 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantitative Video World Model Evaluation for Geometric-Consistency
May 14, 2026Generative video models are increasingly studied as implicit world models, yet evaluating whether they produce physically plausible 3D structure and motion remains challenging. Most existing video evaluation pipelines rely heavily on human judgment or learned graders, which can be subjective and weakly diagnostic for geometric failures. We introduce PDI-Bench (Perspective Distortion Index), a quantitative framework for auditing geometric coherence in generated videos. Given a generated clip, we obtain object-centric observations via segmentation and point tracking (e.g., SAM 2, MegaSaM, and CoTracker3), lift them to 3D world-space coordinates via monocular reconstruction, and compute a set of projective-geometry residuals capturing three failure dimensions: scale-depth alignment, 3D motion consistency, and 3D structural rigidity. To support systematic evaluation, we build PDI-Dataset, covering diverse scenarios designed to stress these geometric constraints. Across state-of-the-art video generators, PDI reveals consistent geometry-specific failure modes that are not captured by common perceptual metrics, and provides a diagnostic signal for progress toward physically grounded video generation and physical world model. Our code and dataset can be found at https://pdi-bench.github.io/.
Long-Horizon Manipulation via Trace-Conditioned VLA Planning
Apr 23, 2026Long-horizon manipulation remains challenging for vision-language-action (VLA) policies: real tasks are multi-step, progress-dependent, and brittle to compounding execution errors. We present LoHo-Manip, a modular framework that scales short-horizon VLA execution to long-horizon instruction following via a dedicated task-management VLM. The manager is decoupled from the executor and is invoked in a receding-horizon manner: given the current observation, it predicts a progress-aware remaining plan that combines (i) a subtask sequence with an explicit done + remaining split as lightweight language memory, and (ii) a visual trace -- a compact 2D keypoint trajectory prompt specifying where to go and what to approach next. The executor VLA is adapted to condition on the rendered trace, thereby turning long-horizon decision-making into repeated local control by following the trace. Crucially, predicting the remaining plan at each step yields an implicit closed loop: failed steps persist in subsequent outputs, and traces update accordingly, enabling automatic continuation and replanning without hand-crafted recovery logic or brittle visual-history buffers. Extensive experiments spanning embodied planning, long-horizon reasoning, trajectory prediction, and end-to-end manipulation in simulation and on a real Franka robot demonstrate strong gains in long-horizon success, robustness, and out-of-distribution generalization. Project page: https://www.liuisabella.com/LoHoManip
Cross-Hand Latent Representation for Vision-Language-Action Models
Mar 10, 2026Dexterous manipulation is essential for real-world robot autonomy, mirroring the central role of human hand coordination in daily activity. Humans rely on rich multimodal perception--vision, sound, and language-guided intent--to perform dexterous actions, motivating vision-based, language-conditioned manipulation systems for robots. However, training reliable vision-language-action (VLA) models for dexterous manipulation requires large-scale demonstrations across many robotic hands. In addition, as new dexterous embodiments appear rapidly, collecting data for each becomes costly and impractical, creating a need for scalable cross-embodiment learning. We introduce XL-VLA, a vision-language-action framework integrated with a unified latent action space shared across diverse dexterous hands. This embodiment-invariant latent space is directly pluggable into standard VLA architectures, enabling seamless cross-embodiment training and efficient reuse of both existing and newly collected data. Experimental results demonstrate that XL-VLA consistently outperforms baseline VLA models operating in raw joint spaces, establishing it as an effective solution for scalable cross-embodiment dexterous manipulation.
