 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Confidence Estimation for LLMs in Multi-turn Interactions
Jan 05, 2026While confidence estimation is a promising direction for mitigating hallucinations in Large Language Models (LLMs), current research dominantly focuses on single-turn settings. The dynamics of model confidence in multi-turn conversations, where context accumulates and ambiguity is progressively resolved, remain largely unexplored. Reliable confidence estimation in multi-turn settings is critical for many downstream applications, such as autonomous agents and human-in-the-loop systems. This work presents the first systematic study of confidence estimation in multi-turn interactions, establishing a formal evaluation framework grounded in two key desiderata: per-turn calibration and monotonicity of confidence as more information becomes available. To facilitate this, we introduce novel metrics, including a length-normalized Expected Calibration Error (InfoECE), and a new "Hinter-Guesser" paradigm for generating controlled evaluation datasets. Our experiments reveal that widely-used confidence techniques struggle with calibration and monotonicity in multi-turn dialogues. We propose P(Sufficient), a logit-based probe that achieves comparatively better performance, although the task remains far from solved. Our work provides a foundational methodology for developing more reliable and trustworthy conversational agents.
EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos
Jul 16, 2025Real robot data collection for imitation learning has led to significant advancements in robotic manipulation. However, the requirement for robot hardware in the process fundamentally constrains the scale of the data. In this paper, we explore training Vision-Language-Action (VLA) models using egocentric human videos. The benefit of using human videos is not only for their scale but more importantly for the richness of scenes and tasks. With a VLA trained on human video that predicts human wrist and hand actions, we can perform Inverse Kinematics and retargeting to convert the human actions to robot actions. We fine-tune the model using a few robot manipulation demonstrations to obtain the robot policy, namely EgoVLA. We propose a simulation benchmark called Isaac Humanoid Manipulation Benchmark, where we design diverse bimanual manipulation tasks with demonstrations. We fine-tune and evaluate EgoVLA with Isaac Humanoid Manipulation Benchmark and show significant improvements over baselines and ablate the importance of human data. Videos can be found on our website: https://rchalyang.github.io/EgoVLA
AstroCompress: A benchmark dataset for multi-purpose compression of astronomical data
Jun 10, 2025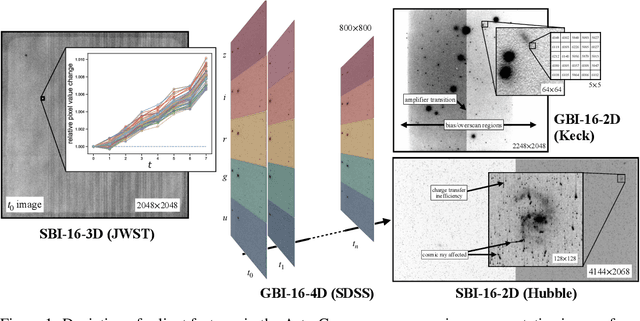
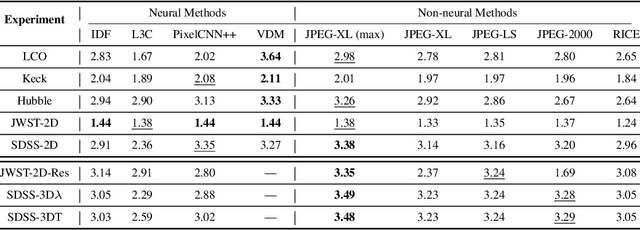
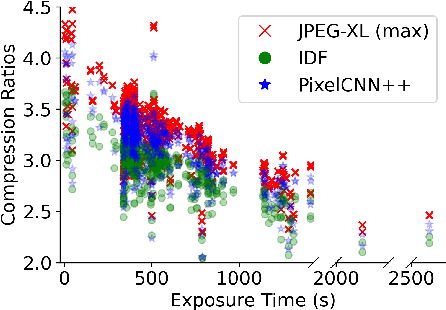
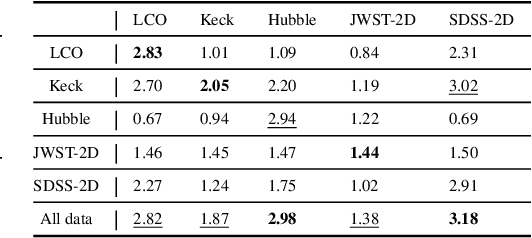
The site conditions that make astronomical observatories in space and on the ground so desirable -- cold and dark -- demand a physical remoteness that leads to limited data transmission capabilities. Such transmission limitations directly bottleneck the amount of data acquired and in an era of costly modern observatories, any improvements in lossless data compression has the potential scale to billions of dollars worth of additional science that can be accomplished on the same instrument. Traditional lossless methods for compressing astrophysical data are manually designed. Neural data compression, on the other hand, holds the promise of learning compression algorithms end-to-end from data and outperforming classical techniques by leveraging the unique spatial, temporal, and wavelength structures of astronomical images. This paper introduces AstroCompress: a neural compression challenge for astrophysics data, featuring four new datasets (and one legacy dataset) with 16-bit unsigned integer imaging data in various modes: space-based, ground-based, multi-wavelength, and time-series imaging. We provide code to easily access the data and benchmark seven lossless compression methods (three neural and four non-neural, including all practical state-of-the-art algorithms). Our results on lossless compression indicate that lossless neural compression techniques can enhance data collection at observatories, and provide guidance on the adoption of neural compression in scientific applications. Though the scope of this paper is restricted to lossless compression, we also comment on the potential exploration of lossy compression methods in future studies.
