 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite
Oct 24, 2025AI agents hold the potential to revolutionize scientific productivity by automating literature reviews, replicating experiments, analyzing data, and even proposing new directions of inquiry; indeed, there are now many such agents, ranging from general-purpose "deep research" systems to specialized science-specific agents, such as AI Scientist and AIGS. Rigorous evaluation of these agents is critical for progress. Yet existing benchmarks fall short on several fronts: they (1) fail to provide holistic, product-informed measures of real-world use cases such as science research; (2) lack reproducible agent tools necessary for a controlled comparison of core agentic capabilities; (3) do not account for confounding variables such as model cost and tool access; (4) do not provide standardized interfaces for quick agent prototyping and evaluation; and (5) lack comprehensive baseline agents necessary to identify true advances. In response, we define principles and tooling for more rigorously benchmarking agents. Using these, we present AstaBench, a suite that provides the first holistic measure of agentic ability to perform scientific research, comprising 2400+ problems spanning the entire scientific discovery process and multiple scientific domains, and including many problems inspired by actual user requests to deployed Asta agents. Our suite comes with the first scientific research environment with production-grade search tools that enable controlled, reproducible evaluation, better accounting for confounders. Alongside, we provide a comprehensive suite of nine science-optimized classes of Asta agents and numerous baselines. Our extensive evaluation of 57 agents across 22 agent classes reveals several interesting findings, most importantly that despite meaningful progress on certain individual aspects, AI remains far from solving the challenge of science research assistance.
ZebraLogic: On the Scaling Limits of LLMs for Logical Reasoning
Feb 03, 2025



We investigate the logical reasoning capabilities of large language models (LLMs) and their scalability in complex non-monotonic reasoning. To this end, we introduce ZebraLogic, a comprehensive evaluation framework for assessing LLM reasoning performance on logic grid puzzles derived from constraint satisfaction problems (CSPs). ZebraLogic enables the generation of puzzles with controllable and quantifiable complexity, facilitating a systematic study of the scaling limits of models such as Llama, o1 models, and DeepSeek-R1. By encompassing a broad range of search space complexities and diverse logical constraints, ZebraLogic provides a structured environment to evaluate reasoning under increasing difficulty. Our results reveal a significant decline in accuracy as problem complexity grows -- a phenomenon we term the curse of complexity. This limitation persists even with larger models and increased inference-time computation, suggesting inherent constraints in current LLM reasoning capabilities. Additionally, we explore strategies to enhance logical reasoning, including Best-of-N sampling, backtracking mechanisms, and self-verification prompts. Our findings offer critical insights into the scalability of LLM reasoning, highlight fundamental limitations, and outline potential directions for improvement.
Understanding the Logic of Direct Preference Alignment through Logic
Dec 23, 2024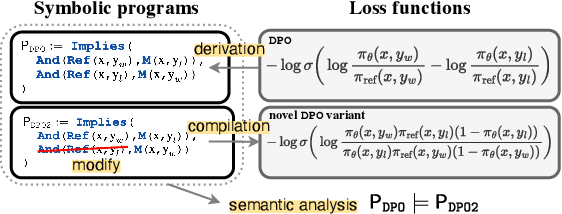


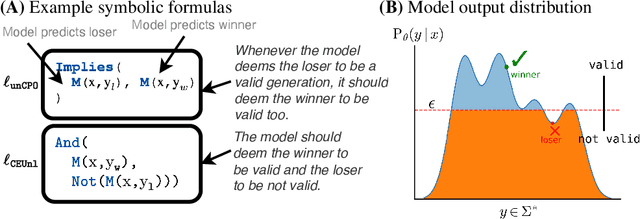
Recent direct preference alignment algorithms (DPA), such as DPO, have shown great promise in aligning large language models to human preferences. While this has motivated the development of many new variants of the original DPO loss, understanding the differences between these recent proposals, as well as developing new DPA loss functions, remains difficult given the lack of a technical and conceptual framework for reasoning about the underlying semantics of these algorithms. In this paper, we attempt to remedy this by formalizing DPA losses in terms of discrete reasoning problems. Specifically, we ask: Given an existing DPA loss, can we systematically derive a symbolic expression that characterizes its semantics? How do the semantics of two losses relate to each other? We propose a novel formalism for characterizing preference losses for single model and reference model based approaches, and identify symbolic forms for a number of commonly used DPA variants. Further, we show how this formal view of preference learning sheds new light on both the size and structure of the DPA loss landscape, making it possible to not only rigorously characterize the relationships between recent loss proposals but also to systematically explore the landscape and derive new loss functions from first principles. We hope our framework and findings will help provide useful guidance to those working on human AI alignment.