From Power to Precision: Learning Fine-grained Dexterity for Multi-fingered Robotic Hands
Nov 17, 2025



Human grasps can be roughly categorized into two types: power grasps and precision grasps. Precision grasping enables tool use and is believed to have influenced human evolution. Today's multi-fingered robotic hands are effective in power grasps, but for tasks requiring precision, parallel grippers are still more widely adopted. This contrast highlights a key limitation in current robotic hand design: the difficulty of achieving both stable power grasps and precise, fine-grained manipulation within a single, versatile system. In this work, we bridge this gap by jointly optimizing the control and hardware design of a multi-fingered dexterous hand, enabling both power and precision manipulation. Rather than redesigning the entire hand, we introduce a lightweight fingertip geometry modification, represent it as a contact plane, and jointly optimize its parameters along with the corresponding control. Our control strategy dynamically switches between power and precision manipulation and simplifies precision control into parallel thumb-index motions, which proves robust for sim-to-real transfer. On the design side, we leverage large-scale simulation to optimize the fingertip geometry using a differentiable neural-physics surrogate model. We validate our approach through extensive experiments in both sim-to-real and real-to-real settings. Our method achieves an 82.5% zero-shot success rate on unseen objects in sim-to-real precision grasping, and a 93.3% success rate in challenging real-world tasks involving bread pinching. These results demonstrate that our co-design framework can significantly enhance the fine-grained manipulation ability of multi-fingered hands without reducing their ability for power grasps. Our project page is at https://jianglongye.com/power-to-precision
GSWorld: Closed-Loop Photo-Realistic Simulation Suite for Robotic Manipulation
Oct 23, 2025This paper presents GSWorld, a robust, photo-realistic simulator for robotics manipulation that combines 3D Gaussian Splatting with physics engines. Our framework advocates "closing the loop" of developing manipulation policies with reproducible evaluation of policies learned from real-robot data and sim2real policy training without using real robots. To enable photo-realistic rendering of diverse scenes, we propose a new asset format, which we term GSDF (Gaussian Scene Description File), that infuses Gaussian-on-Mesh representation with robot URDF and other objects. With a streamlined reconstruction pipeline, we curate a database of GSDF that contains 3 robot embodiments for single-arm and bimanual manipulation, as well as more than 40 objects. Combining GSDF with physics engines, we demonstrate several immediate interesting applications: (1) learning zero-shot sim2real pixel-to-action manipulation policy with photo-realistic rendering, (2) automated high-quality DAgger data collection for adapting policies to deployment environments, (3) reproducible benchmarking of real-robot manipulation policies in simulation, (4) simulation data collection by virtual teleoperation, and (5) zero-shot sim2real visual reinforcement learning. Website: https://3dgsworld.github.io/.
Real Deep Research for AI, Robotics and Beyond
Oct 23, 2025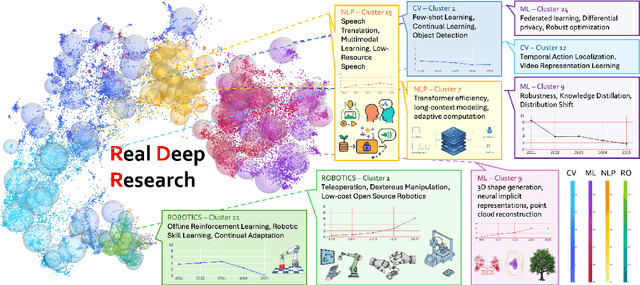
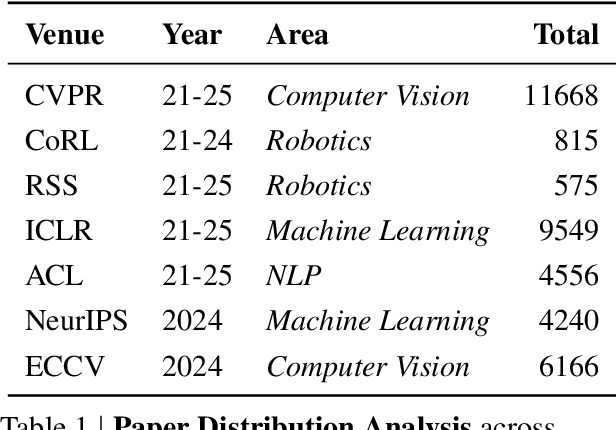
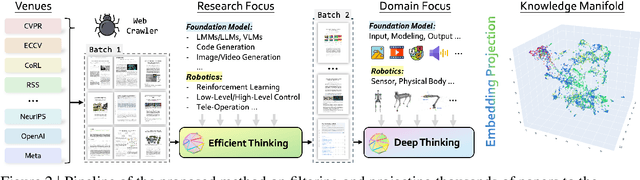
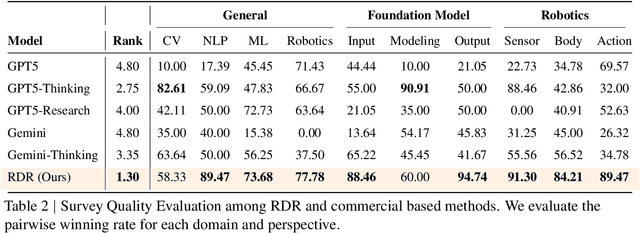
With the rapid growth of research in AI and robotics now producing over 10,000 papers annually it has become increasingly difficult for researchers to stay up to date. Fast evolving trends, the rise of interdisciplinary work, and the need to explore domains beyond one's expertise all contribute to this challenge. To address these issues, we propose a generalizable pipeline capable of systematically analyzing any research area: identifying emerging trends, uncovering cross domain opportunities, and offering concrete starting points for new inquiry. In this work, we present Real Deep Research (RDR) a comprehensive framework applied to the domains of AI and robotics, with a particular focus on foundation models and robotics advancements. We also briefly extend our analysis to other areas of science. The main paper details the construction of the RDR pipeline, while the appendix provides extensive results across each analyzed topic. We hope this work sheds light for researchers working in the field of AI and beyond.
EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos
Jul 16, 2025Real robot data collection for imitation learning has led to significant advancements in robotic manipulation. However, the requirement for robot hardware in the process fundamentally constrains the scale of the data. In this paper, we explore training Vision-Language-Action (VLA) models using egocentric human videos. The benefit of using human videos is not only for their scale but more importantly for the richness of scenes and tasks. With a VLA trained on human video that predicts human wrist and hand actions, we can perform Inverse Kinematics and retargeting to convert the human actions to robot actions. We fine-tune the model using a few robot manipulation demonstrations to obtain the robot policy, namely EgoVLA. We propose a simulation benchmark called Isaac Humanoid Manipulation Benchmark, where we design diverse bimanual manipulation tasks with demonstrations. We fine-tune and evaluate EgoVLA with Isaac Humanoid Manipulation Benchmark and show significant improvements over baselines and ablate the importance of human data. Videos can be found on our website: https://rchalyang.github.io/EgoVLA
Visual Acoustic Fields
Apr 01, 2025Objects produce different sounds when hit, and humans can intuitively infer how an object might sound based on its appearance and material properties. Inspired by this intuition, we propose Visual Acoustic Fields, a framework that bridges hitting sounds and visual signals within a 3D space using 3D Gaussian Splatting (3DGS). Our approach features two key modules: sound generation and sound localization. The sound generation module leverages a conditional diffusion model, which takes multiscale features rendered from a feature-augmented 3DGS to generate realistic hitting sounds. Meanwhile, the sound localization module enables querying the 3D scene, represented by the feature-augmented 3DGS, to localize hitting positions based on the sound sources. To support this framework, we introduce a novel pipeline for collecting scene-level visual-sound sample pairs, achieving alignment between captured images, impact locations, and corresponding sounds. To the best of our knowledge, this is the first dataset to connect visual and acoustic signals in a 3D context. Extensive experiments on our dataset demonstrate the effectiveness of Visual Acoustic Fields in generating plausible impact sounds and accurately localizing impact sources. Our project page is at https://yuelei0428.github.io/projects/Visual-Acoustic-Fields/.
M3: 3D-Spatial MultiModal Memory
Mar 20, 2025We present 3D Spatial MultiModal Memory (M3), a multimodal memory system designed to retain information about medium-sized static scenes through video sources for visual perception. By integrating 3D Gaussian Splatting techniques with foundation models, M3 builds a multimodal memory capable of rendering feature representations across granularities, encompassing a wide range of knowledge. In our exploration, we identify two key challenges in previous works on feature splatting: (1) computational constraints in storing high-dimensional features for each Gaussian primitive, and (2) misalignment or information loss between distilled features and foundation model features. To address these challenges, we propose M3 with key components of principal scene components and Gaussian memory attention, enabling efficient training and inference. To validate M3, we conduct comprehensive quantitative evaluations of feature similarity and downstream tasks, as well as qualitative visualizations to highlight the pixel trace of Gaussian memory attention. Our approach encompasses a diverse range of foundation models, including vision-language models (VLMs), perception models, and large multimodal and language models (LMMs/LLMs). Furthermore, to demonstrate real-world applicability, we deploy M3's feature field in indoor scenes on a quadruped robot. Notably, we claim that M3 is the first work to address the core compression challenges in 3D feature distillation.
LoRA-TTT: Low-Rank Test-Time Training for Vision-Language Models
Feb 04, 2025The rapid advancements in vision-language models (VLMs), such as CLIP, have intensified the need to address distribution shifts between training and testing datasets. Although prior Test-Time Training (TTT) techniques for VLMs have demonstrated robust performance, they predominantly rely on tuning text prompts, a process that demands substantial computational resources and is heavily dependent on entropy-based loss. In this paper, we propose LoRA-TTT, a novel TTT method that leverages Low-Rank Adaptation (LoRA), applied exclusively to the image encoder of VLMs. By introducing LoRA and updating only its parameters during test time, our method offers a simple yet effective TTT approach, retaining the model's initial generalization capability while achieving substantial performance gains with minimal memory and runtime overhead. Additionally, we introduce a highly efficient reconstruction loss tailored for TTT. Our method can adapt to diverse domains by combining these two losses, without increasing memory consumption or runtime. Extensive experiments on two benchmarks, covering 15 datasets, demonstrate that our method improves the zero-shot top-1 accuracy of CLIP-ViT-B/16 by an average of 5.79% on the OOD benchmark and 1.36% on the fine-grained benchmark, efficiently surpassing test-time prompt tuning, without relying on any external models or cache.