 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSWorld: Closed-Loop Photo-Realistic Simulation Suite for Robotic Manipulation
Oct 23, 2025This paper presents GSWorld, a robust, photo-realistic simulator for robotics manipulation that combines 3D Gaussian Splatting with physics engines. Our framework advocates "closing the loop" of developing manipulation policies with reproducible evaluation of policies learned from real-robot data and sim2real policy training without using real robots. To enable photo-realistic rendering of diverse scenes, we propose a new asset format, which we term GSDF (Gaussian Scene Description File), that infuses Gaussian-on-Mesh representation with robot URDF and other objects. With a streamlined reconstruction pipeline, we curate a database of GSDF that contains 3 robot embodiments for single-arm and bimanual manipulation, as well as more than 40 objects. Combining GSDF with physics engines, we demonstrate several immediate interesting applications: (1) learning zero-shot sim2real pixel-to-action manipulation policy with photo-realistic rendering, (2) automated high-quality DAgger data collection for adapting policies to deployment environments, (3) reproducible benchmarking of real-robot manipulation policies in simulation, (4) simulation data collection by virtual teleoperation, and (5) zero-shot sim2real visual reinforcement learning. Website: https://3dgsworld.github.io/.
GMT: General Motion Tracking for Humanoid Whole-Body Control
Jun 17, 2025The ability to track general whole-body motions in the real world is a useful way to build general-purpose humanoid robots. However, achieving this can be challenging due to the temporal and kinematic diversity of the motions, the policy's capability, and the difficulty of coordination of the upper and lower bodies. To address these issues, we propose GMT, a general and scalable motion-tracking framework that trains a single unified policy to enable humanoid robots to track diverse motions in the real world. GMT is built upon two core components: an Adaptive Sampling strategy and a Motion Mixture-of-Experts (MoE) architecture. The Adaptive Sampling automatically balances easy and difficult motions during training. The MoE ensures better specialization of different regions of the motion manifold. We show through extensive experiments in both simulation and the real world the effectiveness of GMT, achieving state-of-the-art performance across a broad spectrum of motions using a unified general policy. Videos and additional information can be found at https://gmt-humanoid.github.io.
Visual Acoustic Fields
Apr 01, 2025Objects produce different sounds when hit, and humans can intuitively infer how an object might sound based on its appearance and material properties. Inspired by this intuition, we propose Visual Acoustic Fields, a framework that bridges hitting sounds and visual signals within a 3D space using 3D Gaussian Splatting (3DGS). Our approach features two key modules: sound generation and sound localization. The sound generation module leverages a conditional diffusion model, which takes multiscale features rendered from a feature-augmented 3DGS to generate realistic hitting sounds. Meanwhile, the sound localization module enables querying the 3D scene, represented by the feature-augmented 3DGS, to localize hitting positions based on the sound sources. To support this framework, we introduce a novel pipeline for collecting scene-level visual-sound sample pairs, achieving alignment between captured images, impact locations, and corresponding sounds. To the best of our knowledge, this is the first dataset to connect visual and acoustic signals in a 3D context. Extensive experiments on our dataset demonstrate the effectiveness of Visual Acoustic Fields in generating plausible impact sounds and accurately localizing impact sources. Our project page is at https://yuelei0428.github.io/projects/Visual-Acoustic-Fields/.
