 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Can Reasoning Models Identify and Recover from Unhelpful Thoughts?
Jun 12, 2025Recent reasoning models show the ability to reflect, backtrack, and self-validate their reasoning, which is crucial in spotting mistakes and arriving at accurate solutions. A natural question that arises is how effectively models can perform such self-reevaluation. We tackle this question by investigating how well reasoning models identify and recover from four types of unhelpful thoughts: uninformative rambling thoughts, thoughts irrelevant to the question, thoughts misdirecting the question as a slightly different question, and thoughts that lead to incorrect answers. We show that models are effective at identifying most unhelpful thoughts but struggle to recover from the same thoughts when these are injected into their thinking process, causing significant performance drops. Models tend to naively continue the line of reasoning of the injected irrelevant thoughts, which showcases that their self-reevaluation abilities are far from a general "meta-cognitive" awareness. Moreover, we observe non/inverse-scaling trends, where larger models struggle more than smaller ones to recover from short irrelevant thoughts, even when instructed to reevaluate their reasoning. We demonstrate the implications of these findings with a jailbreak experiment using irrelevant thought injection, showing that the smallest models are the least distracted by harmful-response-triggering thoughts. Overall, our findings call for improvement in self-reevaluation of reasoning models to develop better reasoning and safer systems.
Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?
Nov 25, 2024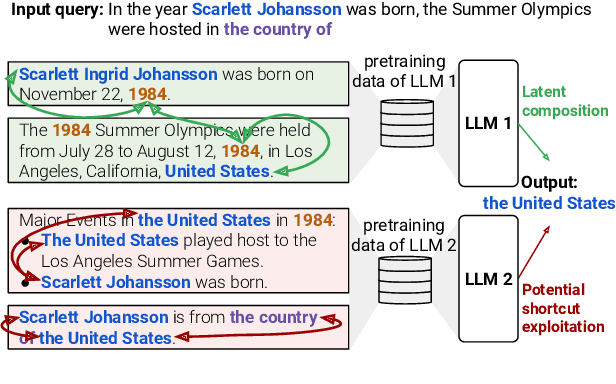
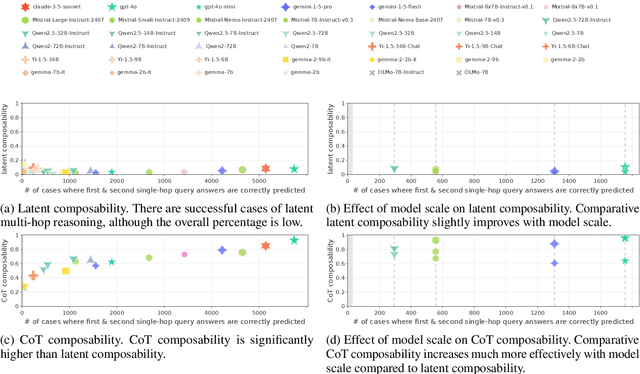

We evaluate how well Large Language Models (LLMs) latently recall and compose facts to answer multi-hop queries like "In the year Scarlett Johansson was born, the Summer Olympics were hosted in the country of". One major challenge in evaluating this ability is that LLMs may have developed shortcuts by encounters of the head entity "Scarlett Johansson" and the answer entity "United States" in the same training sequences or merely guess the answer based on frequency-based priors. To prevent shortcuts, we exclude test queries where the head and answer entities co-appear in pretraining corpora. Through careful selection of relations and facts and systematic removal of cases where models might guess answers or exploit partial matches, we construct an evaluation dataset SOCRATES (ShOrtCut-fRee lATent rEaSoning). We observe that LLMs demonstrate promising latent multi-hop reasoning abilities without exploiting shortcuts, but only for certain types of queries. For queries requiring latent recall of countries as the intermediate answer, the best models achieve 80% latent composability, but this drops to just 5% for the recall of years. Comparisons with Chain-of-Thought composability highlight a significant gap between the ability of models to reason latently versus explicitly. Analysis reveals that latent representations of the intermediate answer are constructed more often in queries with higher latent composability, and shows the emergence of latent multi-hop reasoning during pretraining.
Do Large Language Models Latently Perform Multi-Hop Reasoning?
Feb 26, 2024



