 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe InviTE Corpus: Annotating Invectives in Tudor English Texts for Computational Modeling
Sep 26, 2025In this paper, we aim at the application of Natural Language Processing (NLP) techniques to historical research endeavors, particularly addressing the study of religious invectives in the context of the Protestant Reformation in Tudor England. We outline a workflow spanning from raw data, through pre-processing and data selection, to an iterative annotation process. As a result, we introduce the InviTE corpus -- a corpus of almost 2000 Early Modern English (EModE) sentences, which are enriched with expert annotations regarding invective language throughout 16th-century England. Subsequently, we assess and compare the performance of fine-tuned BERT-based models and zero-shot prompted instruction-tuned large language models (LLMs), which highlights the superiority of models pre-trained on historical data and fine-tuned to invective detection.
A Federated Approach to Few-Shot Hate Speech Detection for Marginalized Communities
Dec 06, 2024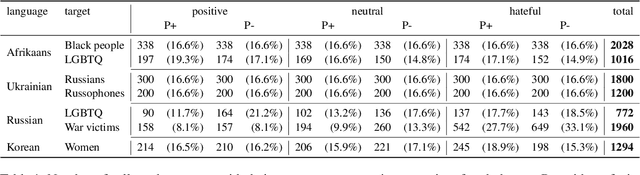
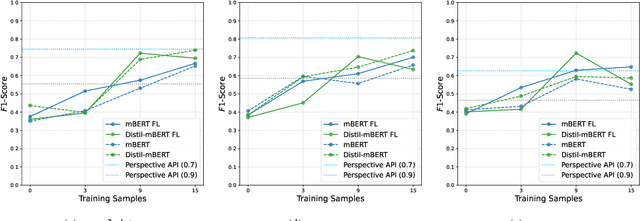
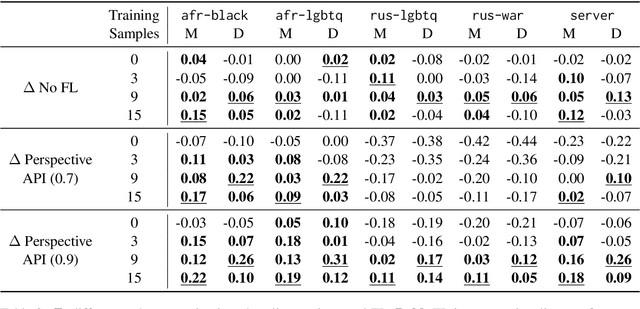
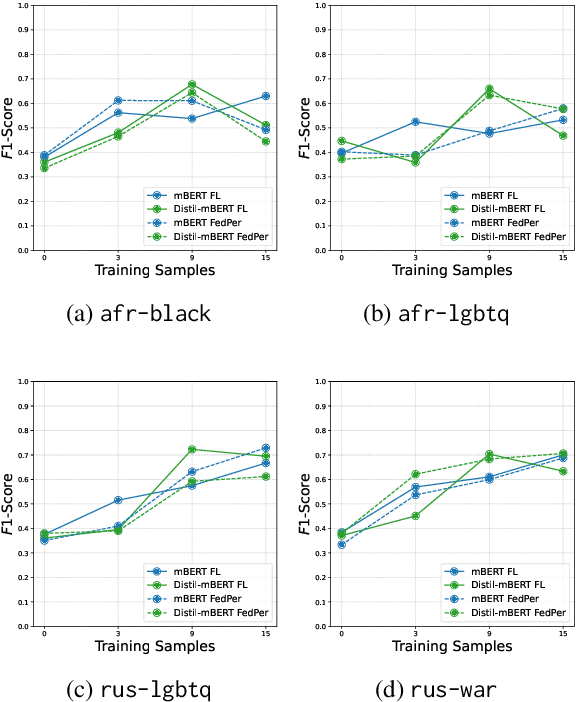
Hate speech online remains an understudied issue for marginalized communities, and has seen rising relevance, especially in the Global South, which includes developing societies with increasing internet penetration. In this paper, we aim to provide marginalized communities living in societies where the dominant language is low-resource with a privacy-preserving tool to protect themselves from hate speech on the internet by filtering offensive content in their native languages. Our contribution in this paper is twofold: 1) we release REACT (REsponsive hate speech datasets Across ConTexts), a collection of high-quality, culture-specific hate speech detection datasets comprising seven distinct target groups in eight low-resource languages, curated by experienced data collectors; 2) we propose a solution to few-shot hate speech detection utilizing federated learning (FL), a privacy-preserving and collaborative learning approach, to continuously improve a central model that exhibits robustness when tackling different target groups and languages. By keeping the training local to the users' devices, we ensure the privacy of the users' data while benefitting from the efficiency of federated learning. Furthermore, we personalize client models to target-specific training data and evaluate their performance. Our results indicate the effectiveness of FL across different target groups, whereas the benefits of personalization on few-shot learning are not clear.