 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredict and Resist: Long-Term Accident Anticipation under Sensor Noise
Nov 10, 2025Accident anticipation is essential for proactive and safe autonomous driving, where even a brief advance warning can enable critical evasive actions. However, two key challenges hinder real-world deployment: (1) noisy or degraded sensory inputs from weather, motion blur, or hardware limitations, and (2) the need to issue timely yet reliable predictions that balance early alerts with false-alarm suppression. We propose a unified framework that integrates diffusion-based denoising with a time-aware actor-critic model to address these challenges. The diffusion module reconstructs noise-resilient image and object features through iterative refinement, preserving critical motion and interaction cues under sensor degradation. In parallel, the actor-critic architecture leverages long-horizon temporal reasoning and time-weighted rewards to determine the optimal moment to raise an alert, aligning early detection with reliability. Experiments on three benchmark datasets (DAD, CCD, A3D) demonstrate state-of-the-art accuracy and significant gains in mean time-to-accident, while maintaining robust performance under Gaussian and impulse noise. Qualitative analyses further show that our model produces earlier, more stable, and human-aligned predictions in both routine and highly complex traffic scenarios, highlighting its potential for real-world, safety-critical deployment.
Effective Reinforcement Learning Control using Conservative Soft Actor-Critic
May 06, 2025Reinforcement Learning (RL) has shown great potential in complex control tasks, particularly when combined with deep neural networks within the Actor-Critic (AC) framework. However, in practical applications, balancing exploration, learning stability, and sample efficiency remains a significant challenge. Traditional methods such as Soft Actor-Critic (SAC) and Proximal Policy Optimization (PPO) address these issues by incorporating entropy or relative entropy regularization, but often face problems of instability and low sample efficiency. In this paper, we propose the Conservative Soft Actor-Critic (CSAC) algorithm, which seamlessly integrates entropy and relative entropy regularization within the AC framework. CSAC improves exploration through entropy regularization while avoiding overly aggressive policy updates with the use of relative entropy regularization. Evaluations on benchmark tasks and real-world robotic simulations demonstrate that CSAC offers significant improvements in stability and efficiency over existing methods. These findings suggest that CSAC provides strong robustness and application potential in control tasks under dynamic environments.
High-resolution on-road air pollution exposure informed by taxi-based mobile monitoring sensors
Dec 13, 2024Air pollutant exposure exhibits significant spatial and temporal variability, with localized hotspots, particularly in traffic microenvironments, posing health risks to commuters. Although widely used for air quality assessment, fixed-site monitoring stations are limited by sparse distribution, high costs, and maintenance needs, making them less effective in capturing on-road pollution levels. This study utilizes a fleet of 314 taxis equipped with sensors to measure NO\textsubscript{2}, PM\textsubscript{2.5}, and PM\textsubscript{10} concentrations and identify high-exposure hotspots. The findings reveal disparities between mobile and stationary measurements, map the spatiotemporal exposure patterns, and highlight local hotspots. These results demonstrate the potential of mobile monitoring to provide fine-scale, on-road air pollution assessments, offering valuable insights for policymakers to design targeted interventions and protect public health, particularly for sensitive populations.
Dynamic High-Order Control Barrier Functions with Diffuser for Safety-Critical Trajectory Planning at Signal-Free Intersections
Nov 29, 2024



Planning safe and efficient trajectories through signal-free intersections presents significant challenges for autonomous vehicles (AVs), particularly in dynamic, multi-task environments with unpredictable interactions and an increased possibility of conflicts. This study aims to address these challenges by developing a robust, adaptive framework to ensure safety in such complex scenarios. Existing approaches often struggle to provide reliable safety mechanisms in dynamic and learn multi-task behaviors from demonstrations in signal-free intersections. This study proposes a safety-critical planning method that integrates Dynamic High-Order Control Barrier Functions (DHOCBF) with a diffusion-based model, called Dynamic Safety-Critical Diffuser (DSC-Diffuser), offering a robust solution for adaptive, safe, and multi-task driving in signal-free intersections. Our approach incorporates a goal-oriented, task-guided diffusion model, enabling the model to learn multiple driving tasks simultaneously from real-world data. To further ensure driving safety in dynamic environments, the proposed DHOCBF framework dynamically adjusts to account for the movements of surrounding vehicles, offering enhanced adaptability compared to traditional control barrier functions. Validity evaluations of DHOCBF, conducted through numerical simulations, demonstrate its robustness in adapting to variations in obstacle velocities, sizes, uncertainties, and locations, effectively maintaining driving safety across a wide range of complex and uncertain scenarios. Performance evaluations across various scenes confirm that DSC-Diffuser provides realistic, stable, and generalizable policies, equipping it with the flexibility to adapt to diverse driving tasks.