We study whether Large Language Models (LLMs) latently perform multi-hop reasoning with complex prompts such as "The mother of the singer of 'Superstition' is". We look for evidence of a latent reasoning pathway where an LLM (1) latently identifies "the singer of 'Superstition'" as Stevie Wonder, the bridge entity, and (2) uses its knowledge of Stevie Wonder's mother to complete the prompt. We analyze these two hops individually and consider their co-occurrence as indicative of latent multi-hop reasoning. For the first hop, we test if changing the prompt to indirectly mention the bridge entity instead of any other entity increases the LLM's internal recall of the bridge entity. For the second hop, we test if increasing this recall causes the LLM to better utilize what it knows about the bridge entity. We find strong evidence of latent multi-hop reasoning for the prompts of certain relation types, with the reasoning pathway used in more than 80% of the prompts. However, the utilization is highly contextual, varying across different types of prompts. Also, on average, the evidence for the second hop and the full multi-hop traversal is rather moderate and only substantial for the first hop. Moreover, we find a clear scaling trend with increasing model size for the first hop of reasoning but not for the second hop. Our experimental findings suggest potential challenges and opportunities for future development and applications of LLMs.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Multilingual End to End Entity Linking
Jun 15, 2023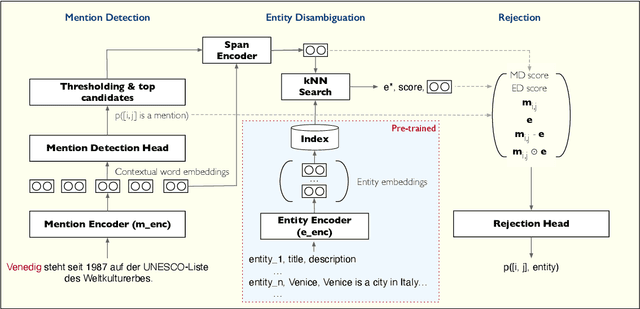
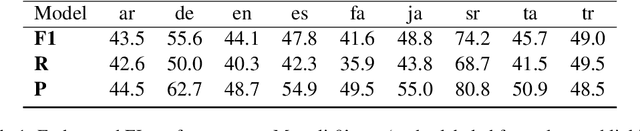

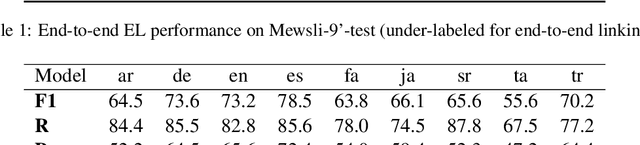
Entity Linking is one of the most common Natural Language Processing tasks in practical applications, but so far efficient end-to-end solutions with multilingual coverage have been lacking, leading to complex model stacks. To fill this gap, we release and open source BELA, the first fully end-to-end multilingual entity linking model that efficiently detects and links entities in texts in any of 97 languages. We provide here a detailed description of the model and report BELA's performance on four entity linking datasets covering high- and low-resource languages.
Glot500: Scaling Multilingual Corpora and Language Models to 500 Languages
May 26, 2023



The NLP community has mainly focused on scaling Large Language Models (LLMs) vertically, i.e., making them better for about 100 languages. We instead scale LLMs horizontally: we create, through continued pretraining, Glot500-m, an LLM that covers 511 predominantly low-resource languages. An important part of this effort is to collect and clean Glot500-c, a corpus that covers these 511 languages and allows us to train Glot500-m. We evaluate Glot500-m on five diverse tasks across these languages. We observe large improvements for both high-resource and low-resource languages compared to an XLM-R baseline. Our analysis shows that no single factor explains the quality of multilingual LLM representations. Rather, a combination of factors determines quality including corpus size, script, "help" from related languages and the total capacity of the model. Our work addresses an important goal of NLP research: we should not limit NLP to a small fraction of the world's languages and instead strive to support as many languages as possible to bring the benefits of NLP technology to all languages and cultures. Code, data and models are available at https://github.com/cisnlp/Glot500.
Language Models with Rationality
May 23, 2023
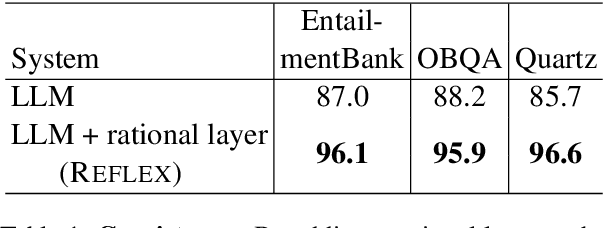


