 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline vs Offline: A Comparative Study of First-Party and Third-Party Evaluations of Social Chatbots
Sep 12, 2024This paper explores the efficacy of online versus offline evaluation methods in assessing conversational chatbots, specifically comparing first-party direct interactions with third-party observational assessments. By extending a benchmarking dataset of user dialogs with empathetic chatbots with offline third-party evaluations, we present a systematic comparison between the feedback from online interactions and the more detached offline third-party evaluations. Our results reveal that offline human evaluations fail to capture the subtleties of human-chatbot interactions as effectively as online assessments. In comparison, automated third-party evaluations using a GPT-4 model offer a better approximation of first-party human judgments given detailed instructions. This study highlights the limitations of third-party evaluations in grasping the complexities of user experiences and advocates for the integration of direct interaction feedback in conversational AI evaluation to enhance system development and user satisfaction.
Are Large Language Models More Empathetic than Humans?
Jun 07, 2024



With the emergence of large language models (LLMs), investigating if they can surpass humans in areas such as emotion recognition and empathetic responding has become a focal point of research. This paper presents a comprehensive study exploring the empathetic responding capabilities of four state-of-the-art LLMs: GPT-4, LLaMA-2-70B-Chat, Gemini-1.0-Pro, and Mixtral-8x7B-Instruct in comparison to a human baseline. We engaged 1,000 participants in a between-subjects user study, assessing the empathetic quality of responses generated by humans and the four LLMs to 2,000 emotional dialogue prompts meticulously selected to cover a broad spectrum of 32 distinct positive and negative emotions. Our findings reveal a statistically significant superiority of the empathetic responding capability of LLMs over humans. GPT-4 emerged as the most empathetic, marking approximately 31% increase in responses rated as "Good" compared to the human benchmark. It was followed by LLaMA-2, Mixtral-8x7B, and Gemini-Pro, which showed increases of approximately 24%, 21%, and 10% in "Good" ratings, respectively. We further analyzed the response ratings at a finer granularity and discovered that some LLMs are significantly better at responding to specific emotions compared to others. The suggested evaluation framework offers a scalable and adaptable approach for assessing the empathy of new LLMs, avoiding the need to replicate this study's findings in future research.
Is ChatGPT More Empathetic than Humans?
Feb 22, 2024



This paper investigates the empathetic responding capabilities of ChatGPT, particularly its latest iteration, GPT-4, in comparison to human-generated responses to a wide range of emotional scenarios, both positive and negative. We employ a rigorous evaluation methodology, involving a between-groups study with 600 participants, to evaluate the level of empathy in responses generated by humans and ChatGPT. ChatGPT is prompted in two distinct ways: a standard approach and one explicitly detailing empathy's cognitive, affective, and compassionate counterparts. Our findings indicate that the average empathy rating of responses generated by ChatGPT exceeds those crafted by humans by approximately 10%. Additionally, instructing ChatGPT to incorporate a clear understanding of empathy in its responses makes the responses align approximately 5 times more closely with the expectations of individuals possessing a high degree of empathy, compared to human responses. The proposed evaluation framework serves as a scalable and adaptable framework to assess the empathetic capabilities of newer and updated versions of large language models, eliminating the need to replicate the current study's results in future research.
Use of a Taxonomy of Empathetic Response Intents to Control and Interpret Empathy in Neural Chatbots
May 17, 2023



A recent trend in the domain of open-domain conversational agents is enabling them to converse empathetically to emotional prompts. Current approaches either follow an end-to-end approach or condition the responses on similar emotion labels to generate empathetic responses. But empathy is a broad concept that refers to the cognitive and emotional reactions of an individual to the observed experiences of another and it is more complex than mere mimicry of emotion. Hence, it requires identifying complex human conversational strategies and dynamics in addition to generic emotions to control and interpret empathetic responding capabilities of chatbots. In this work, we make use of a taxonomy of eight empathetic response intents in addition to generic emotion categories in building a dialogue response generation model capable of generating empathetic responses in a controllable and interpretable manner. It consists of two modules: 1) a response emotion/intent prediction module; and 2) a response generation module. We propose several rule-based and neural approaches to predict the next response's emotion/intent and generate responses conditioned on these predicted emotions/intents. Automatic and human evaluation results emphasize the importance of the use of the taxonomy of empathetic response intents in producing more diverse and empathetically more appropriate responses than end-to-end models.
Boosting Distress Support Dialogue Responses with Motivational Interviewing Strategy
May 17, 2023