Traj-Explainer: An Explainable and Robust Multi-modal Trajectory Prediction Approach
Oct 22, 2024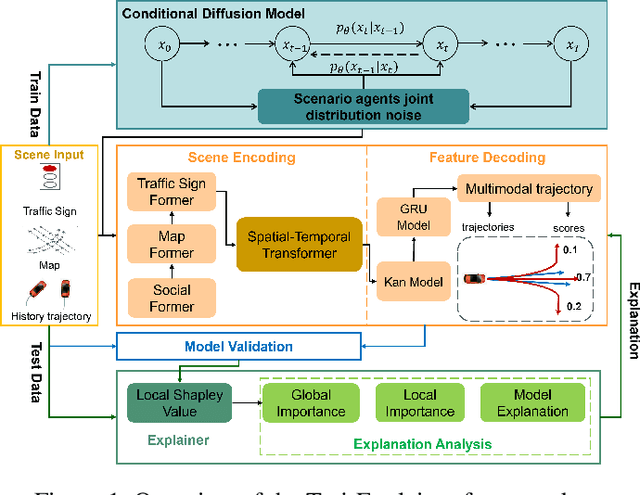
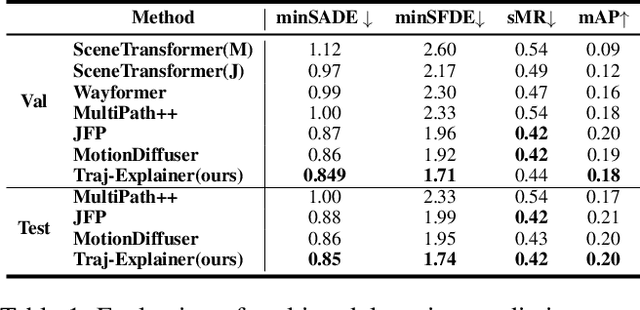

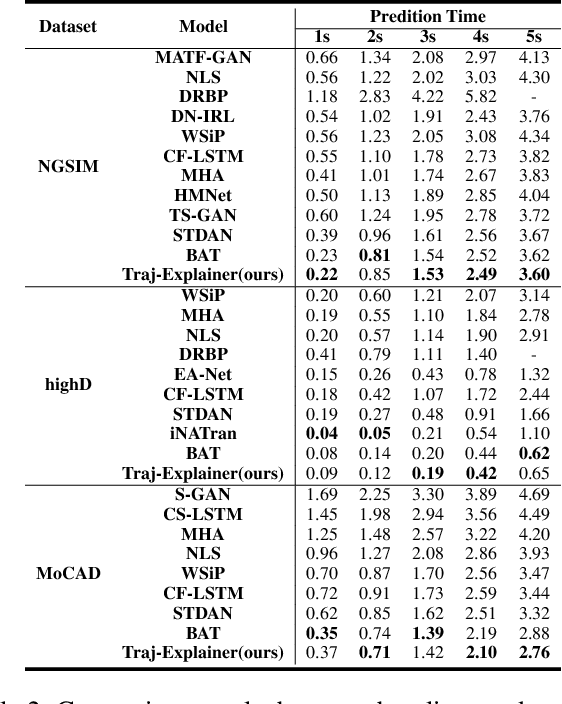
Navigating complex traffic environments has been significantly enhanced by advancements in intelligent technologies, enabling accurate environment perception and trajectory prediction for automated vehicles. However, existing research often neglects the consideration of the joint reasoning of scenario agents and lacks interpretability in trajectory prediction models, thereby limiting their practical application in real-world scenarios. To this purpose, an explainability-oriented trajectory prediction model is designed in this work, named Explainable Conditional Diffusion based Multimodal Trajectory Prediction Traj-Explainer, to retrieve the influencing factors of prediction and help understand the intrinsic mechanism of prediction. In Traj-Explainer, a modified conditional diffusion is well designed to capture the scenario multimodal trajectory pattern, and meanwhile, a modified Shapley Value model is assembled to rationally learn the importance of the global and scenario features. Numerical experiments are carried out by several trajectory prediction datasets, including Waymo, NGSIM, HighD, and MoCAD datasets. Furthermore, we evaluate the identified input factors which indicates that they are in agreement with the human driving experience, indicating the capability of the proposed model in appropriately learning the prediction. Code available in our open-source repository: \url{https://anonymous.4open.science/r/Interpretable-Prediction}.