SUPER: Evaluating Agents on Setting Up and Executing Tasks from Research Repositories
Sep 11, 2024Given that Large Language Models (LLMs) have made significant progress in writing code, can they now be used to autonomously reproduce results from research repositories? Such a capability would be a boon to the research community, helping researchers validate, understand, and extend prior work. To advance towards this goal, we introduce SUPER, the first benchmark designed to evaluate the capability of LLMs in setting up and executing tasks from research repositories. SUPERaims to capture the realistic challenges faced by researchers working with Machine Learning (ML) and Natural Language Processing (NLP) research repositories. Our benchmark comprises three distinct problem sets: 45 end-to-end problems with annotated expert solutions, 152 sub problems derived from the expert set that focus on specific challenges (e.g., configuring a trainer), and 602 automatically generated problems for larger-scale development. We introduce various evaluation measures to assess both task success and progress, utilizing gold solutions when available or approximations otherwise. We show that state-of-the-art approaches struggle to solve these problems with the best model (GPT-4o) solving only 16.3% of the end-to-end set, and 46.1% of the scenarios. This illustrates the challenge of this task, and suggests that SUPER can serve as a valuable resource for the community to make and measure progress.
SelfGoal: Your Language Agents Already Know How to Achieve High-level Goals
Jun 07, 2024



Language agents powered by large language models (LLMs) are increasingly valuable as decision-making tools in domains such as gaming and programming. However, these agents often face challenges in achieving high-level goals without detailed instructions and in adapting to environments where feedback is delayed. In this paper, we present SelfGoal, a novel automatic approach designed to enhance agents' capabilities to achieve high-level goals with limited human prior and environmental feedback. The core concept of SelfGoal involves adaptively breaking down a high-level goal into a tree structure of more practical subgoals during the interaction with environments while identifying the most useful subgoals and progressively updating this structure. Experimental results demonstrate that SelfGoal significantly enhances the performance of language agents across various tasks, including competitive, cooperative, and deferred feedback environments. Project page: https://selfgoal-agent.github.io.
TimeArena: Shaping Efficient Multitasking Language Agents in a Time-Aware Simulation
Feb 08, 2024Despite remarkable advancements in emulating human-like behavior through Large Language Models (LLMs), current textual simulations do not adequately address the notion of time. To this end, we introduce TimeArena, a novel textual simulated environment that incorporates complex temporal dynamics and constraints that better reflect real-life planning scenarios. In TimeArena, agents are asked to complete multiple tasks as soon as possible, allowing for parallel processing to save time. We implement the dependency between actions, the time duration for each action, and the occupancy of the agent and the objects in the environment. TimeArena grounds to 30 real-world tasks in cooking, household activities, and laboratory work. We conduct extensive experiments with various state-of-the-art LLMs using TimeArena. Our findings reveal that even the most powerful models, e.g., GPT-4, still lag behind humans in effective multitasking, underscoring the need for enhanced temporal awareness in the development of language agents.
