 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cosine Network for Image Super-Resolution
Jan 23, 2026Deep convolutional neural networks can use hierarchical information to progressively extract structural information to recover high-quality images. However, preserving the effectiveness of the obtained structural information is important in image super-resolution. In this paper, we propose a cosine network for image super-resolution (CSRNet) by improving a network architecture and optimizing the training strategy. To extract complementary homologous structural information, odd and even heterogeneous blocks are designed to enlarge the architectural differences and improve the performance of image super-resolution. Combining linear and non-linear structural information can overcome the drawback of homologous information and enhance the robustness of the obtained structural information in image super-resolution. Taking into account the local minimum of gradient descent, a cosine annealing mechanism is used to optimize the training procedure by performing warm restarts and adjusting the learning rate. Experimental results illustrate that the proposed CSRNet is competitive with state-of-the-art methods in image super-resolution.
When Context Is Not Enough: Modeling Unexplained Variability in Car-Following Behavior
Jul 09, 2025Modeling car-following behavior is fundamental to microscopic traffic simulation, yet traditional deterministic models often fail to capture the full extent of variability and unpredictability in human driving. While many modern approaches incorporate context-aware inputs (e.g., spacing, speed, relative speed), they frequently overlook structured stochasticity that arises from latent driver intentions, perception errors, and memory effects -- factors that are not directly observable from context alone. To fill the gap, this study introduces an interpretable stochastic modeling framework that captures not only context-dependent dynamics but also residual variability beyond what context can explain. Leveraging deep neural networks integrated with nonstationary Gaussian processes (GPs), our model employs a scenario-adaptive Gibbs kernel to learn dynamic temporal correlations in acceleration decisions, where the strength and duration of correlations between acceleration decisions evolve with the driving context. This formulation enables a principled, data-driven quantification of uncertainty in acceleration, speed, and spacing, grounded in both observable context and latent behavioral variability. Comprehensive experiments on the naturalistic vehicle trajectory dataset collected from the German highway, i.e., the HighD dataset, demonstrate that the proposed stochastic simulation method within this framework surpasses conventional methods in both predictive performance and interpretable uncertainty quantification. The integration of interpretability and accuracy makes this framework a promising tool for traffic analysis and safety-critical applications.
Markov Regime-Switching Intelligent Driver Model for Interpretable Car-Following Behavior
Jun 17, 2025Accurate and interpretable car-following models are essential for traffic simulation and autonomous vehicle development. However, classical models like the Intelligent Driver Model (IDM) are fundamentally limited by their parsimonious and single-regime structure. They fail to capture the multi-modal nature of human driving, where a single driving state (e.g., speed, relative speed, and gap) can elicit many different driver actions. This forces the model to average across distinct behaviors, reducing its fidelity and making its parameters difficult to interpret. To overcome this, we introduce a regime-switching framework that allows driving behavior to be governed by different IDM parameter sets, each corresponding to an interpretable behavioral mode. This design enables the model to dynamically switch between interpretable behavioral modes, rather than averaging across diverse driving contexts. We instantiate the framework using a Factorial Hidden Markov Model with IDM dynamics (FHMM-IDM), which explicitly separates intrinsic driving regimes (e.g., aggressive acceleration, steady-state following) from external traffic scenarios (e.g., free-flow, congestion, stop-and-go) through two independent latent Markov processes. Bayesian inference via Markov chain Monte Carlo (MCMC) is used to jointly estimate the regime-specific parameters, transition dynamics, and latent state trajectories. Experiments on the HighD dataset demonstrate that FHMM-IDM uncovers interpretable structure in human driving, effectively disentangling internal driver actions from contextual traffic conditions and revealing dynamic regime-switching patterns. This framework provides a tractable and principled solution to modeling context-dependent driving behavior under uncertainty, offering improvements in the fidelity of traffic simulations, the efficacy of safety analyses, and the development of more human-centric ADAS.
BiPrompt-SAM: Enhancing Image Segmentation via Explicit Selection between Point and Text Prompts
Mar 25, 2025



Segmentation is a fundamental task in computer vision, with prompt-driven methods gaining prominence due to their flexibility. The recent Segment Anything Model (SAM) has demonstrated powerful point-prompt segmentation capabilities, while text-based segmentation models offer rich semantic understanding. However, existing approaches rarely explore how to effectively combine these complementary modalities for optimal segmentation performance. This paper presents BiPrompt-SAM, a novel dual-modal prompt segmentation framework that fuses the advantages of point and text prompts through an explicit selection mechanism. Specifically, we leverage SAM's inherent ability to generate multiple mask candidates, combined with a semantic guidance mask from text prompts, and explicitly select the most suitable candidate based on similarity metrics. This approach can be viewed as a simplified Mixture of Experts (MoE) system, where the point and text modules act as distinct "experts," and the similarity scoring serves as a rudimentary "gating network." We conducted extensive evaluations on both the Endovis17 medical dataset and RefCOCO series natural image datasets. On Endovis17, BiPrompt-SAM achieved 89.55\% mDice and 81.46\% mIoU, comparable to state-of-the-art specialized medical segmentation models. On the RefCOCO series datasets, our method attained 87.1\%, 86.5\%, and 85.8\% IoU, significantly outperforming existing approaches. Experiments demonstrate that our explicit dual-selection method effectively combines the spatial precision of point prompts with the semantic richness of text prompts, particularly excelling in scenarios involving semantically complex objects, multiple similar objects, and partial occlusions. BiPrompt-SAM not only provides a simple yet effective implementation but also offers a new perspective on multi-modal prompt fusion.
DAVE: Diverse Atomic Visual Elements Dataset with High Representation of Vulnerable Road Users in Complex and Unpredictable Environments
Dec 28, 2024