Preference Aligned Diffusion Planner for Quadrupedal Locomotion Control
Oct 17, 2024



Diffusion models demonstrate superior performance in capturing complex distributions from large-scale datasets, providing a promising solution for quadrupedal locomotion control. However, offline policy is sensitive to Out-of-Distribution (OOD) states due to the limited state coverage in the datasets. In this work, we propose a two-stage learning framework combining offline learning and online preference alignment for legged locomotion control. Through the offline stage, the diffusion planner learns the joint distribution of state-action sequences from expert datasets without using reward labels. Subsequently, we perform the online interaction in the simulation environment based on the trained offline planer, which significantly addresses the OOD issues and improves the robustness. Specifically, we propose a novel weak preference labeling method without the ground-truth reward or human preferences. The proposed method exhibits superior stability and velocity tracking accuracy in pacing, trotting, and bounding gait under both slow- and high-speed scenarios and can perform zero-shot transfer to the real Unitree Go1 robots. The project website for this paper is at https://shangjaven.github.io/preference-aligned-diffusion-legged/.
HeightFormer: A Semantic Alignment Monocular 3D Object Detection Method from Roadside Perspective
Oct 10, 2024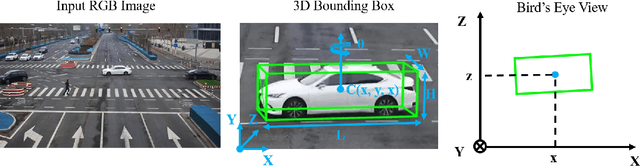
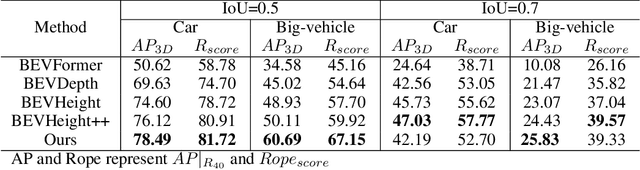
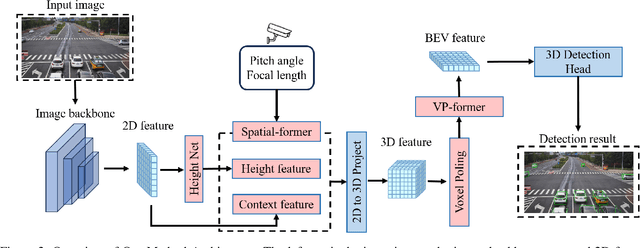
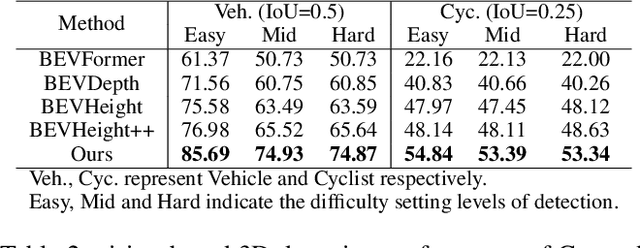
The on-board 3D object detection technology has received extensive attention as a critical technology for autonomous driving, while few studies have focused on applying roadside sensors in 3D traffic object detection. Existing studies achieve the projection of 2D image features to 3D features through height estimation based on the frustum. However, they did not consider the height alignment and the extraction efficiency of bird's-eye-view features. We propose a novel 3D object detection framework integrating Spatial Former and Voxel Pooling Former to enhance 2D-to-3D projection based on height estimation. Extensive experiments were conducted using the Rope3D and DAIR-V2X-I dataset, and the results demonstrated the outperformance of the proposed algorithm in the detection of both vehicles and cyclists. These results indicate that the algorithm is robust and generalized under various detection scenarios. Improving the accuracy of 3D object detection on the roadside is conducive to building a safe and trustworthy intelligent transportation system of vehicle-road coordination and promoting the large-scale application of autonomous driving. The code and pre-trained models will be released on https://anonymous.4open.science/r/HeightFormer.