OLMo: Accelerating the Science of Language Models
Feb 07, 2024
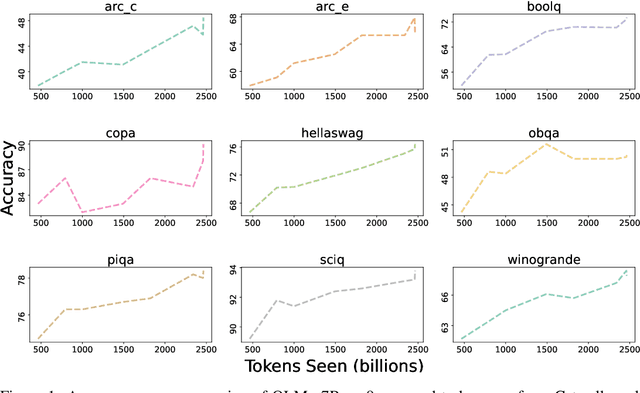
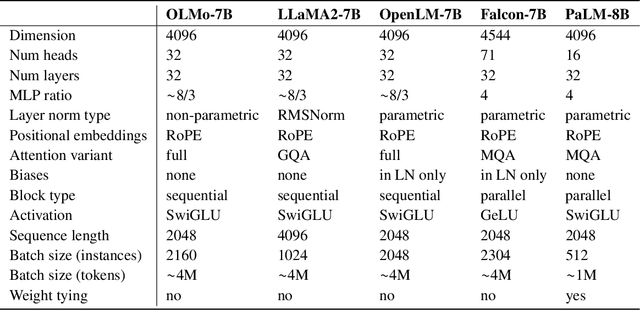
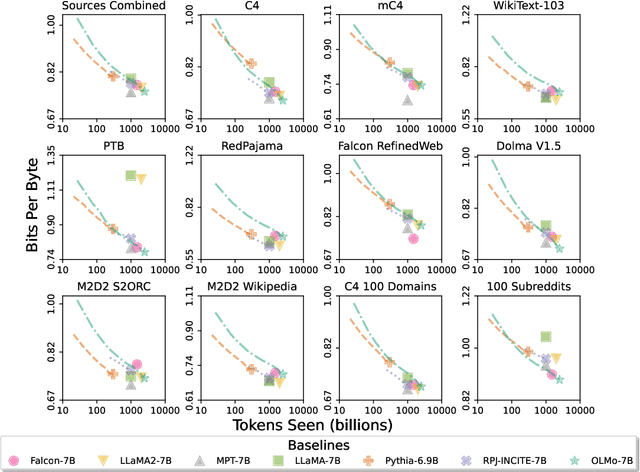
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
Jan 31, 2024



Language models have become a critical technology to tackling a wide range of natural language processing tasks, yet many details about how the best-performing language models were developed are not reported. In particular, information about their pretraining corpora is seldom discussed: commercial language models rarely provide any information about their data; even open models rarely release datasets they are trained on, or an exact recipe to reproduce them. As a result, it is challenging to conduct certain threads of language modeling research, such as understanding how training data impacts model capabilities and shapes their limitations. To facilitate open research on language model pretraining, we release Dolma, a three trillion tokens English corpus, built from a diverse mixture of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials. In addition, we open source our data curation toolkit to enable further experimentation and reproduction of our work. In this report, we document Dolma, including its design principles, details about its construction, and a summary of its contents. We interleave this report with analyses and experimental results from training language models on intermediate states of Dolma to share what we have learned about important data curation practices, including the role of content or quality filters, deduplication, and multi-source mixing. Dolma has been used to train OLMo, a state-of-the-art, open language model and framework designed to build and study the science of language modeling.
Paloma: A Benchmark for Evaluating Language Model Fit
Dec 16, 2023Language models (LMs) commonly report perplexity on monolithic data held out from training. Implicitly or explicitly, this data is composed of domains$\unicode{x2013}$varying distributions of language. Rather than assuming perplexity on one distribution extrapolates to others, Perplexity Analysis for Language Model Assessment (Paloma), measures LM fit to 585 text domains, ranging from nytimes.com to r/depression on Reddit. We invite submissions to our benchmark and organize results by comparability based on compliance with guidelines such as removal of benchmark contamination from pretraining. Submissions can also record parameter and training token count to make comparisons of Pareto efficiency for performance as a function of these measures of cost. We populate our benchmark with results from 6 baselines pretrained on popular corpora. In case studies, we demonstrate analyses that are possible with Paloma, such as finding that pretraining without data beyond Common Crawl leads to inconsistent fit to many domains.
Catwalk: A Unified Language Model Evaluation Framework for Many Datasets
Dec 15, 2023The success of large language models has shifted the evaluation paradigms in natural language processing (NLP). The community's interest has drifted towards comparing NLP models across many tasks, domains, and datasets, often at an extreme scale. This imposes new engineering challenges: efforts in constructing datasets and models have been fragmented, and their formats and interfaces are incompatible. As a result, it often takes extensive (re)implementation efforts to make fair and controlled comparisons at scale. Catwalk aims to address these issues. Catwalk provides a unified interface to a broad range of existing NLP datasets and models, ranging from both canonical supervised training and fine-tuning, to more modern paradigms like in-context learning. Its carefully-designed abstractions allow for easy extensions to many others. Catwalk substantially lowers the barriers to conducting controlled experiments at scale. For example, we finetuned and evaluated over 64 models on over 86 datasets with a single command, without writing any code. Maintained by the AllenNLP team at the Allen Institute for Artificial Intelligence (AI2), Catwalk is an ongoing open-source effort: https://github.com/allenai/catwalk.