 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models with Rationality
Paper and Code
May 23, 2023
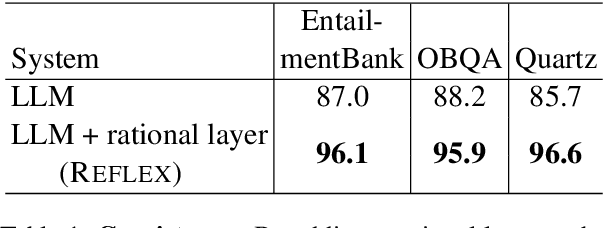


While large language models (LLMs) are proficient at question-answering (QA), the dependencies between their answers and other "beliefs" they may have about the world are typically unstated, and may even be in conflict. Our goal is to uncover such dependencies and reduce inconsistencies among them, so that answers are supported by faithful, system-believed chains of reasoning drawn from a consistent network of beliefs. Our approach, which we call REFLEX, is to add a "rational", self-reflecting layer on top of the LLM. First, given a question, we construct a belief graph using a backward-chaining process to materialize relevant model "beliefs" (including beliefs about answer candidates) and the inferential relationships between them. Second, we identify and minimize contradictions in that graph using a formal constraint reasoner. We find that REFLEX significantly improves consistency (by 8%-11% absolute) without harming overall answer accuracy, resulting in answers supported by faithful chains of reasoning drawn from a more consistent belief system. This suggests a new style of system architecture, in which an LLM extended with a rational layer of self-reflection can repair latent inconsistencies within the LLM alone.