 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Federated Approach to Few-Shot Hate Speech Detection for Marginalized Communities
Dec 06, 2024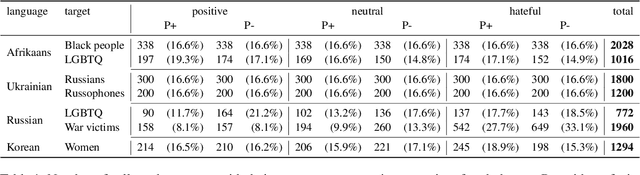
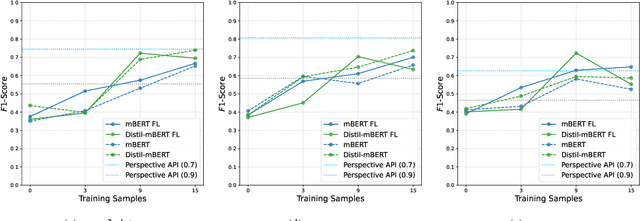
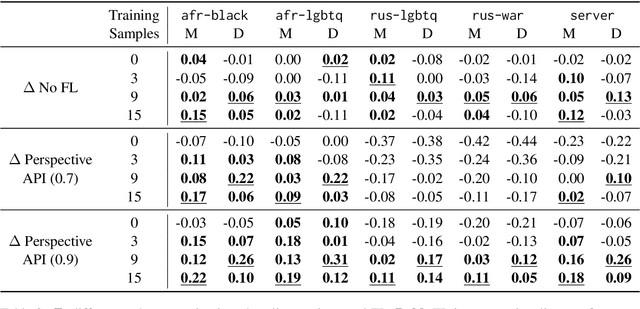
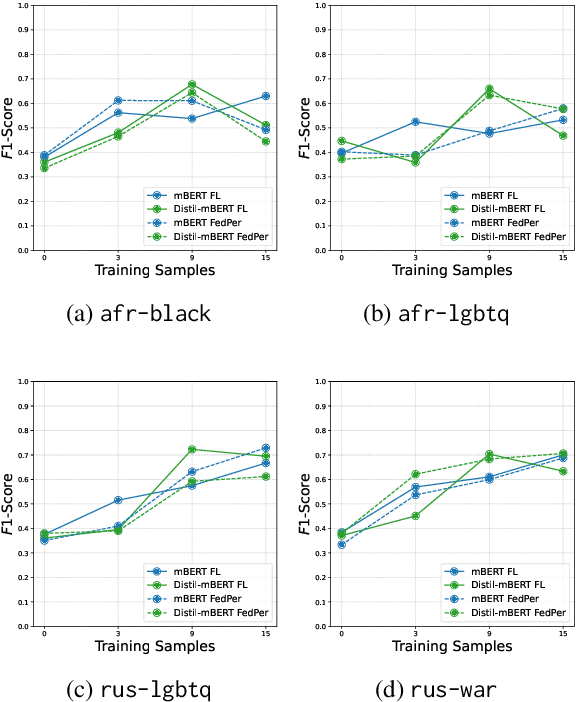
Hate speech online remains an understudied issue for marginalized communities, and has seen rising relevance, especially in the Global South, which includes developing societies with increasing internet penetration. In this paper, we aim to provide marginalized communities living in societies where the dominant language is low-resource with a privacy-preserving tool to protect themselves from hate speech on the internet by filtering offensive content in their native languages. Our contribution in this paper is twofold: 1) we release REACT (REsponsive hate speech datasets Across ConTexts), a collection of high-quality, culture-specific hate speech detection datasets comprising seven distinct target groups in eight low-resource languages, curated by experienced data collectors; 2) we propose a solution to few-shot hate speech detection utilizing federated learning (FL), a privacy-preserving and collaborative learning approach, to continuously improve a central model that exhibits robustness when tackling different target groups and languages. By keeping the training local to the users' devices, we ensure the privacy of the users' data while benefitting from the efficiency of federated learning. Furthermore, we personalize client models to target-specific training data and evaluate their performance. Our results indicate the effectiveness of FL across different target groups, whereas the benefits of personalization on few-shot learning are not clear.
