 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWith Argus Eyes: Assessing Retrieval Gaps via Uncertainty Scoring to Detect and Remedy Retrieval Blind Spots
Feb 10, 2026Reliable retrieval-augmented generation (RAG) systems depend fundamentally on the retriever's ability to find relevant information. We show that neural retrievers used in RAG systems have blind spots, which we define as the failure to retrieve entities that are relevant to the query, but have low similarity to the query embedding. We investigate the training-induced biases that cause such blind spot entities to be mapped to inaccessible parts of the embedding space, resulting in low retrievability. Using a large-scale dataset constructed from Wikidata relations and first paragraphs of Wikipedia, and our proposed Retrieval Probability Score (RPS), we show that blind spot risk in standard retrievers (e.g., CONTRIEVER, REASONIR) can be predicted pre-index from entity embedding geometry, avoiding expensive retrieval evaluations. To address these blind spots, we introduce ARGUS, a pipeline that enables the retrievability of high-risk (low-RPS) entities through targeted document augmentation from a knowledge base (KB), first paragraphs of Wikipedia, in our case. Extensive experiments on BRIGHT, IMPLIRET, and RAR-B show that ARGUS achieves consistent improvements across all evaluated retrievers (averaging +3.4 nDCG@5 and +4.5 nDCG@10 absolute points), with substantially larger gains in challenging subsets. These results establish that preemptively remedying blind spots is critical for building robust and trustworthy RAG systems (Code and Data).
Language Models with Rationality
May 23, 2023
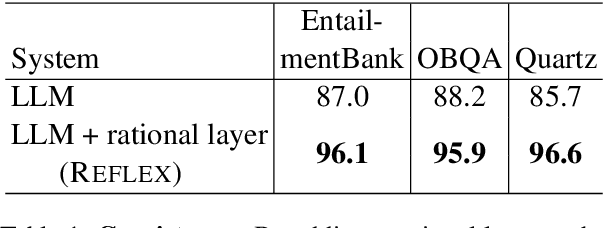


While large language models (LLMs) are proficient at question-answering (QA), the dependencies between their answers and other "beliefs" they may have about the world are typically unstated, and may even be in conflict. Our goal is to uncover such dependencies and reduce inconsistencies among them, so that answers are supported by faithful, system-believed chains of reasoning drawn from a consistent network of beliefs. Our approach, which we call REFLEX, is to add a "rational", self-reflecting layer on top of the LLM. First, given a question, we construct a belief graph using a backward-chaining process to materialize relevant model "beliefs" (including beliefs about answer candidates) and the inferential relationships between them. Second, we identify and minimize contradictions in that graph using a formal constraint reasoner. We find that REFLEX significantly improves consistency (by 8%-11% absolute) without harming overall answer accuracy, resulting in answers supported by faithful chains of reasoning drawn from a more consistent belief system. This suggests a new style of system architecture, in which an LLM extended with a rational layer of self-reflection can repair latent inconsistencies within the LLM alone.
Enriching a Model's Notion of Belief using a Persistent Memory
Apr 16, 2021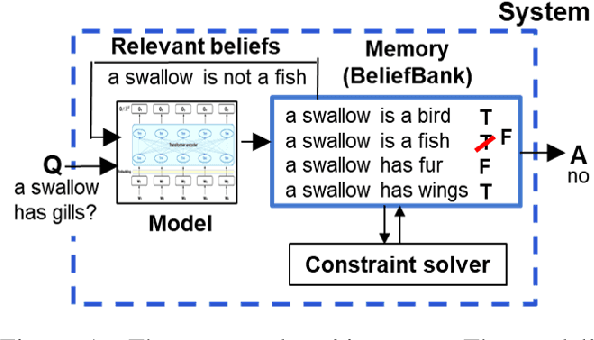

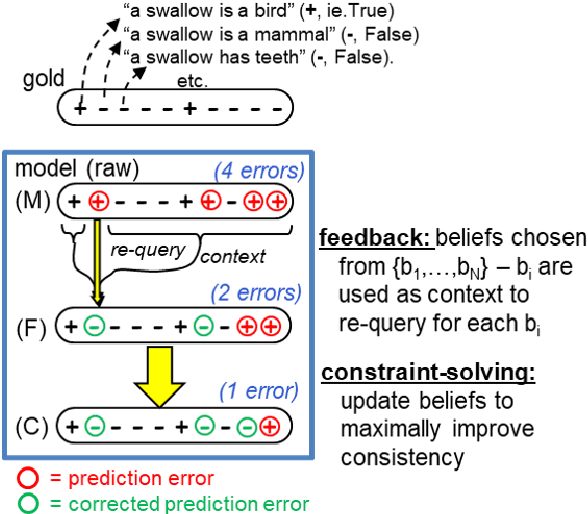
Although pretrained language models (PTLMs) have been shown to contain significant amounts of world knowledge, they can still produce inconsistent answers to questions when probed, even after using specialized training techniques to reduce inconsistency. As a result, it can be hard to identify what the model actually "believes" about the world. Our goal is to reduce this problem, so systems are more globally consistent and accurate in their answers. Our approach is to add a memory component - a BeliefBank - that records a model's answers, and two mechanisms that use it to improve consistency among beliefs. First, a reasoning component - a weighted SAT solver - improves consistency by flipping answers that significantly clash with others. Second, a feedback component re-queries the model but using known beliefs as context. We show that, in a controlled experimental setting, these two mechanisms improve both accuracy and consistency. This is significant as it is a first step towards endowing models with an evolving memory, allowing them to construct a more coherent picture of the world.
Transformers Are Better Than Humans at Identifying Generated Text
Sep 29, 2020
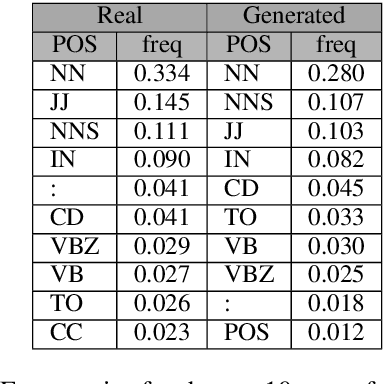
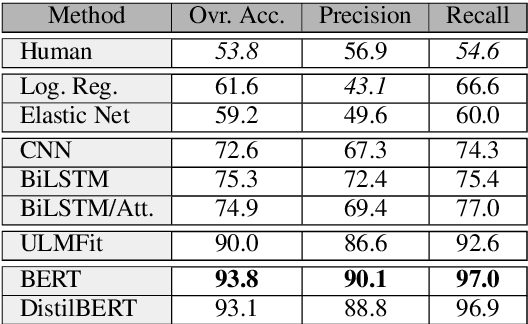
Fake information spread via the internet and social media influences public opinion and user activity. Generative models enable fake content to be generated faster and more cheaply than had previously been possible. This paper examines the problem of identifying fake content generated by lightweight deep learning models. A dataset containing human and machine-generated headlines was created and a user study indicated that humans were only able to identify the fake headlines in 45.3% of the cases. However, the most accurate automatic approach, transformers, achieved an accuracy of 94%, indicating that content generated from language models can be filtered out accurately.