 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniCap-IF: Benchmarking and Improving Instruction Following Abilities for Omni-Video Captioning
Jun 07, 2026While Omni-modal Large Language Models (OLLMs) have demonstrated impressive capabilities in jointly processing audio and visual streams, their ability to strictly adhere to complex, multi-faceted user instructions remains largely unexplored. Existing benchmarks primarily focus on holistic video understanding or text-only instruction following, failing to capture the intricate interplay between modalities and user constraints. To bridge this gap, we introduce OmniCap-IF, the first comprehensive benchmark specifically designed to evaluate instruction-following capabilities in omni-modal captioning. OmniCap-IF incorporates a systematic framework that assesses captions on two dimensions: format correctness and content correctness. Our benchmark encompasses 50 distinct constraint types across pure visual, pure audio, and audio-visual modalities, while integrating Temporal Grounding to assess spatio-temporal precision. Extensive evaluations of prominent models on 1,920 high-quality samples reveal significant performance disparities. Furthermore, our analysis uncovers a critical "format-content tradeoff", demonstrating that increasing formatting complexity directly degrades models' omni-modal reasoning abilities. Finally, to advance the field, we curate a 54K instruction-tuning dataset, OmniCap-IF-54K and present OmniCaptioner-IF, which achieves notable improvements in both complex instruction adherence and general omni-modal captioning performance.
What Really is Commonsense Knowledge?
Nov 06, 2024



Commonsense datasets have been well developed in Natural Language Processing, mainly through crowdsource human annotation. However, there are debates on the genuineness of commonsense reasoning benchmarks. In specific, a significant portion of instances in some commonsense benchmarks do not concern commonsense knowledge. That problem would undermine the measurement of the true commonsense reasoning ability of evaluated models. It is also suggested that the problem originated from a blurry concept of commonsense knowledge, as distinguished from other types of knowledge. To demystify all of the above claims, in this study, we survey existing definitions of commonsense knowledge, ground into the three frameworks for defining concepts, and consolidate them into a multi-framework unified definition of commonsense knowledge (so-called consolidated definition). We then use the consolidated definition for annotations and experiments on the CommonsenseQA and CommonsenseQA 2.0 datasets to examine the above claims. Our study shows that there exists a large portion of non-commonsense-knowledge instances in the two datasets, and a large performance gap on these two subsets where Large Language Models (LLMs) perform worse on commonsense-knowledge instances.
This joke is : Recognizing Humor and Offense with Prompting
Oct 25, 2022



Humor is a magnetic component in everyday human interactions and communications. Computationally modeling humor enables NLP systems to entertain and engage with users. We investigate the effectiveness of prompting, a new transfer learning paradigm for NLP, for humor recognition. We show that prompting performs similarly to finetuning when numerous annotations are available, but gives stellar performance in low-resource humor recognition. The relationship between humor and offense is also inspected by applying influence functions to prompting; we show that models could rely on offense to determine humor during transfer.
AFEC: A Knowledge Graph Capturing Social Intelligence in Casual Conversations
May 22, 2022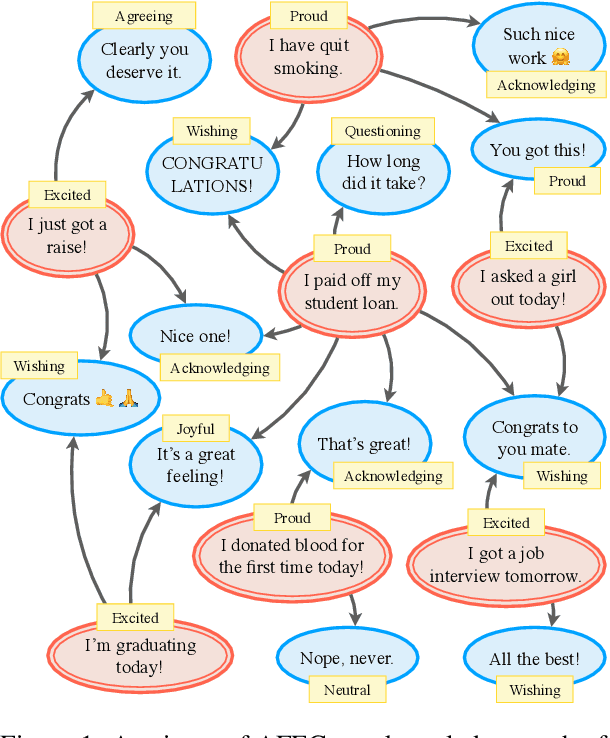



This paper introduces AFEC, an automatically curated knowledge graph based on people's day-to-day casual conversations. The knowledge captured in this graph bears potential for conversational systems to understand how people offer acknowledgement, consoling, and a wide range of empathetic responses in social conversations. For this body of knowledge to be comprehensive and meaningful, we curated a large-scale corpus from the r/CasualConversation SubReddit. After taking the first two turns of all conversations, we obtained 134K speaker nodes and 666K listener nodes. To demonstrate how a chatbot can converse in social settings, we built a retrieval-based chatbot and compared it with existing empathetic dialog models. Experiments show that our model is capable of generating much more diverse responses (at least 15% higher diversity scores in human evaluation), while still outperforming two out of the four baselines in terms of response quality.
Uncertainty and Surprisal Jointly Deliver the Punchline: Exploiting Incongruity-Based Features for Humor Recognition
Dec 22, 2020

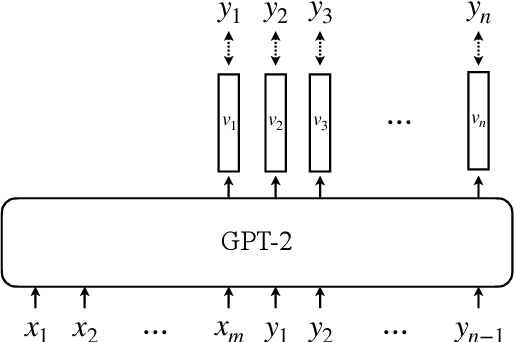

Humor recognition has been widely studied as a text classification problem using data-driven approaches. However, most existing work does not examine the actual joke mechanism to understand humor. We break down any joke into two distinct components: the set-up and the punchline, and further explore the special relationship between them. Inspired by the incongruity theory of humor, we model the set-up as the part developing semantic uncertainty, and the punchline disrupting audience expectations. With increasingly powerful language models, we were able to feed the set-up along with the punchline into the GPT-2 language model, and calculate the uncertainty and surprisal values of the jokes. By conducting experiments on the SemEval 2021 Task 7 dataset, we found that these two features have better capabilities of telling jokes from non-jokes, compared with existing baselines.