What should I wear to a party in a Greek taverna? Evaluation for Conversational Agents in the Fashion Domain
Aug 13, 2024



Large language models (LLMs) are poised to revolutionize the domain of online fashion retail, enhancing customer experience and discovery of fashion online. LLM-powered conversational agents introduce a new way of discovery by directly interacting with customers, enabling them to express in their own ways, refine their needs, obtain fashion and shopping advice that is relevant to their taste and intent. For many tasks in e-commerce, such as finding a specific product, conversational agents need to convert their interactions with a customer to a specific call to different backend systems, e.g., a search system to showcase a relevant set of products. Therefore, evaluating the capabilities of LLMs to perform those tasks related to calling other services is vital. However, those evaluations are generally complex, due to the lack of relevant and high quality datasets, and do not align seamlessly with business needs, amongst others. To this end, we created a multilingual evaluation dataset of 4k conversations between customers and a fashion assistant in a large e-commerce fashion platform to measure the capabilities of LLMs to serve as an assistant between customers and a backend engine. We evaluate a range of models, showcasing how our dataset scales to business needs and facilitates iterative development of tools.
Politeness Stereotypes and Attack Vectors: Gender Stereotypes in Japanese and Korean Language Models
Jun 16, 2023In efforts to keep up with the rapid progress and use of large language models, gender bias research is becoming more prevalent in NLP. Non-English bias research, however, is still in its infancy with most work focusing on English. In our work, we study how grammatical gender bias relating to politeness levels manifests in Japanese and Korean language models. Linguistic studies in these languages have identified a connection between gender bias and politeness levels, however it is not yet known if language models reproduce these biases. We analyze relative prediction probabilities of the male and female grammatical genders using templates and find that informal polite speech is most indicative of the female grammatical gender, while rude and formal speech is most indicative of the male grammatical gender. Further, we find politeness levels to be an attack vector for allocational gender bias in cyberbullying detection models. Cyberbullies can evade detection through simple techniques abusing politeness levels. We introduce an attack dataset to (i) identify representational gender bias across politeness levels, (ii) demonstrate how gender biases can be abused to bypass cyberbullying detection models and (iii) show that allocational biases can be mitigated via training on our proposed dataset. Through our findings we highlight the importance of bias research moving beyond its current English-centrism.
