 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Large Language Models Chronically Online Surfers? A Dataset for Chinese Internet Meme Explanation
Oct 01, 2025Large language models (LLMs) are trained on vast amounts of text from the Internet, but do they truly understand the viral content that rapidly spreads online -- commonly known as memes? In this paper, we introduce CHIME, a dataset for CHinese Internet Meme Explanation. The dataset comprises popular phrase-based memes from the Chinese Internet, annotated with detailed information on their meaning, origin, example sentences, types, etc. To evaluate whether LLMs understand these memes, we designed two tasks. In the first task, we assessed the models' ability to explain a given meme, identify its origin, and generate appropriate example sentences. The results show that while LLMs can explain the meanings of some memes, their performance declines significantly for culturally and linguistically nuanced meme types. Additionally, they consistently struggle to provide accurate origins for the memes. In the second task, we created a set of multiple-choice questions (MCQs) requiring LLMs to select the most appropriate meme to fill in a blank within a contextual sentence. While the evaluated models were able to provide correct answers, their performance remains noticeably below human levels. We have made CHIME public and hope it will facilitate future research on computational meme understanding.
This joke is : Recognizing Humor and Offense with Prompting
Oct 25, 2022



Humor is a magnetic component in everyday human interactions and communications. Computationally modeling humor enables NLP systems to entertain and engage with users. We investigate the effectiveness of prompting, a new transfer learning paradigm for NLP, for humor recognition. We show that prompting performs similarly to finetuning when numerous annotations are available, but gives stellar performance in low-resource humor recognition. The relationship between humor and offense is also inspected by applying influence functions to prompting; we show that models could rely on offense to determine humor during transfer.
AFEC: A Knowledge Graph Capturing Social Intelligence in Casual Conversations
May 22, 2022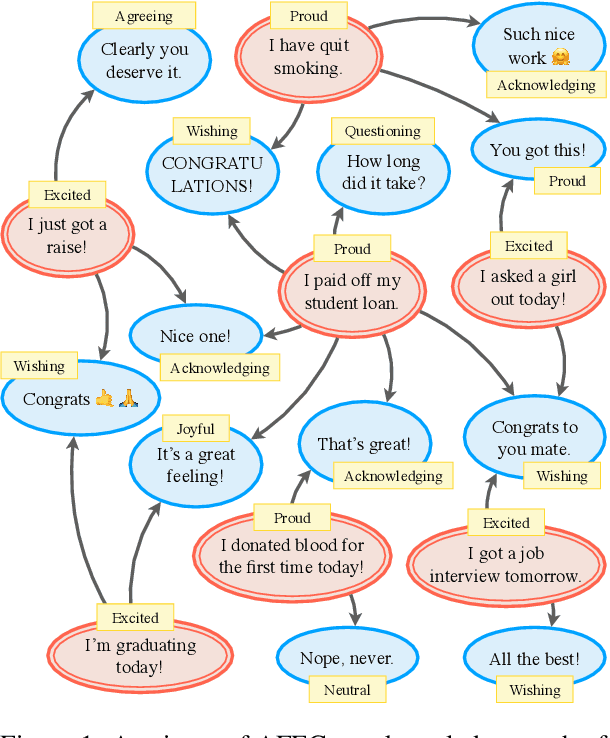