AI-driven chatbots have become an emerging solution to address psychological distress. Due to the lack of psychotherapeutic data, researchers use dialogues scraped from online peer support forums to train them. But since the responses in such platforms are not given by professionals, they contain both conforming and non-conforming responses. In this work, we attempt to recognize these conforming and non-conforming response types present in online distress-support dialogues using labels adapted from a well-established behavioral coding scheme named Motivational Interviewing Treatment Integrity (MITI) code and show how some response types could be rephrased into a more MI adherent form that can, in turn, enable chatbot responses to be more compliant with the MI strategy. As a proof of concept, we build several rephrasers by fine-tuning Blender and GPT3 to rephrase MI non-adherent "Advise without permission" responses into "Advise with permission". We show how this can be achieved with the construction of pseudo-parallel corpora avoiding costs for human labor. Through automatic and human evaluation we show that in the presence of less training data, techniques such as prompting and data augmentation can be used to produce substantially good rephrasings that reflect the intended style and preserve the content of the original text.
Approximating Human Evaluation of Social Chatbots with Prompting
Apr 11, 2023Once powerful conversational models have become available for a wide audience, users started actively engaging in social interactions with this technology. Such unprecedented interaction experiences may pose considerable social and psychological risks to the users unless the technology is properly controlled. This creates an urgent need for scalable and robust evaluation metrics for conversational chatbots. Existing automatic evaluation metrics usually focus on objective quality measures and disregard subjective perceptions of social dimensions. Moreover, most of these approaches operate on pre-produced dialogs from available benchmark corpora, which implies human involvement for preparing the material for evaluation and, thus, impeded scalability of the metrics. To address this limitation, we propose to make use of the emerging large language models (LLMs) from the GPT-family and describe a new framework allowing to conduct dialog system evaluation with prompting. With this framework, we are able to achieve full automation of the evaluation pipeline and reach impressive correlation with the human judgement (up to Pearson r=0.95 on system level). The underlying concept is to collect synthetic chat logs of evaluated bots with a LLM in the other-play setting, where LLM is carefully conditioned to follow a specific scenario. We further explore different prompting approaches to produce evaluation scores with the same LLM. The best-performing prompts, containing few-show demonstrations and instructions, show outstanding performance on the tested dataset and demonstrate the ability to generalize to other dialog corpora.
This joke is : Recognizing Humor and Offense with Prompting
Oct 25, 2022



Humor is a magnetic component in everyday human interactions and communications. Computationally modeling humor enables NLP systems to entertain and engage with users. We investigate the effectiveness of prompting, a new transfer learning paradigm for NLP, for humor recognition. We show that prompting performs similarly to finetuning when numerous annotations are available, but gives stellar performance in low-resource humor recognition. The relationship between humor and offense is also inspected by applying influence functions to prompting; we show that models could rely on offense to determine humor during transfer.
AFEC: A Knowledge Graph Capturing Social Intelligence in Casual Conversations
May 22, 2022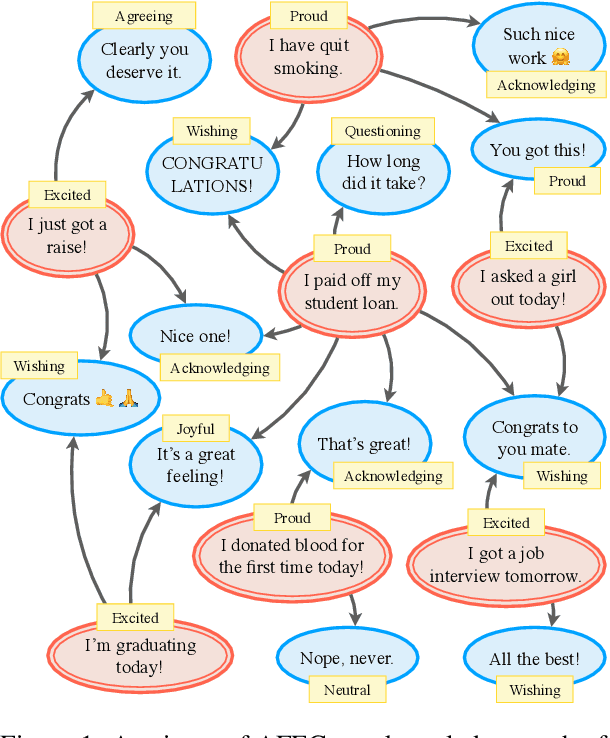