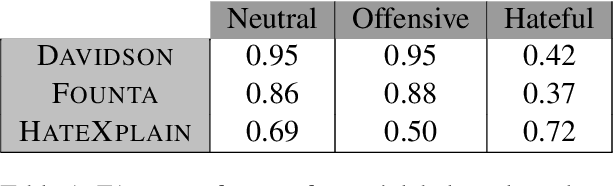
Sociocultural knowledge is needed for selection of shots in hate speech detection tasks
Apr 11, 2023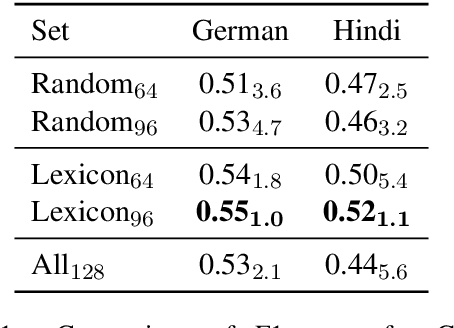
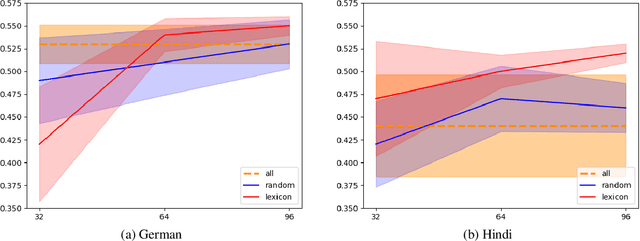
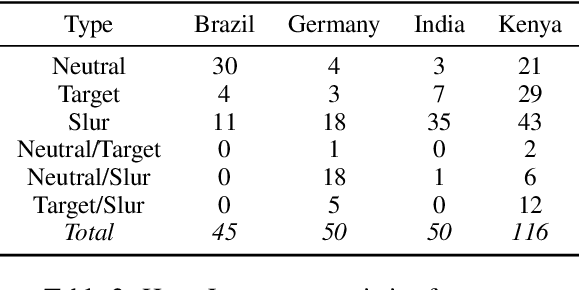
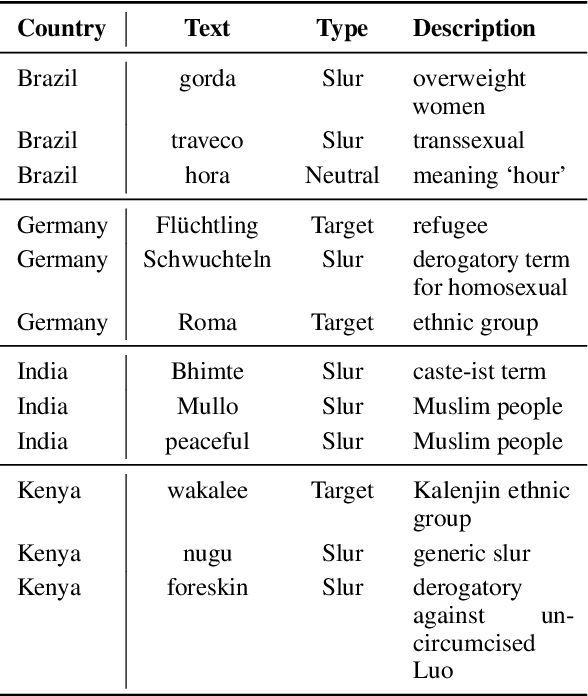
We introduce HATELEXICON, a lexicon of slurs and targets of hate speech for the countries of Brazil, Germany, India and Kenya, to aid training and interpretability of models. We demonstrate how our lexicon can be used to interpret model predictions, showing that models developed to classify extreme speech rely heavily on target words when making predictions. Further, we propose a method to aid shot selection for training in low-resource settings via HATELEXICON. In few-shot learning, the selection of shots is of paramount importance to model performance. In our work, we simulate a few-shot setting for German and Hindi, using HASOC data for training and the Multilingual HateCheck (MHC) as a benchmark. We show that selecting shots based on our lexicon leads to models performing better on MHC than models trained on shots sampled randomly. Thus, when given only a few training examples, using our lexicon to select shots containing more sociocultural information leads to better few-shot performance.
This joke is : Recognizing Humor and Offense with Prompting
Oct 25, 2022



Humor is a magnetic component in everyday human interactions and communications. Computationally modeling humor enables NLP systems to entertain and engage with users. We investigate the effectiveness of prompting, a new transfer learning paradigm for NLP, for humor recognition. We show that prompting performs similarly to finetuning when numerous annotations are available, but gives stellar performance in low-resource humor recognition. The relationship between humor and offense is also inspected by applying influence functions to prompting; we show that models could rely on offense to determine humor during transfer.
Analyzing Hate Speech Data along Racial, Gender and Intersectional Axes
May 18, 2022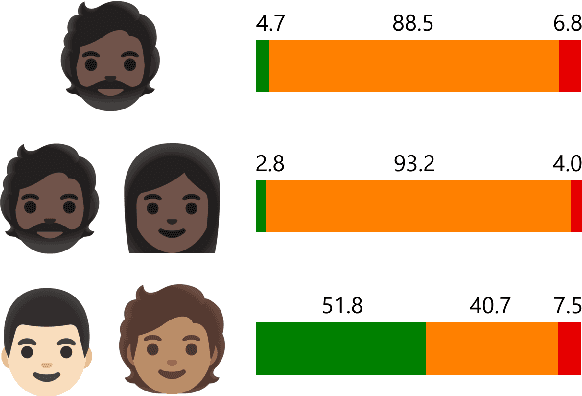


To tackle the rising phenomenon of hate speech, efforts have been made towards data curation and analysis. When it comes to analysis of bias, previous work has focused predominantly on race. In our work, we further investigate bias in hate speech datasets along racial, gender and intersectional axes. We identify strong bias against African American English (AAE), masculine and AAE+Masculine tweets, which are annotated as disproportionately more hateful and offensive than from other demographics. We provide evidence that BERT-based models propagate this bias and show that balancing the training data for these protected attributes can lead to fairer models with regards to gender, but not race.
