 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior Distribution-assisted Evolutionary Dynamic Optimization as an Online Calibrator for Complex Social Simulations
Jan 27, 2026The calibration of simulators for complex social systems aims to identify the optimal parameter that drives the output of the simulator best matching the target data observed from the system. As many social systems may change internally over time, calibration naturally becomes an online task, requiring parameters to be updated continuously to maintain the simulator's fidelity. In this work, the online setting is first formulated as a dynamic optimization problem (DOP), requiring the search for a sequence of optimal parameters that fit the simulator to real system changes. However, in contrast to traditional DOP formulations, online calibration explicitly incorporates the observational data as the driver of environmental dynamics. Due to this fundamental difference, existing Evolutionary Dynamic Optimization (EDO) methods, despite being extensively studied for black-box DOPs, are ill-equipped to handle such a scenario. As a result, online calibration problems constitute a new set of challenging DOPs. Here, we propose to explicitly learn the posterior distributions of the parameters and the observational data, thereby facilitating both change detection and environmental adaptation of existing EDOs for this scenario. We thus present a pretrained posterior model for implementation, and fine-tune it during the optimization. Extensive tests on both economic and financial simulators verify that the posterior distribution strongly promotes EDOs in such DOPs widely existed in social science.
Calibrating Agent-Based Financial Markets Simulators with Pretrainable Automatic Posterior Transformation-Based Surrogates
Jan 11, 2026Calibrating Agent-Based Models (ABMs) is an important optimization problem for simulating the complex social systems, where the goal is to identify the optimal parameter of a given ABM by minimizing the discrepancy between the simulated data and the real-world observations. Unfortunately, it suffers from the extensive computational costs of iterative evaluations, which involves the expensive simulation with the candidate parameter. While Surrogate-Assisted Evolutionary Algorithms (SAEAs) have been widely adopted to alleviate the computational burden, existing methods face two key limitations: 1) surrogating the original evaluation function is hard due the nonlinear yet multi-modal nature of the ABMs, and 2) the commonly used surrogates cannot share the optimization experience among multiple calibration tasks, making the batched calibration less effective. To address these issues, this work proposes Automatic posterior transformation with Negatively Correlated Search and Adaptive Trust-Region (ANTR). ANTR first replaces the traditional surrogates with a pretrainable neural density estimator that directly models the posterior distribution of the parameters given observed data, thereby aligning the optimization objective with parameter-space accuracy. Furthermore, we incorporate a diversity-preserving search strategy to prevent premature convergence and an adaptive trust-region method to efficiently allocate computational resources. We take two representative ABM-based financial market simulators as the test bench as due to the high non-linearity. Experiments demonstrate that the proposed ANTR significantly outperforms conventional metaheuristics and state-of-the-art SAEAs in both calibration accuracy and computational efficiency, particularly in batch calibration scenarios across multiple market conditions.
Are Large Language Models Chronically Online Surfers? A Dataset for Chinese Internet Meme Explanation
Oct 01, 2025Large language models (LLMs) are trained on vast amounts of text from the Internet, but do they truly understand the viral content that rapidly spreads online -- commonly known as memes? In this paper, we introduce CHIME, a dataset for CHinese Internet Meme Explanation. The dataset comprises popular phrase-based memes from the Chinese Internet, annotated with detailed information on their meaning, origin, example sentences, types, etc. To evaluate whether LLMs understand these memes, we designed two tasks. In the first task, we assessed the models' ability to explain a given meme, identify its origin, and generate appropriate example sentences. The results show that while LLMs can explain the meanings of some memes, their performance declines significantly for culturally and linguistically nuanced meme types. Additionally, they consistently struggle to provide accurate origins for the memes. In the second task, we created a set of multiple-choice questions (MCQs) requiring LLMs to select the most appropriate meme to fill in a blank within a contextual sentence. While the evaluated models were able to provide correct answers, their performance remains noticeably below human levels. We have made CHIME public and hope it will facilitate future research on computational meme understanding.