Automating Traffic Model Enhancement with AI Research Agent
Sep 25, 2024



Developing efficient traffic models is essential for optimizing transportation systems, yet current approaches remain time-intensive and susceptible to human errors due to their reliance on manual processes. Traditional workflows involve exhaustive literature reviews, formula optimization, and iterative testing, leading to inefficiencies in research. In response, we introduce the Traffic Research Agent (TR-Agent), an AI-driven system designed to autonomously develop and refine traffic models through an iterative, closed-loop process. Specifically, we divide the research pipeline into four key stages: idea generation, theory formulation, theory evaluation, and iterative optimization; and construct TR-Agent with four corresponding modules: Idea Generator, Code Generator, Evaluator, and Analyzer. Working in synergy, these modules retrieve knowledge from external resources, generate novel ideas, implement and debug models, and finally assess them on the evaluation datasets. Furthermore, the system continuously refines these models based on iterative feedback, enhancing research efficiency and model performance. Experimental results demonstrate that TR-Agent achieves significant performance improvements across multiple traffic models, including the Intelligent Driver Model (IDM) for car following, the MOBIL lane-changing model, and the Lighthill-Whitham-Richards (LWR) traffic flow model. Additionally, TR-Agent provides detailed explanations for its optimizations, allowing researchers to verify and build upon its improvements easily. This flexibility makes the framework a powerful tool for researchers in transportation and beyond. To further support research and collaboration, we have open-sourced both the code and data used in our experiments, facilitating broader access and enabling continued advancements in the field.
From Words to Wheels: Automated Style-Customized Policy Generation for Autonomous Driving
Sep 18, 2024



Autonomous driving technology has witnessed rapid advancements, with foundation models improving interactivity and user experiences. However, current autonomous vehicles (AVs) face significant limitations in delivering command-based driving styles. Most existing methods either rely on predefined driving styles that require expert input or use data-driven techniques like Inverse Reinforcement Learning to extract styles from driving data. These approaches, though effective in some cases, face challenges: difficulty obtaining specific driving data for style matching (e.g., in Robotaxis), inability to align driving style metrics with user preferences, and limitations to pre-existing styles, restricting customization and generalization to new commands. This paper introduces Words2Wheels, a framework that automatically generates customized driving policies based on natural language user commands. Words2Wheels employs a Style-Customized Reward Function to generate a Style-Customized Driving Policy without relying on prior driving data. By leveraging large language models and a Driving Style Database, the framework efficiently retrieves, adapts, and generalizes driving styles. A Statistical Evaluation module ensures alignment with user preferences. Experimental results demonstrate that Words2Wheels outperforms existing methods in accuracy, generalization, and adaptability, offering a novel solution for customized AV driving behavior. Code and demo available at https://yokhon.github.io/Words2Wheels/.
EcoFollower: An Environment-Friendly Car Following Model Considering Fuel Consumption
Jul 22, 2024



To alleviate energy shortages and environmental impacts caused by transportation, this study introduces EcoFollower, a novel eco-car-following model developed using reinforcement learning (RL) to optimize fuel consumption in car-following scenarios. Employing the NGSIM datasets, the performance of EcoFollower was assessed in comparison with the well-established Intelligent Driver Model (IDM). The findings demonstrate that EcoFollower excels in simulating realistic driving behaviors, maintaining smooth vehicle operations, and closely matching the ground truth metrics of time-to-collision (TTC), headway, and comfort. Notably, the model achieved a significant reduction in fuel consumption, lowering it by 10.42\% compared to actual driving scenarios. These results underscore the capability of RL-based models like EcoFollower to enhance autonomous vehicle algorithms, promoting safer and more energy-efficient driving strategies.