This paper introduces AFEC, an automatically curated knowledge graph based on people's day-to-day casual conversations. The knowledge captured in this graph bears potential for conversational systems to understand how people offer acknowledgement, consoling, and a wide range of empathetic responses in social conversations. For this body of knowledge to be comprehensive and meaningful, we curated a large-scale corpus from the r/CasualConversation SubReddit. After taking the first two turns of all conversations, we obtained 134K speaker nodes and 666K listener nodes. To demonstrate how a chatbot can converse in social settings, we built a retrieval-based chatbot and compared it with existing empathetic dialog models. Experiments show that our model is capable of generating much more diverse responses (at least 15% higher diversity scores in human evaluation), while still outperforming two out of the four baselines in terms of response quality.
How Commonsense Knowledge Helps with Natural Language Tasks: A Survey of Recent Resources and Methodologies
Aug 10, 2021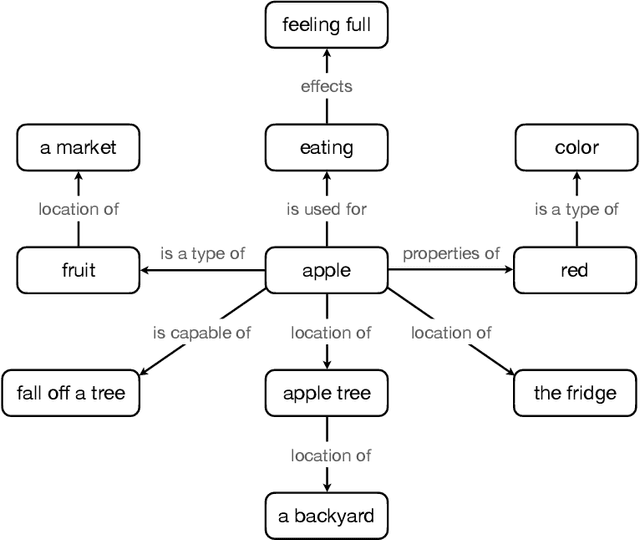
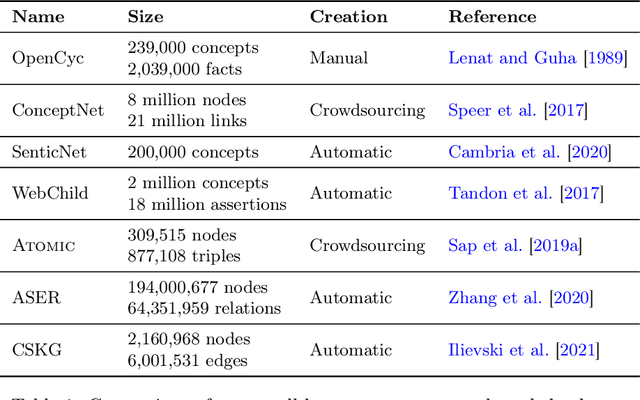
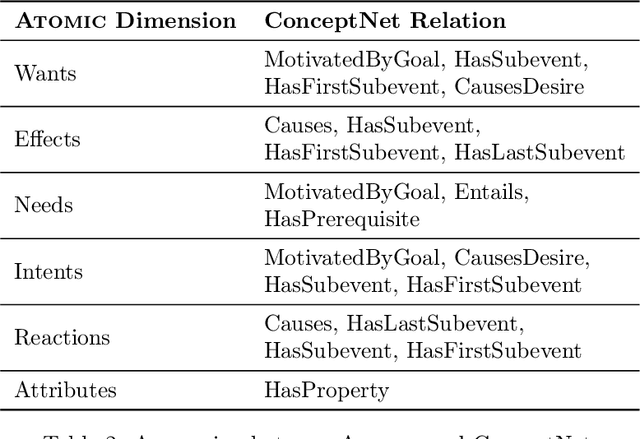
In this paper, we give an overview of commonsense reasoning in natural language processing, which requires a deeper understanding of the contexts and usually involves inference over implicit external knowledge. We first review some popular commonsense knowledge bases and commonsense reasoning benchmarks, but give more emphasis on the methodologies, including recent approaches that aim at solving some general natural language problems that take advantage of external knowledge bases. Finally, we discuss some future directions in pushing the boundary of commonsense reasoning in natural language processing.
Generating Empathetic Responses with a Large Scale Dialog Dataset
May 14, 2021



The task of empathetic response generation aims at generating syntactically correct and, more importantly, emotionally appropriate responses following previous dialog turns. Existing models either directly incorporate pre-defined emotion information to guide the response generation, or use deterministic rules to decide the response emotion, ignoring the subtle emotion interactions captured in human conversations. With the advent of advanced language models, it is possible to learn the nuanced emotional exchanges captured in natural language dialogs. To fully explore the range of emotions and dialog intents, it is important to curate a dataset large enough to shed light on the general understanding of human emotional interactions in our conversations. In this paper, we describe in detail the curation process of a large-scale dialog dataset where each utterance is labeled with one of 32 emotions and 9 intent categories. We then show how to build a multi-turn empathetic dialog model that performs well compared to its baselines over 6,000 human evaluated instances.