This paper introduces AFEC, an automatically curated knowledge graph based on people's day-to-day casual conversations. The knowledge captured in this graph bears potential for conversational systems to understand how people offer acknowledgement, consoling, and a wide range of empathetic responses in social conversations. For this body of knowledge to be comprehensive and meaningful, we curated a large-scale corpus from the r/CasualConversation SubReddit. After taking the first two turns of all conversations, we obtained 134K speaker nodes and 666K listener nodes. To demonstrate how a chatbot can converse in social settings, we built a retrieval-based chatbot and compared it with existing empathetic dialog models. Experiments show that our model is capable of generating much more diverse responses (at least 15% higher diversity scores in human evaluation), while still outperforming two out of the four baselines in terms of response quality.
How Commonsense Knowledge Helps with Natural Language Tasks: A Survey of Recent Resources and Methodologies
Aug 10, 2021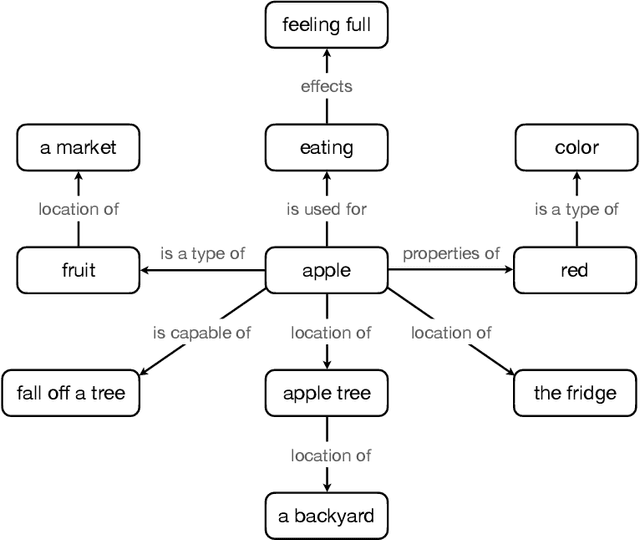
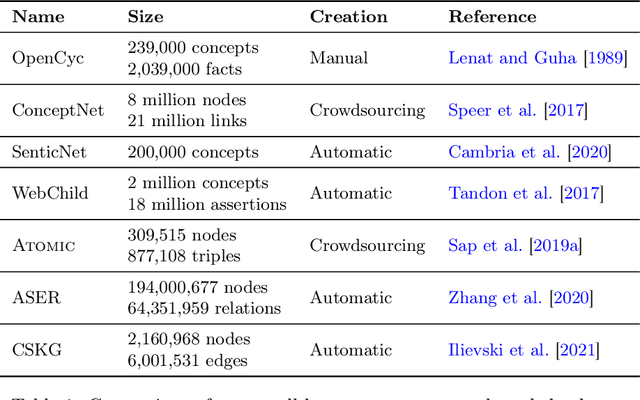
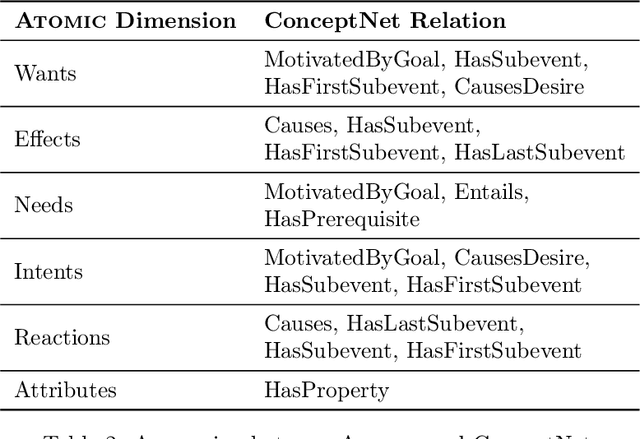
In this paper, we give an overview of commonsense reasoning in natural language processing, which requires a deeper understanding of the contexts and usually involves inference over implicit external knowledge. We first review some popular commonsense knowledge bases and commonsense reasoning benchmarks, but give more emphasis on the methodologies, including recent approaches that aim at solving some general natural language problems that take advantage of external knowledge bases. Finally, we discuss some future directions in pushing the boundary of commonsense reasoning in natural language processing.
Generating Empathetic Responses with a Large Scale Dialog Dataset
May 14, 2021



The task of empathetic response generation aims at generating syntactically correct and, more importantly, emotionally appropriate responses following previous dialog turns. Existing models either directly incorporate pre-defined emotion information to guide the response generation, or use deterministic rules to decide the response emotion, ignoring the subtle emotion interactions captured in human conversations. With the advent of advanced language models, it is possible to learn the nuanced emotional exchanges captured in natural language dialogs. To fully explore the range of emotions and dialog intents, it is important to curate a dataset large enough to shed light on the general understanding of human emotional interactions in our conversations. In this paper, we describe in detail the curation process of a large-scale dialog dataset where each utterance is labeled with one of 32 emotions and 9 intent categories. We then show how to build a multi-turn empathetic dialog model that performs well compared to its baselines over 6,000 human evaluated instances.
Fine-grained Emotion and Intent Learning in Movie Dialogues
Dec 25, 2020

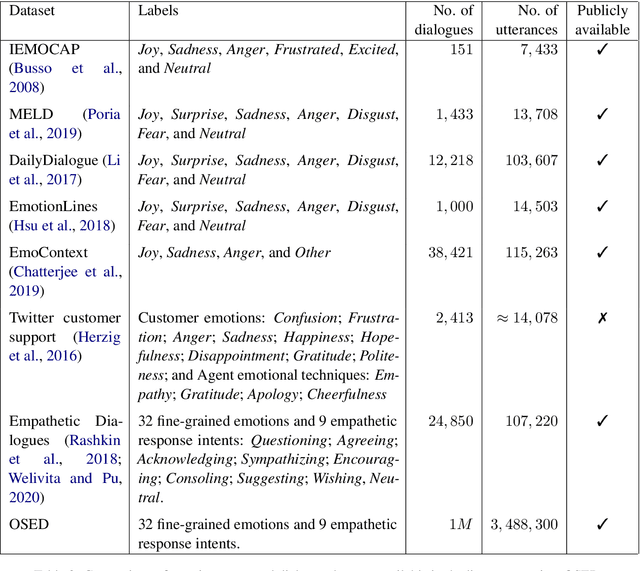
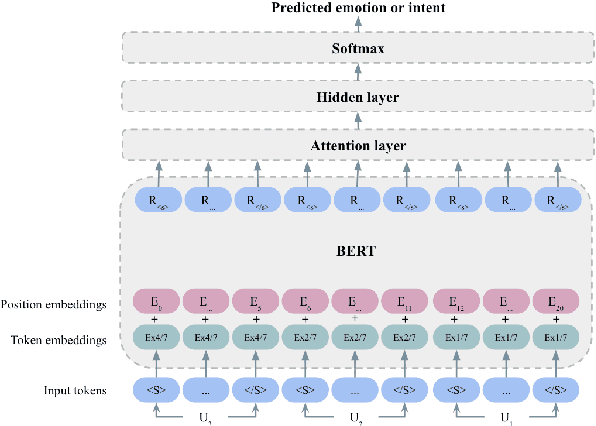
We propose a novel large-scale emotional dialogue dataset, consisting of 1M dialogues retrieved from the OpenSubtitles corpus and annotated with 32 emotions and 9 empathetic response intents using a BERT-based fine-grained dialogue emotion classifier. This work explains the complex pipeline used to preprocess movie subtitles and select good movie dialogues to annotate. We also describe the semi-supervised learning process followed to train a fine-grained emotion classifier to annotate these dialogues. Despite the large set of labels, our dialogue emotion classifier achieved an accuracy of $65\%$ and was used to annotate 1M emotional movie dialogues from OpenSubtitles. This scale of emotional dialogue classification has never been attempted before, both in terms of dataset size and fine-grained emotion and intent categories. Visualization techniques used to analyze the quality of the resultant dataset suggest that it conforms to the patterns of human social interaction.
Uncertainty and Surprisal Jointly Deliver the Punchline: Exploiting Incongruity-Based Features for Humor Recognition
Dec 22, 2020