Listening to Affected Communities to Define Extreme Speech: Dataset and Experiments
Mar 22, 2022
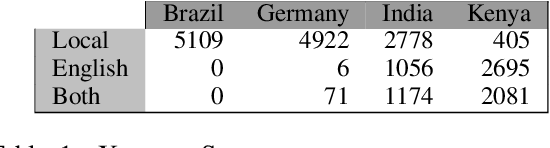

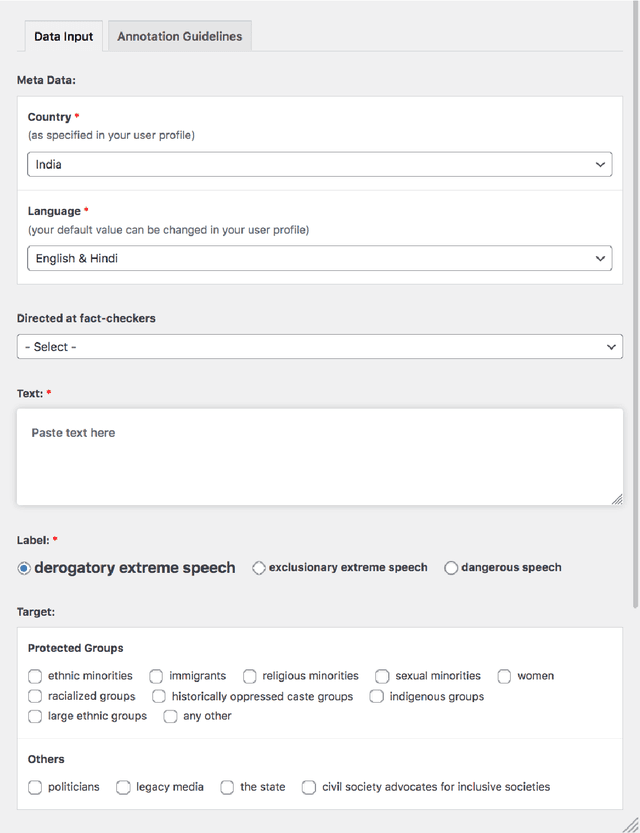
Building on current work on multilingual hate speech (e.g., Ousidhoum et al. (2019)) and hate speech reduction (e.g., Sap et al. (2020)), we present XTREMESPEECH, a new hate speech dataset containing 20,297 social media passages from Brazil, Germany, India and Kenya. The key novelty is that we directly involve the affected communities in collecting and annotating the data - as opposed to giving companies and governments control over defining and combatting hate speech. This inclusive approach results in datasets more representative of actually occurring online speech and is likely to facilitate the removal of the social media content that marginalized communities view as causing the most harm. Based on XTREMESPEECH, we establish novel tasks with accompanying baselines, provide evidence that cross-country training is generally not feasible due to cultural differences between countries and perform an interpretability analysis of BERT's predictions.
BERT Cannot Align Characters
Sep 20, 2021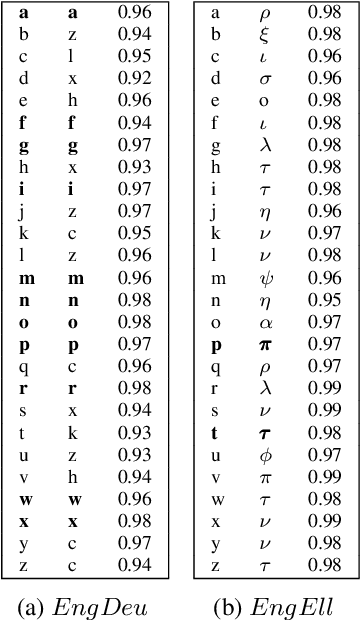
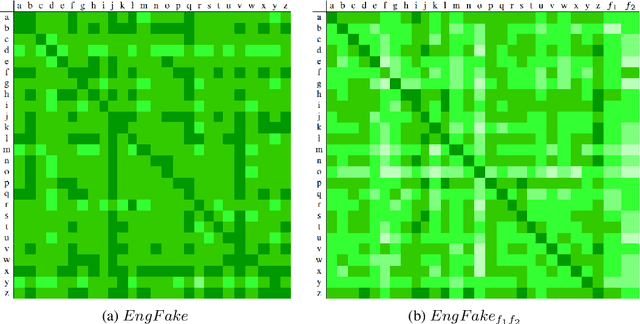
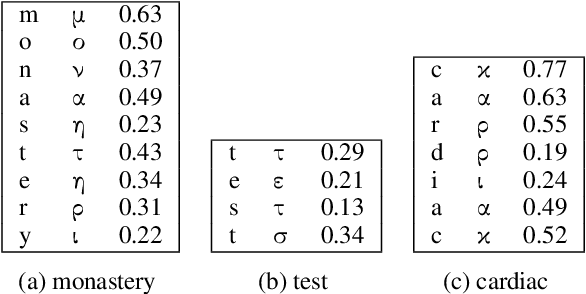
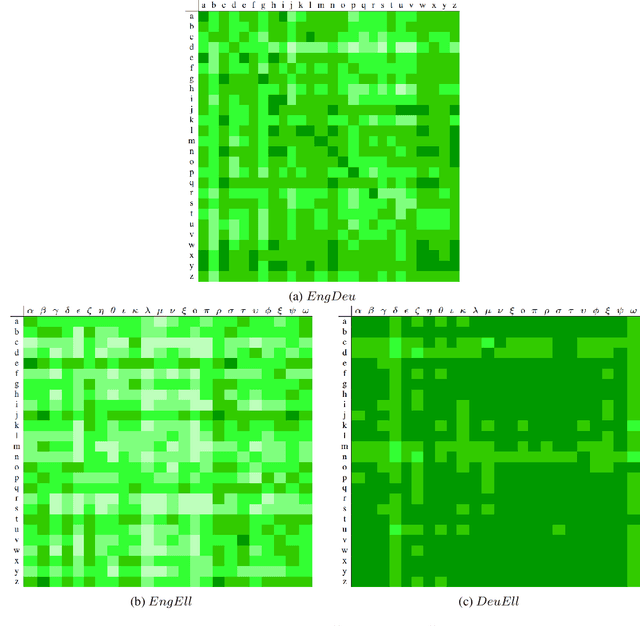