Most existing traffic video datasets including Waymo are structured, focusing predominantly on Western traffic, which hinders global applicability. Specifically, most Asian scenarios are far more complex, involving numerous objects with distinct motions and behaviors. Addressing this gap, we present a new dataset, DAVE, designed for evaluating perception methods with high representation of Vulnerable Road Users (VRUs: e.g. pedestrians, animals, motorbikes, and bicycles) in complex and unpredictable environments. DAVE is a manually annotated dataset encompassing 16 diverse actor categories (spanning animals, humans, vehicles, etc.) and 16 action types (complex and rare cases like cut-ins, zigzag movement, U-turn, etc.), which require high reasoning ability. DAVE densely annotates over 13 million bounding boxes (bboxes) actors with identification, and more than 1.6 million boxes are annotated with both actor identification and action/behavior details. The videos within DAVE are collected based on a broad spectrum of factors, such as weather conditions, the time of day, road scenarios, and traffic density. DAVE can benchmark video tasks like Tracking, Detection, Spatiotemporal Action Localization, Language-Visual Moment retrieval, and Multi-label Video Action Recognition. Given the critical importance of accurately identifying VRUs to prevent accidents and ensure road safety, in DAVE, vulnerable road users constitute 41.13% of instances, compared to 23.71% in Waymo. DAVE provides an invaluable resource for the development of more sensitive and accurate visual perception algorithms in the complex real world. Our experiments show that existing methods suffer degradation in performance when evaluated on DAVE, highlighting its benefit for future video recognition research.
UIFormer: A Unified Transformer-based Framework for Incremental Few-Shot Object Detection and Instance Segmentation
Nov 13, 2024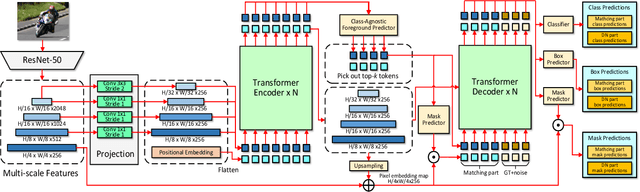



This paper introduces a novel framework for unified incremental few-shot object detection (iFSOD) and instance segmentation (iFSIS) using the Transformer architecture. Our goal is to create an optimal solution for situations where only a few examples of novel object classes are available, with no access to training data for base or old classes, while maintaining high performance across both base and novel classes. To achieve this, We extend Mask-DINO into a two-stage incremental learning framework. Stage 1 focuses on optimizing the model using the base dataset, while Stage 2 involves fine-tuning the model on novel classes. Besides, we incorporate a classifier selection strategy that assigns appropriate classifiers to the encoder and decoder according to their distinct functions. Empirical evidence indicates that this approach effectively mitigates the over-fitting on novel classes learning. Furthermore, we implement knowledge distillation to prevent catastrophic forgetting of base classes. Comprehensive evaluations on the COCO and LVIS datasets for both iFSIS and iFSOD tasks demonstrate that our method significantly outperforms state-of-the-art approaches.
Learning Car-Following Behaviors Using Bayesian Matrix Normal Mixture Regression
Apr 24, 2024



Learning and understanding car-following (CF) behaviors are crucial for microscopic traffic simulation. Traditional CF models, though simple, often lack generalization capabilities, while many data-driven methods, despite their robustness, operate as "black boxes" with limited interpretability. To bridge this gap, this work introduces a Bayesian Matrix Normal Mixture Regression (MNMR) model that simultaneously captures feature correlations and temporal dynamics inherent in CF behaviors. This approach is distinguished by its separate learning of row and column covariance matrices within the model framework, offering an insightful perspective into the human driver decision-making processes. Through extensive experiments, we assess the model's performance across various historical steps of inputs, predictive steps of outputs, and model complexities. The results consistently demonstrate our model's adeptness in effectively capturing the intricate correlations and temporal dynamics present during CF. A focused case study further illustrates the model's outperforming interpretability of identifying distinct operational conditions through the learned mean and covariance matrices. This not only underlines our model's effectiveness in understanding complex human driving behaviors in CF scenarios but also highlights its potential as a tool for enhancing the interpretability of CF behaviors in traffic simulations and autonomous driving systems.
Interactive Car-Following: Matters but NOT Always
Jul 30, 2023