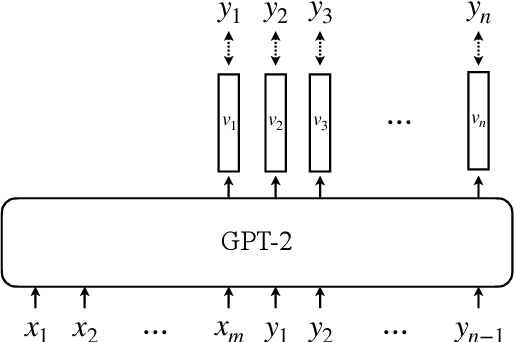

Humor recognition has been widely studied as a text classification problem using data-driven approaches. However, most existing work does not examine the actual joke mechanism to understand humor. We break down any joke into two distinct components: the set-up and the punchline, and further explore the special relationship between them. Inspired by the incongruity theory of humor, we model the set-up as the part developing semantic uncertainty, and the punchline disrupting audience expectations. With increasingly powerful language models, we were able to feed the set-up along with the punchline into the GPT-2 language model, and calculate the uncertainty and surprisal values of the jokes. By conducting experiments on the SemEval 2021 Task 7 dataset, we found that these two features have better capabilities of telling jokes from non-jokes, compared with existing baselines.
A Multi-Turn Emotionally Engaging Dialog Model
Sep 14, 2019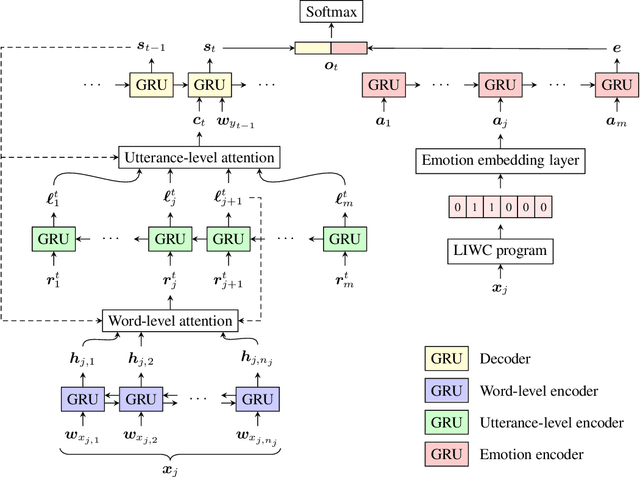
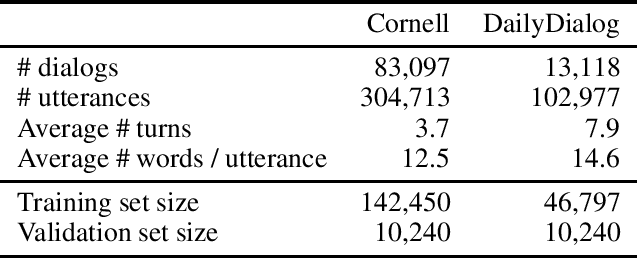


Open-domain dialog systems (also known as chatbots) have increasingly drawn attention in natural language processing. Some of the recent work aims at incorporating affect information into sequence-to-sequence neural dialog modeling, making the response emotionally richer, while others use hand-crafted rules to determine the desired emotion response. However, they do not explicitly learn the subtle emotional interactions captured in human dialogs. In this paper, we propose a multi-turn dialog system aimed at learning and generating emotional responses that so far only humans know how to do. Compared with two baseline models, offline experiments show that our method performs the best in perplexity scores. Further human evaluations confirm that our chatbot can keep track of the conversation context and generate emotionally more appropriate responses while performing equally well on grammar.