Integrating LMM Planners and 3D Skill Policies for Generalizable Manipulation
Jan 30, 2025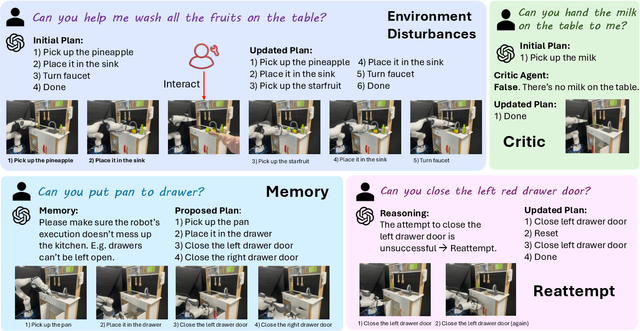
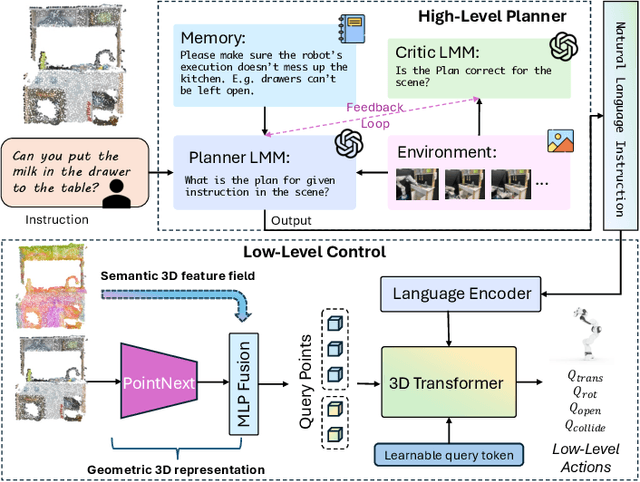

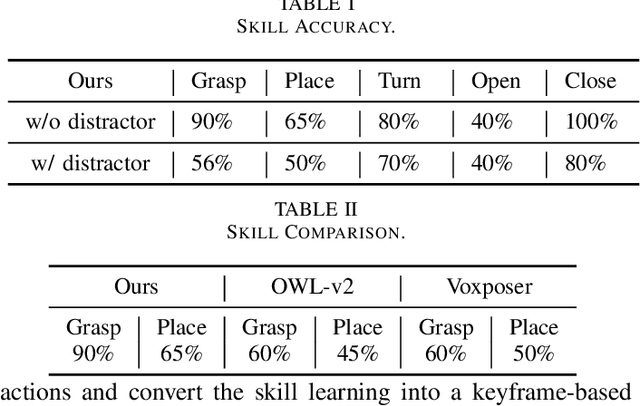
The recent advancements in visual reasoning capabilities of large multimodal models (LMMs) and the semantic enrichment of 3D feature fields have expanded the horizons of robotic capabilities. These developments hold significant potential for bridging the gap between high-level reasoning from LMMs and low-level control policies utilizing 3D feature fields. In this work, we introduce LMM-3DP, a framework that can integrate LMM planners and 3D skill Policies. Our approach consists of three key perspectives: high-level planning, low-level control, and effective integration. For high-level planning, LMM-3DP supports dynamic scene understanding for environment disturbances, a critic agent with self-feedback, history policy memorization, and reattempts after failures. For low-level control, LMM-3DP utilizes a semantic-aware 3D feature field for accurate manipulation. In aligning high-level and low-level control for robot actions, language embeddings representing the high-level policy are jointly attended with the 3D feature field in the 3D transformer for seamless integration. We extensively evaluate our approach across multiple skills and long-horizon tasks in a real-world kitchen environment. Our results show a significant 1.45x success rate increase in low-level control and an approximate 1.5x improvement in high-level planning accuracy compared to LLM-based baselines. Demo videos and an overview of LMM-3DP are available at https://lmm-3dp-release.github.io.
ExBody2: Advanced Expressive Humanoid Whole-Body Control
Dec 17, 2024This paper enables real-world humanoid robots to maintain stability while performing expressive motions like humans do. We propose ExBody2, a generalized whole-body tracking framework that can take any reference motion inputs and control the humanoid to mimic the motion. The model is trained in simulation with Reinforcement Learning and then transferred to the real world. It decouples keypoint tracking with velocity control, and effectively leverages a privileged teacher policy to distill precise mimic skills into the target student policy, which enables high-fidelity replication of dynamic movements such as running, crouching, dancing, and other challenging motions. We present a comprehensive qualitative and quantitative analysis of crucial design factors in the paper. We conduct our experiments on two humanoid platforms and demonstrate the superiority of our approach against state-of-the-arts, providing practical guidelines to pursue the extreme of whole-body control for humanoid robots.