UNCLE: Uncertainty Expressions in Long-Form Generation
May 22, 2025Large Language Models (LLMs) are prone to hallucination, particularly in long-form generations. A promising direction to mitigate hallucination is to teach LLMs to express uncertainty explicitly when they lack sufficient knowledge. However, existing work lacks direct and fair evaluation of LLMs' ability to express uncertainty effectively in long-form generation. To address this gap, we first introduce UNCLE, a benchmark designed to evaluate uncertainty expression in both long- and short-form question answering (QA). UNCLE spans five domains and comprises 4k long-form QA instances and over 20k short-form QA pairs. Our dataset is the first to directly bridge short- and long-form QA with paired questions and gold-standard answers. Along with the benchmark, we propose a suite of new metrics to assess the models' capabilities to selectively express uncertainty. Using UNCLE, we then demonstrate that current models fail to convey uncertainty appropriately in long-form generation. We further explore both prompt-based and training-based methods to improve models' performance, with the training-based methods yielding greater gains. Further analysis of alignment gaps between short- and long-form uncertainty expression highlights promising directions for future research using UNCLE.
The Lighthouse of Language: Enhancing LLM Agents via Critique-Guided Improvement
Mar 20, 2025Large language models (LLMs) have recently transformed from text-based assistants to autonomous agents capable of planning, reasoning, and iteratively improving their actions. While numerical reward signals and verifiers can effectively rank candidate actions, they often provide limited contextual guidance. In contrast, natural language feedback better aligns with the generative capabilities of LLMs, providing richer and more actionable suggestions. However, parsing and implementing this feedback effectively can be challenging for LLM-based agents. In this work, we introduce Critique-Guided Improvement (CGI), a novel two-player framework, comprising an actor model that explores an environment and a critic model that generates detailed nature language feedback. By training the critic to produce fine-grained assessments and actionable revisions, and the actor to utilize these critiques, our approach promotes more robust exploration of alternative strategies while avoiding local optima. Experiments in three interactive environments show that CGI outperforms existing baselines by a substantial margin. Notably, even a small critic model surpasses GPT-4 in feedback quality. The resulting actor achieves state-of-the-art performance, demonstrating the power of explicit iterative guidance to enhance decision-making in LLM-based agents.
WildLMa: Long Horizon Loco-Manipulation in the Wild
Nov 22, 2024



`In-the-wild' mobile manipulation aims to deploy robots in diverse real-world environments, which requires the robot to (1) have skills that generalize across object configurations; (2) be capable of long-horizon task execution in diverse environments; and (3) perform complex manipulation beyond pick-and-place. Quadruped robots with manipulators hold promise for extending the workspace and enabling robust locomotion, but existing results do not investigate such a capability. This paper proposes WildLMa with three components to address these issues: (1) adaptation of learned low-level controller for VR-enabled whole-body teleoperation and traversability; (2) WildLMa-Skill -- a library of generalizable visuomotor skills acquired via imitation learning or heuristics and (3) WildLMa-Planner -- an interface of learned skills that allow LLM planners to coordinate skills for long-horizon tasks. We demonstrate the importance of high-quality training data by achieving higher grasping success rate over existing RL baselines using only tens of demonstrations. WildLMa exploits CLIP for language-conditioned imitation learning that empirically generalizes to objects unseen in training demonstrations. Besides extensive quantitative evaluation, we qualitatively demonstrate practical robot applications, such as cleaning up trash in university hallways or outdoor terrains, operating articulated objects, and rearranging items on a bookshelf.