In previous work, it has been shown that BERT can adequately align cross-lingual sentences on the word level. Here we investigate whether BERT can also operate as a char-level aligner. The languages examined are English, Fake-English, German and Greek. We show that the closer two languages are, the better BERT can align them on the character level. BERT indeed works well in English to Fake-English alignment, but this does not generalize to natural languages to the same extent. Nevertheless, the proximity of two languages does seem to be a factor. English is more related to German than to Greek and this is reflected in how well BERT aligns them; English to German is better than English to Greek. We examine multiple setups and show that the similarity matrices for natural languages show weaker relations the further apart two languages are.
Wine is Not v i n. -- On the Compatibility of Tokenizations Across Languages
Sep 13, 2021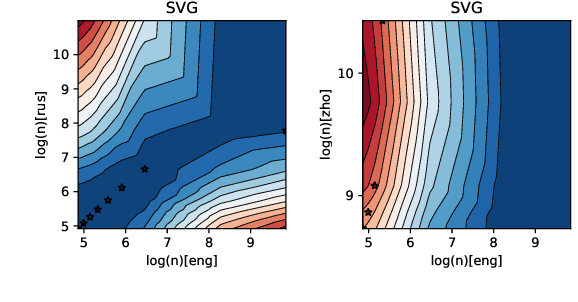
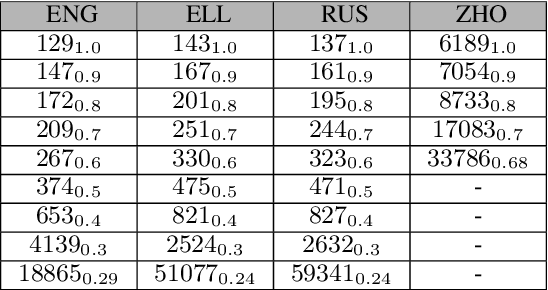
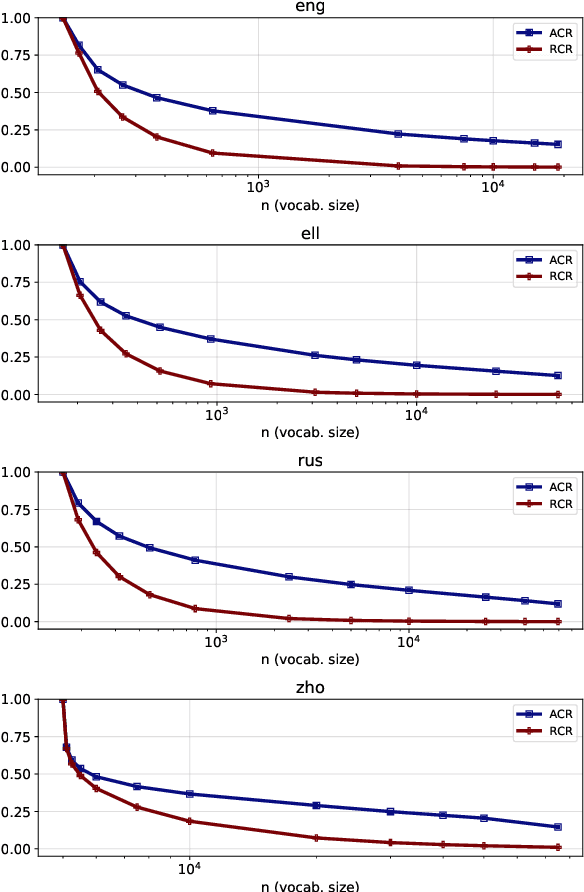
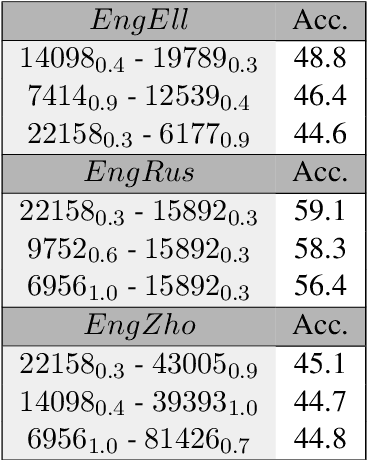
The size of the vocabulary is a central design choice in large pretrained language models, with respect to both performance and memory requirements. Typically, subword tokenization algorithms such as byte pair encoding and WordPiece are used. In this work, we investigate the compatibility of tokenizations for multilingual static and contextualized embedding spaces and propose a measure that reflects the compatibility of tokenizations across languages. Our goal is to prevent incompatible tokenizations, e.g., "wine" (word-level) in English vs.