 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Physics: A Comprehensive Benchmark for Multimodal LLMs Reasoning on Chinese Multi-Subject Physics Problems
Sep 19, 2025



While multimodal LLMs (MLLMs) demonstrate remarkable reasoning progress, their application in specialized scientific domains like physics reveals significant gaps in current evaluation benchmarks. Specifically, existing benchmarks often lack fine-grained subject coverage, neglect the step-by-step reasoning process, and are predominantly English-centric, failing to systematically evaluate the role of visual information. Therefore, we introduce \textbf {Multi-Physics} for Chinese physics reasoning, a comprehensive benchmark that includes 5 difficulty levels, featuring 1,412 image-associated, multiple-choice questions spanning 11 high-school physics subjects. We employ a dual evaluation framework to evaluate 20 different MLLMs, analyzing both final answer accuracy and the step-by-step integrity of their chain-of-thought. Furthermore, we systematically study the impact of difficulty level and visual information by comparing the model performance before and after changing the input mode. Our work provides not only a fine-grained resource for the community but also offers a robust methodology for dissecting the multimodal reasoning process of state-of-the-art MLLMs, and our dataset and code have been open-sourced: https://github.com/luozhongze/Multi-Physics.
KG2QA: Knowledge Graph-enhanced Retrieval-Augmented Generation for Communication Standards Question Answering
Jun 08, 2025There are many types of standards in the field of communication. The traditional consulting model has a long cycle and relies on the knowledge and experience of experts, making it difficult to meet the rapidly developing technological demands. This paper combines the fine-tuning of large language models with the construction of knowledge graphs to implement an intelligent consultation and question-answering system for communication standards. The experimental results show that after LoRA tuning on the constructed dataset of 6,587 questions and answers in the field of communication standards, Qwen2.5-7B-Instruct demonstrates outstanding professional capabilities in the field of communication standards on the test set. BLEU-4 rose from 18.8564 to 66.8993, and evaluation indicators such as ROUGE also increased significantly, outperforming the fine-tuning effect of the comparison model Llama-3-8B-Instruct. Based on the ontology framework containing 6 entity attributes and 10 relation attributes, a knowledge graph of the communication standard domain containing 13,906 entities and 13,524 relations was constructed, showing a relatively good query accuracy rate. The intelligent consultation and question-answering system enables the fine-tuned model on the server side to access the locally constructed knowledge graph and conduct graphical retrieval of key information first, which is conducive to improving the question-answering effect. The evaluation using DeepSeek as the Judge on the test set shows that our RAG framework enables the fine-tuned model to improve the scores at all five angles, with an average score increase of 2.26%. And combined with web services and API interfaces, it has achieved very good results in terms of interaction experience and back-end access, and has very good practical application value.
HGO-YOLO: Advancing Anomaly Behavior Detection with Hierarchical Features and Lightweight Optimized Detection
Mar 10, 2025


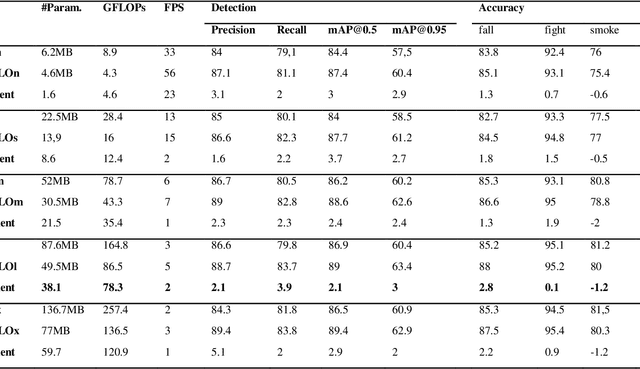
Accurate and real-time object detection is crucial for anomaly behavior detection, especially in scenarios constrained by hardware limitations, where balancing accuracy and speed is essential for enhancing detection performance. This study proposes a model called HGO-YOLO, which integrates the HGNetv2 architecture into YOLOv8. This combination expands the receptive field and captures a wider range of features while simplifying model complexity through GhostConv. We introduced a lightweight detection head, OptiConvDetect, which utilizes parameter sharing to construct the detection head effectively. Evaluation results show that the proposed algorithm achieves a mAP@0.5 of 87.4% and a recall rate of 81.1%, with a model size of only 4.6 MB and a frame rate of 56 FPS on the CPU. HGO-YOLO not only improves accuracy by 3.0% but also reduces computational load by 51.69% (from 8.9 GFLOPs to 4.3 GFLOPs), while increasing the frame rate by a factor of 1.7. Additionally, real-time tests were conducted on Raspberry Pi4 and NVIDIA platforms. These results indicate that the HGO-YOLO model demonstrates superior performance in anomaly behavior detection.
ForPKG-1.0: A Framework for Constructing Forestry Policy Knowledge Graph and Application Analysis
Nov 17, 2024A policy knowledge graph can provide decision support for tasks such as project compliance, policy analysis, and intelligent question answering, and can also serve as an external knowledge base to assist the reasoning process of related large language models. Although there have been many related works on knowledge graphs, there is currently a lack of research on the construction methods of policy knowledge graphs. This paper, focusing on the forestry field, designs a complete policy knowledge graph construction framework, including: firstly, proposing a fine-grained forestry policy domain ontology; then, proposing an unsupervised policy information extraction method, and finally, constructing a complete forestry policy knowledge graph. The experimental results show that the proposed ontology has good expressiveness and extensibility, and the policy information extraction method proposed in this paper achieves better results than other unsupervised methods. Furthermore, by analyzing the application of the knowledge graph in the retrieval-augmented-generation task of the large language models, the practical application value of the knowledge graph in the era of large language models is confirmed. The knowledge graph resource will be released on an open-source platform and can serve as the basic knowledge base for forestry policy-related intelligent systems. It can also be used for academic research. In addition, this study can provide reference and guidance for the construction of policy knowledge graphs in other fields.
LawLuo: A Chinese Law Firm Co-run by LLM Agents
Jul 23, 2024



Large Language Models (LLMs) demonstrate substantial potential in delivering legal consultation services to users without a legal background, attributed to their superior text comprehension and generation capabilities. Nonetheless, existing Chinese legal LLMs limit interaction to a single model-user dialogue, unlike the collaborative consultations typical of law firms, where multiple staff members contribute to a single consultation. This limitation prevents an authentic consultation experience. Additionally, extant Chinese legal LLMs suffer from critical limitations: (1) insufficient control over the quality of instruction fine-tuning data; (2) increased model hallucination resulting from users' ambiguous queries; and (3) a reduction in the model's ability to follow instructions over multiple dialogue turns. In response to these challenges, we propose a novel legal dialogue framework that leverages the collaborative capabilities of multiple LLM agents, termed LawLuo. This framework encompasses four agents: a receptionist, a lawyer, a secretary, and a boss, each responsible for different functionalities, collaboratively providing a comprehensive legal consultation to users. Additionally, we constructed two high-quality legal dialogue datasets, KINLED and MURLED, and fine-tuned ChatGLM-3-6b using these datasets. We propose a legal query clarification algorithm called ToLC. Experimental results demonstrate that LawLuo outperforms baseline LLMs, including GPT-4, across three dimensions: lawyer-like language style, the usefulness of legal advice, and the accuracy of legal knowledge. Our code and datasets are available at https://github.com/NEFUJing/LawLuo.