Mobile-TeleVision: Predictive Motion Priors for Humanoid Whole-Body Control
Dec 10, 2024



Humanoid robots require both robust lower-body locomotion and precise upper-body manipulation. While recent Reinforcement Learning (RL) approaches provide whole-body loco-manipulation policies, they lack precise manipulation with high DoF arms. In this paper, we propose decoupling upper-body control from locomotion, using inverse kinematics (IK) and motion retargeting for precise manipulation, while RL focuses on robust lower-body locomotion. We introduce PMP (Predictive Motion Priors), trained with Conditional Variational Autoencoder (CVAE) to effectively represent upper-body motions. The locomotion policy is trained conditioned on this upper-body motion representation, ensuring that the system remains robust with both manipulation and locomotion. We show that CVAE features are crucial for stability and robustness, and significantly outperforms RL-based whole-body control in precise manipulation. With precise upper-body motion and robust lower-body locomotion control, operators can remotely control the humanoid to walk around and explore different environments, while performing diverse manipulation tasks.
WildLMa: Long Horizon Loco-Manipulation in the Wild
Nov 22, 2024



`In-the-wild' mobile manipulation aims to deploy robots in diverse real-world environments, which requires the robot to (1) have skills that generalize across object configurations; (2) be capable of long-horizon task execution in diverse environments; and (3) perform complex manipulation beyond pick-and-place. Quadruped robots with manipulators hold promise for extending the workspace and enabling robust locomotion, but existing results do not investigate such a capability. This paper proposes WildLMa with three components to address these issues: (1) adaptation of learned low-level controller for VR-enabled whole-body teleoperation and traversability; (2) WildLMa-Skill -- a library of generalizable visuomotor skills acquired via imitation learning or heuristics and (3) WildLMa-Planner -- an interface of learned skills that allow LLM planners to coordinate skills for long-horizon tasks. We demonstrate the importance of high-quality training data by achieving higher grasping success rate over existing RL baselines using only tens of demonstrations. WildLMa exploits CLIP for language-conditioned imitation learning that empirically generalizes to objects unseen in training demonstrations. Besides extensive quantitative evaluation, we qualitatively demonstrate practical robot applications, such as cleaning up trash in university hallways or outdoor terrains, operating articulated objects, and rearranging items on a bookshelf.
GraspSplats: Efficient Manipulation with 3D Feature Splatting
Sep 03, 2024



The ability for robots to perform efficient and zero-shot grasping of object parts is crucial for practical applications and is becoming prevalent with recent advances in Vision-Language Models (VLMs). To bridge the 2D-to-3D gap for representations to support such a capability, existing methods rely on neural fields (NeRFs) via differentiable rendering or point-based projection methods. However, we demonstrate that NeRFs are inappropriate for scene changes due to their implicitness and point-based methods are inaccurate for part localization without rendering-based optimization. To amend these issues, we propose GraspSplats. Using depth supervision and a novel reference feature computation method, GraspSplats generates high-quality scene representations in under 60 seconds. We further validate the advantages of Gaussian-based representation by showing that the explicit and optimized geometry in GraspSplats is sufficient to natively support (1) real-time grasp sampling and (2) dynamic and articulated object manipulation with point trackers. With extensive experiments on a Franka robot, we demonstrate that GraspSplats significantly outperforms existing methods under diverse task settings. In particular, GraspSplats outperforms NeRF-based methods like F3RM and LERF-TOGO, and 2D detection methods.
Ambient-Aware LiDAR Odometry in Variable Terrains
Sep 26, 2023The flexibility of Simultaneous Localization and Mapping (SLAM) algorithms in various environments has consistently been a significant challenge. To address the issue of LiDAR odometry drift in high-noise settings, integrating clustering methods to filter out unstable features has become an effective module of SLAM frameworks. However, reducing the amount of point cloud data can lead to potential loss of information and possible degeneration. As a result, this research proposes a LiDAR odometry that can dynamically assess the point cloud's reliability. The algorithm aims to improve adaptability in diverse settings by selecting important feature points with sensitivity to the level of environmental degeneration. Firstly, a fast adaptive Euclidean clustering algorithm based on range image is proposed, which, combined with depth clustering, extracts the primary structural points of the environment defined as ambient skeleton points. Then, the environmental degeneration level is computed through the dense normal features of the skeleton points, and the point cloud cleaning is dynamically adjusted accordingly. The algorithm is validated on the KITTI benchmark and real environments, demonstrating higher accuracy and robustness in different environments.