\ "v i n" (character-level) in French, which make it hard to learn good multilingual semantic representations. We show that our compatibility measure allows the system designer to create vocabularies across languages that are compatible -- a desideratum that so far has been neglected in multilingual models.
Transformers Are Better Than Humans at Identifying Generated Text
Sep 29, 2020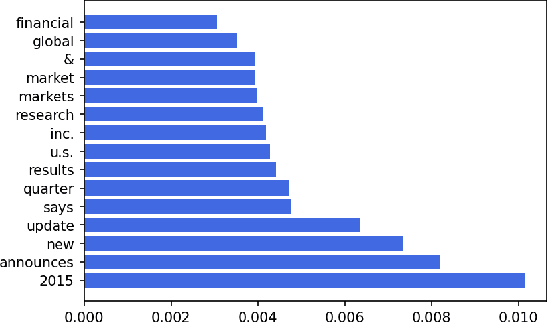
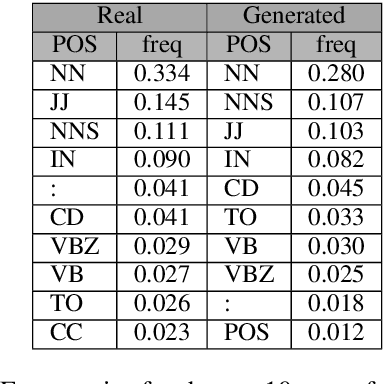
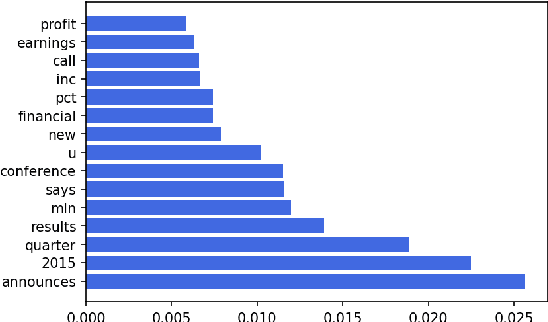
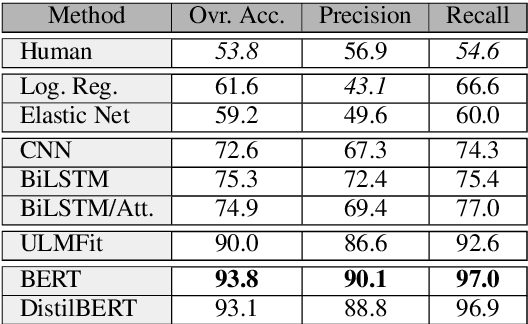
Fake information spread via the internet and social media influences public opinion and user activity. Generative models enable fake content to be generated faster and more cheaply than had previously been possible. This paper examines the problem of identifying fake content generated by lightweight deep learning models. A dataset containing human and machine-generated headlines was created and a user study indicated that humans were only able to identify the fake headlines in 45.3% of the cases. However, the most accurate automatic approach, transformers, achieved an accuracy of 94%, indicating that content generated from language models can be filtered out accurately.