While large language models (LLMs) are proficient at question-answering (QA), the dependencies between their answers and other "beliefs" they may have about the world are typically unstated, and may even be in conflict. Our goal is to uncover such dependencies and reduce inconsistencies among them, so that answers are supported by faithful, system-believed chains of reasoning drawn from a consistent network of beliefs. Our approach, which we call REFLEX, is to add a "rational", self-reflecting layer on top of the LLM. First, given a question, we construct a belief graph using a backward-chaining process to materialize relevant model "beliefs" (including beliefs about answer candidates) and the inferential relationships between them. Second, we identify and minimize contradictions in that graph using a formal constraint reasoner. We find that REFLEX significantly improves consistency (by 8%-11% absolute) without harming overall answer accuracy, resulting in answers supported by faithful chains of reasoning drawn from a more consistent belief system. This suggests a new style of system architecture, in which an LLM extended with a rational layer of self-reflection can repair latent inconsistencies within the LLM alone.
Polar Ducks and Where to Find Them: Enhancing Entity Linking with Duck Typing and Polar Box Embeddings
May 19, 2023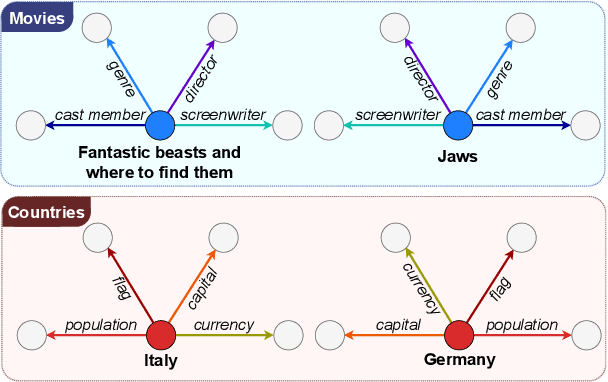
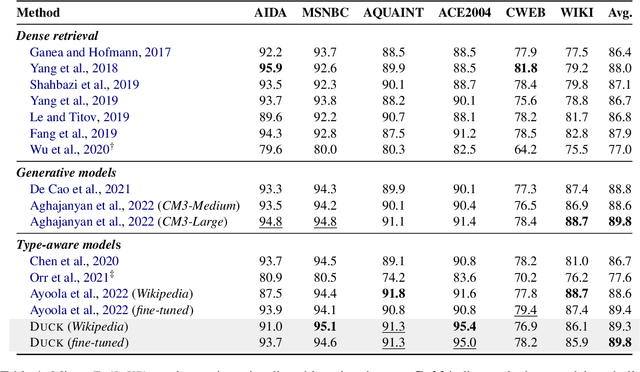
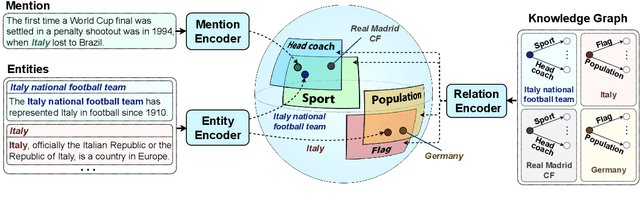
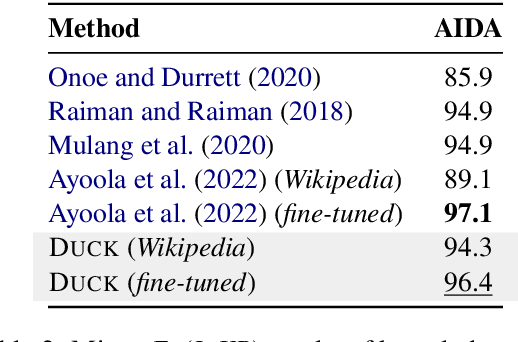
Entity linking methods based on dense retrieval are an efficient and widely used solution in large-scale applications, but they fall short of the performance of generative models, as they are sensitive to the structure of the embedding space. In order to address this issue, this paper introduces DUCK, an approach to infusing structural information in the space of entity representations, using prior knowledge of entity types. Inspired by duck typing in programming languages, we propose to define the type of an entity based on the relations that it has with other entities in a knowledge graph. Then, porting the concept of box embeddings to spherical polar coordinates, we propose to represent relations as boxes on the hypersphere. We optimize the model to cluster entities of similar type by placing them inside the boxes corresponding to their relations. Our experiments show that our method sets new state-of-the-art results on standard entity-disambiguation benchmarks, it improves the performance of the model by up to 7.9 F1 points, outperforms other type-aware approaches, and matches the results of generative models with 18 times more parameters.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Measuring Causal Effects of Data Statistics on Language Model's `Factual' Predictions
Jul 28, 2022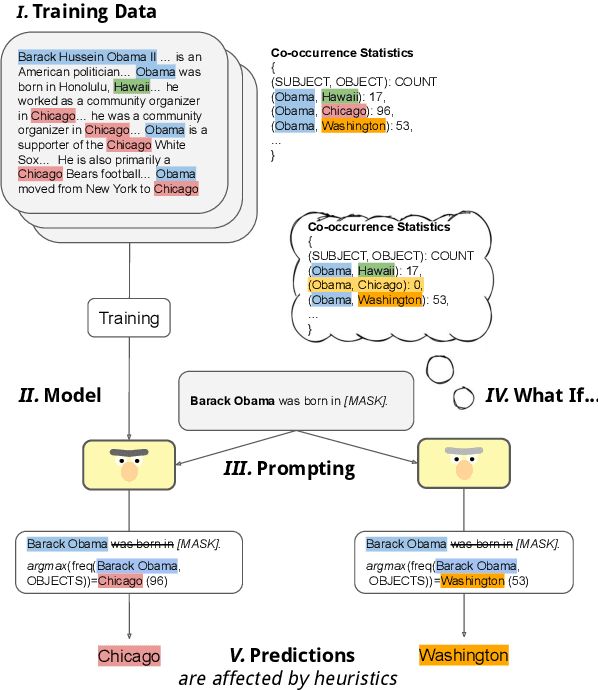

