and extensibility, and the policy information extraction method proposed in this paper achieves better results than other unsupervised methods. Furthermore, by analyzing the application of the knowledge graph in the retrieval-augmented-generation task of the large language models, the practical application value of the knowledge graph in the era of large language models is confirmed. The knowledge graph resource will be released on an open-source platform and can serve as the basic knowledge base for forestry policy-related intelligent systems. It can also be used for academic research. In addition, this study can provide reference and guidance for the construction of policy knowledge graphs in other fields.
A Multi-Source Heterogeneous Knowledge Injected Prompt Learning Method for Legal Charge Prediction
Aug 05, 2024Legal charge prediction, an essential task in legal AI, seeks to assign accurate charge labels to case descriptions, attracting significant recent interest. Existing methods primarily employ diverse neural network structures for modeling case descriptions directly, failing to effectively leverage multi-source external knowledge. We propose a prompt learning framework-based method that simultaneously leverages multi-source heterogeneous external knowledge from a legal knowledge base, a conversational LLM, and related legal articles. Specifically, we match knowledge snippets in case descriptions via the legal knowledge base and encapsulate them into the input through a hard prompt template. Additionally, we retrieve legal articles related to a given case description through contrastive learning, and then obtain factual elements within the case description through a conversational LLM. We fuse the embedding vectors of soft prompt tokens with the encoding vector of factual elements to achieve knowledge-enhanced model forward inference. Experimental results show that our method achieved state-of-the-art results on CAIL-2018, the largest legal charge prediction dataset, and our method has lower data dependency. Case studies also demonstrate our method's strong interpretability.
LawLuo: A Chinese Law Firm Co-run by LLM Agents
Jul 23, 2024



Large Language Models (LLMs) demonstrate substantial potential in delivering legal consultation services to users without a legal background, attributed to their superior text comprehension and generation capabilities. Nonetheless, existing Chinese legal LLMs limit interaction to a single model-user dialogue, unlike the collaborative consultations typical of law firms, where multiple staff members contribute to a single consultation. This limitation prevents an authentic consultation experience. Additionally, extant Chinese legal LLMs suffer from critical limitations: (1) insufficient control over the quality of instruction fine-tuning data; (2) increased model hallucination resulting from users' ambiguous queries; and (3) a reduction in the model's ability to follow instructions over multiple dialogue turns. In response to these challenges, we propose a novel legal dialogue framework that leverages the collaborative capabilities of multiple LLM agents, termed LawLuo. This framework encompasses four agents: a receptionist, a lawyer, a secretary, and a boss, each responsible for different functionalities, collaboratively providing a comprehensive legal consultation to users. Additionally, we constructed two high-quality legal dialogue datasets, KINLED and MURLED, and fine-tuned ChatGLM-3-6b using these datasets. We propose a legal query clarification algorithm called ToLC. Experimental results demonstrate that LawLuo outperforms baseline LLMs, including GPT-4, across three dimensions: lawyer-like language style, the usefulness of legal advice, and the accuracy of legal knowledge. Our code and datasets are available at https://github.com/NEFUJing/LawLuo.
A Novel Hybrid Framework for Hourly PM2.5 Concentration Forecasting Using CEEMDAN and Deep Temporal Convolutional Neural Network
Dec 07, 2020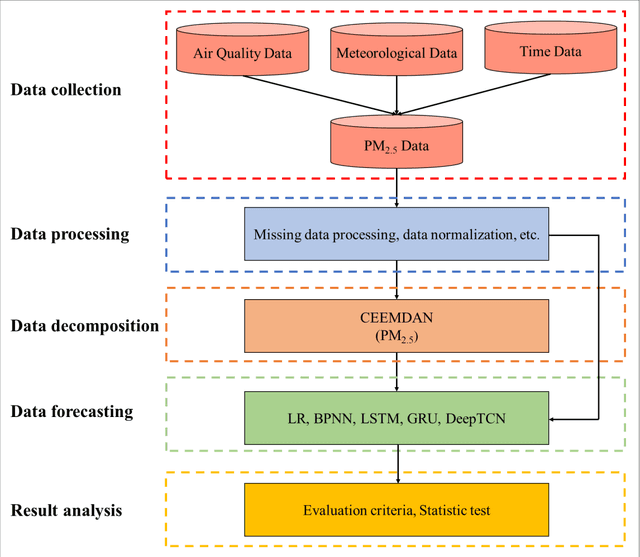
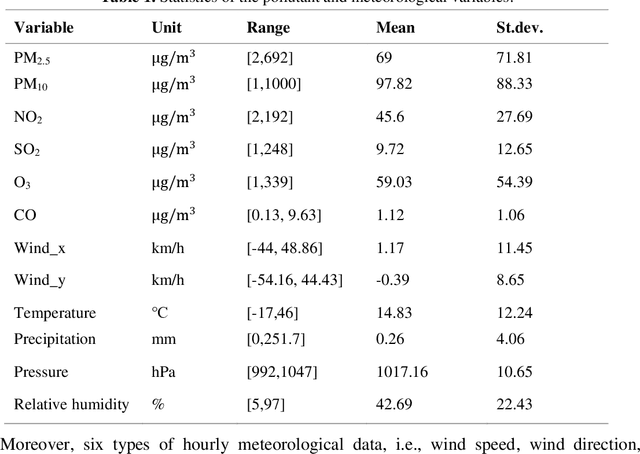
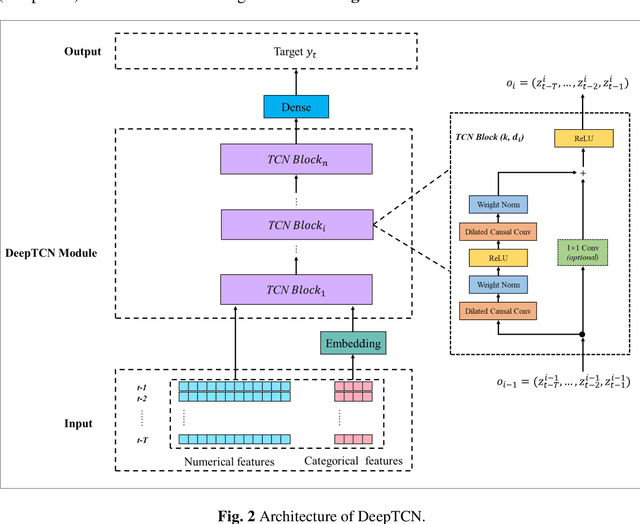
For hourly PM2.5 concentration prediction, accurately capturing the data patterns of external factors that affect PM2.5 concentration changes, and constructing a forecasting model is one of efficient means to improve forecasting accuracy. In this study, a novel hybrid forecasting model based on complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) and deep temporal convolutional neural network (DeepTCN) is developed to predict PM2.5 concentration, by modelling the data patterns of historical pollutant concentrations data, meteorological data, and discrete time variables' data. Taking PM2.5 concentration of Beijing as the sample, experimental results showed that the forecasting accuracy of the proposed CEEMDAN-DeepTCN model is verified to be the highest when compared with the time series model, artificial neural network, and the popular deep learning models. The new model has improved the capability to model the PM2.5-related factor data patterns, and can be used as a promising tool for forecasting PM2.5 concentrations.