Following a leading vehicle is a daily but challenging task because it requires adapting to various traffic conditions and the leading vehicle's behaviors. However, the question `Does the following vehicle always actively react to the leading vehicle?' remains open. To seek the answer, we propose a novel metric to quantify the interaction intensity within the car-following pairs. The quantified interaction intensity enables us to recognize interactive and non-interactive car-following scenarios and derive corresponding policies for each scenario. Then, we develop an interaction-aware switching control framework with interactive and non-interactive policies, achieving a human-level car-following performance. The extensive simulations demonstrate that our interaction-aware switching control framework achieves improved control performance and data efficiency compared to the unified control strategies. Moreover, the experimental results reveal that human drivers would not always keep reacting to their leading vehicle but occasionally take safety-critical or intentional actions -- interaction matters but not always.
Discovering Dynamic Patterns from Spatiotemporal Data with Time-Varying Low-Rank Autoregression
Nov 28, 2022The problem of broad practical interest in spatiotemporal data analysis, i.e., discovering interpretable dynamic patterns from spatiotemporal data, is studied in this paper. Towards this end, we develop a time-varying reduced-rank vector autoregression (VAR) model whose coefficient matrices are parameterized by low-rank tensor factorization. Benefiting from the tensor factorization structure, the proposed model can simultaneously achieve model compression and pattern discovery. In particular, the proposed model allows one to characterize nonstationarity and time-varying system behaviors underlying spatiotemporal data. To evaluate the proposed model, extensive experiments are conducted on various spatiotemporal data representing different nonlinear dynamical systems, including fluid dynamics, sea surface temperature, USA surface temperature, and NYC taxi trips. Experimental results demonstrate the effectiveness of modeling spatiotemporal data and characterizing spatial/temporal patterns with the proposed model. In the spatial context, the spatial patterns can be automatically extracted and intuitively characterized by the spatial modes. In the temporal context, the complex time-varying system behaviors can be revealed by the temporal modes in the proposed model. Thus, our model lays an insightful foundation for understanding complex spatiotemporal data in real-world dynamical systems. The adapted datasets and Python implementation are publicly available at https://github.com/xinychen/vars.
Social Interactions for Autonomous Driving: A Review and Perspective
Aug 17, 2022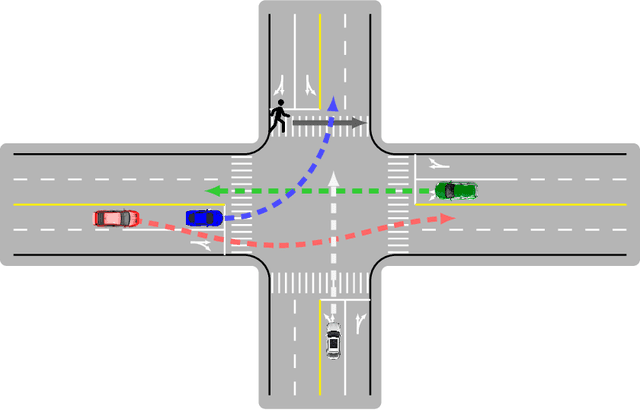

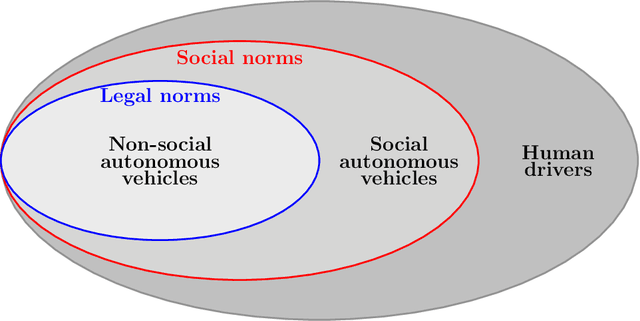
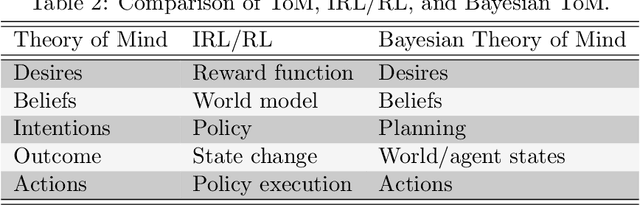
No human drives a car in a vacuum; she/he must negotiate with other road users to achieve their goals in social traffic scenes. A rational human driver can interact with other road users in a socially-compatible way through implicit communications to complete their driving tasks smoothly in interaction-intensive, safety-critical environments. This paper aims to review the existing approaches and theories to help understand and rethink the interactions among human drivers toward social autonomous driving. We take this survey to seek the answers to a series of fundamental questions: 1) What is social interaction in road traffic scenes? 2) How to measure and evaluate social interaction? 3) How to model and reveal the process of social interaction? 4) How do human drivers reach an implicit agreement and negotiate smoothly in social interaction? This paper reviews various approaches to modeling and learning the social interactions between human drivers, ranging from optimization theory and graphical models to social force theory and behavioral & cognitive science. We also highlight some new directions, critical challenges, and opening questions for future research.