LoGU: Long-form Generation with Uncertainty Expressions
Oct 18, 2024



While Large Language Models (LLMs) demonstrate impressive capabilities, they still struggle with generating factually incorrect content (i.e., hallucinations). A promising approach to mitigate this issue is enabling models to express uncertainty when unsure. Previous research on uncertainty modeling has primarily focused on short-form QA, but realworld applications often require much longer responses. In this work, we introduce the task of Long-form Generation with Uncertainty(LoGU). We identify two key challenges: Uncertainty Suppression, where models hesitate to express uncertainty, and Uncertainty Misalignment, where models convey uncertainty inaccurately. To tackle these challenges, we propose a refinement-based data collection framework and a two-stage training pipeline. Our framework adopts a divide-and-conquer strategy, refining uncertainty based on atomic claims. The collected data are then used in training through supervised fine-tuning (SFT) and direct preference optimization (DPO) to enhance uncertainty expression. Extensive experiments on three long-form instruction following datasets show that our method significantly improves accuracy, reduces hallucinations, and maintains the comprehensiveness of responses.
Atomic Calibration of LLMs in Long-Form Generations
Oct 17, 2024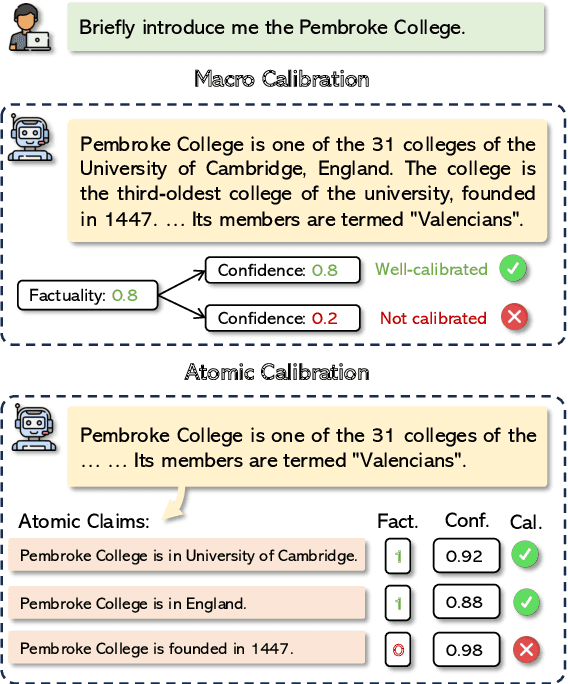



Large language models (LLMs) often suffer from hallucinations, posing significant challenges for real-world applications. Confidence calibration, which estimates the underlying uncertainty of model predictions, is essential to enhance the LLMs' trustworthiness. Existing research on LLM calibration has primarily focused on short-form tasks, providing a single confidence score at the response level (macro calibration). However, this approach is insufficient for long-form generations, where responses often contain more complex statements and may include both accurate and inaccurate information. Therefore, we introduce atomic calibration, a novel approach that evaluates factuality calibration at a fine-grained level by breaking down long responses into atomic claims. We classify confidence elicitation methods into discriminative and generative types and demonstrate that their combination can enhance calibration. Our extensive experiments on various LLMs and datasets show that atomic calibration is well-suited for long-form generation and can also improve macro calibration results. Additionally, atomic calibration reveals insightful patterns in LLM confidence throughout the generation process.
Visual Manipulation with Legs
Oct 15, 2024Animals use limbs for both locomotion and manipulation. We aim to equip quadruped robots with similar versatility. This work introduces a system that enables quadruped robots to interact with objects using their legs, inspired by non-prehensile manipulation. The system has two main components: a visual manipulation policy module and a loco-manipulator module. The visual manipulation policy, trained with reinforcement learning (RL) using point cloud observations and object-centric actions, decides how the leg should interact with the object. The loco-manipulator controller manages leg movements and body pose adjustments, based on impedance control and Model Predictive Control (MPC). Besides manipulating objects with a single leg, the system can select from the left or right leg based on critic maps and move objects to distant goals through base adjustment. Experiments evaluate the system on object pose alignment tasks in both simulation and the real world, demonstrating more versatile object manipulation skills with legs than previous work.