Learning from Expert Factors: Trajectory-level Reward Shaping for Formulaic Alpha Mining
Jul 27, 2025
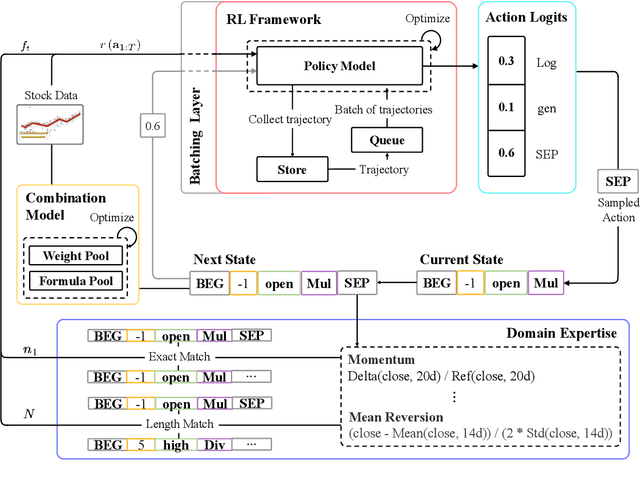
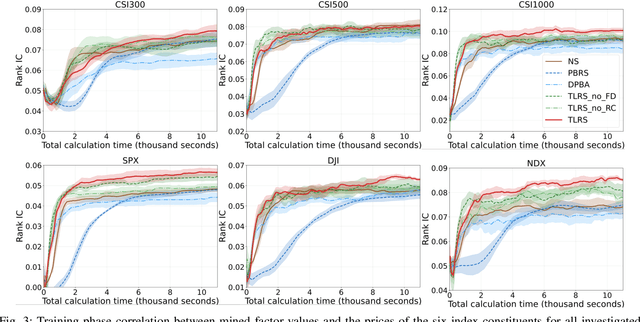
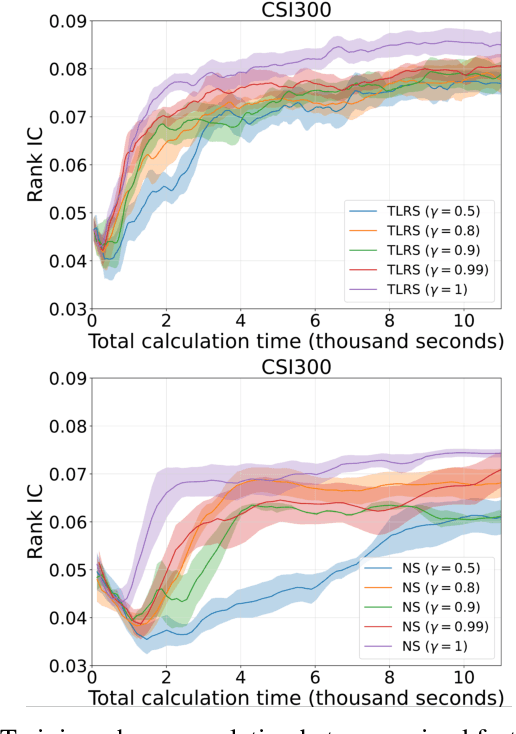
Reinforcement learning (RL) has successfully automated the complex process of mining formulaic alpha factors, for creating interpretable and profitable investment strategies. However, existing methods are hampered by the sparse rewards given the underlying Markov Decision Process. This inefficiency limits the exploration of the vast symbolic search space and destabilizes the training process. To address this, Trajectory-level Reward Shaping (TLRS), a novel reward shaping method, is proposed. TLRS provides dense, intermediate rewards by measuring the subsequence-level similarity between partially generated expressions and a set of expert-designed formulas. Furthermore, a reward centering mechanism is introduced to reduce training variance. Extensive experiments on six major Chinese and U.S. stock indices show that TLRS significantly improves the predictive power of mined factors, boosting the Rank Information Coefficient by 9.29% over existing potential-based shaping algorithms. Notably, TLRS achieves a major leap in computational efficiency by reducing its time complexity with respect to the feature dimension from linear to constant, which is a significant improvement over distance-based baselines.
Preference Aligned Diffusion Planner for Quadrupedal Locomotion Control
Oct 17, 2024



Diffusion models demonstrate superior performance in capturing complex distributions from large-scale datasets, providing a promising solution for quadrupedal locomotion control. However, offline policy is sensitive to Out-of-Distribution (OOD) states due to the limited state coverage in the datasets. In this work, we propose a two-stage learning framework combining offline learning and online preference alignment for legged locomotion control. Through the offline stage, the diffusion planner learns the joint distribution of state-action sequences from expert datasets without using reward labels. Subsequently, we perform the online interaction in the simulation environment based on the trained offline planer, which significantly addresses the OOD issues and improves the robustness. Specifically, we propose a novel weak preference labeling method without the ground-truth reward or human preferences. The proposed method exhibits superior stability and velocity tracking accuracy in pacing, trotting, and bounding gait under both slow- and high-speed scenarios and can perform zero-shot transfer to the real Unitree Go1 robots. The project website for this paper is at https://shangjaven.github.io/preference-aligned-diffusion-legged/.