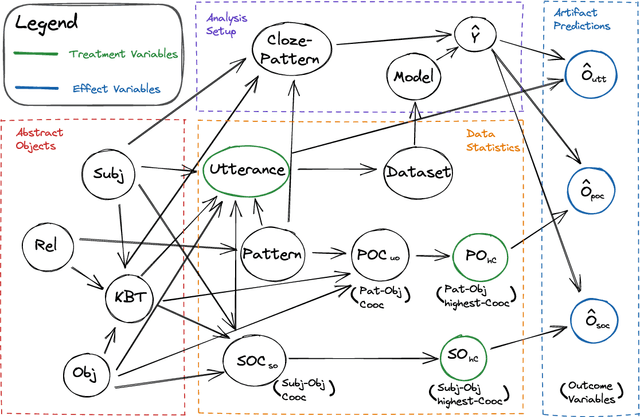

Large amounts of training data are one of the major reasons for the high performance of state-of-the-art NLP models. But what exactly in the training data causes a model to make a certain prediction? We seek to answer this question by providing a language for describing how training data influences predictions, through a causal framework. Importantly, our framework bypasses the need to retrain expensive models and allows us to estimate causal effects based on observational data alone. Addressing the problem of extracting factual knowledge from pretrained language models (PLMs), we focus on simple data statistics such as co-occurrence counts and show that these statistics do influence the predictions of PLMs, suggesting that such models rely on shallow heuristics. Our causal framework and our results demonstrate the importance of studying datasets and the benefits of causality for understanding NLP models.