 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Emotion and Intent Learning in Movie Dialogues
Paper and Code
Dec 25, 2020

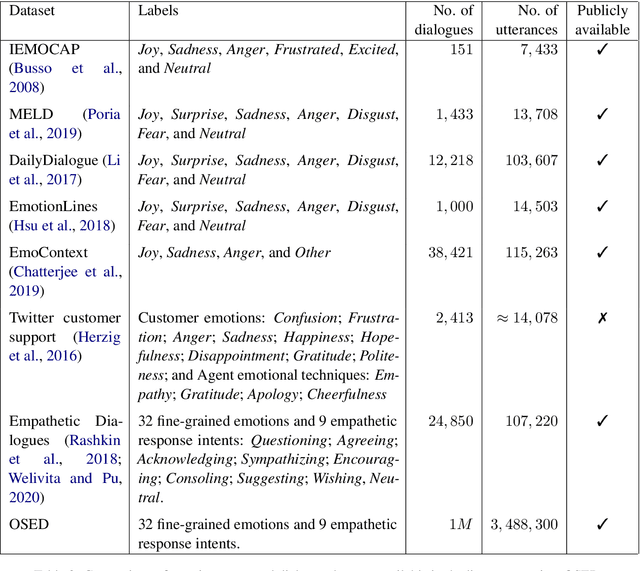
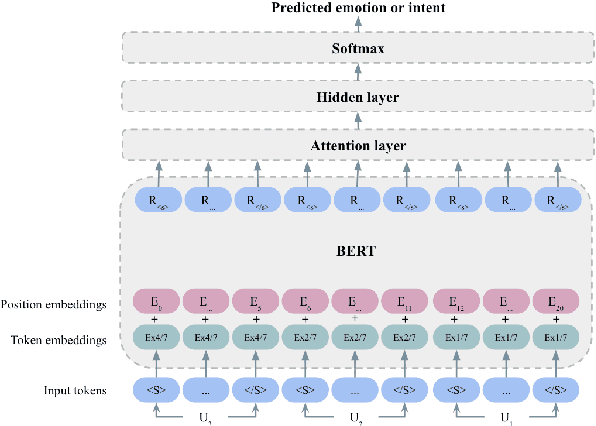
We propose a novel large-scale emotional dialogue dataset, consisting of 1M dialogues retrieved from the OpenSubtitles corpus and annotated with 32 emotions and 9 empathetic response intents using a BERT-based fine-grained dialogue emotion classifier. This work explains the complex pipeline used to preprocess movie subtitles and select good movie dialogues to annotate. We also describe the semi-supervised learning process followed to train a fine-grained emotion classifier to annotate these dialogues. Despite the large set of labels, our dialogue emotion classifier achieved an accuracy of $65\%$ and was used to annotate 1M emotional movie dialogues from OpenSubtitles. This scale of emotional dialogue classification has never been attempted before, both in terms of dataset size and fine-grained emotion and intent categories. Visualization techniques used to analyze the quality of the resultant dataset suggest that it conforms to the patterns of human social interaction.