 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet the Abyss Stare Back Adaptive Falsification for Autonomous Scientific Discovery
Mar 30, 2026Autonomous scientific discovery is entering a more dangerous regime: once the evaluator is frozen, a sufficiently strong search process can learn to win the exam without learning the mechanism the task was meant to reveal. This is the idea behind our title. To let the abyss stare back is to make evaluation actively push against the candidate through adaptive falsification, rather than passively certify it through static validation. We introduce DASES, a falsification-driven framework in which an Innovator, an Abyss Falsifier, and a Mechanistic Causal Extractor co-evolve executable scientific artifacts and scientifically admissible counterexample environments under a fixed scientific contract. In a controlled loss-discovery problem with a single editable locus, DASES rejects artifacts that static validation would have accepted, identifies the first candidate that survives the admissible falsification frontier, and discovers FNG-CE, a loss that transfers beyond the synthetic discovery environment and consistently outperforms CE and CE+L2 under controlled comparisons across standard benchmarks, including ImageNet.
Agentic Automation of BT-RADS Scoring: End-to-End Multi-Agent System for Standardized Brain Tumor Follow-up Assessment
Mar 23, 2026The Brain Tumor Reporting and Data System (BT-RADS) standardizes post-treatment MRI response assessment in patients with diffuse gliomas but requires complex integration of imaging trends, medication effects, and radiation timing. This study evaluates an end-to-end multi-agent large language model (LLM) and convolutional neural network (CNN) system for automated BT-RADS classification. A multi-agent LLM system combined with automated CNN-based tumor segmentation was retrospectively evaluated on 509 consecutive post-treatment glioma MRI examinations from a single high-volume center. An extractor agent identified clinical variables (steroid status, bevacizumab status, radiation date) from unstructured clinical notes, while a scorer agent applied BT-RADS decision logic integrating extracted variables with volumetric measurements. Expert reference standard classifications were established by an independent board-certified neuroradiologist. Of 509 examinations, 492 met inclusion criteria. The system achieved 374/492 (76.0%; 95% CI, 72.1%-79.6%) accuracy versus 283/492 (57.5%; 95% CI, 53.1%-61.8%) for initial clinical assessments (+18.5 percentage points; P<.001). Context-dependent categories showed high sensitivity (BT-1b 100%, BT-1a 92.7%, BT-3a 87.5%), while threshold-dependent categories showed moderate sensitivity (BT-3c 74.8%, BT-2 69.2%, BT-4 69.3%, BT-3b 57.1%). For BT-4, positive predictive value was 92.9%. The multi-agent LLM system achieved higher BT-RADS classification agreement with expert reference standard compared to initial clinical scoring, with high accuracy for context-dependent scores and high positive predictive value for BT-4 detection.
Good SFT Optimizes for SFT, Better SFT Prepares for Reinforcement Learning
Feb 01, 2026Post-training of reasoning LLMs is a holistic process that typically consists of an offline SFT stage followed by an online reinforcement learning (RL) stage. However, SFT is often optimized in isolation to maximize SFT performance alone. We show that, after identical RL training, models initialized from stronger SFT checkpoints can significantly underperform those initialized from weaker ones. We attribute this to a mismatch typical in current SFT-RL pipelines: the distribution that generates the offline SFT data can differ substantially from the policy optimized during online RL, which learns from its own rollouts. We propose PEAR (Policy Evaluation-inspired Algorithm for Offline Learning Loss Re-weighting), an SFT-stage method that corrects this mismatch and better prepares the model for RL. PEAR uses importance sampling to reweight the SFT loss, with three variants operating at the token, block, and sequence levels. It can be used to augment standard SFT objectives and incurs little additional training overhead once probabilities for the offline data are collected. We conduct controlled experiments on verifiable reasoning games and mathematical reasoning tasks on Qwen 2.5 and 3 and DeepSeek-distilled models. PEAR consistently improves post-RL performance over canonical SFT, with pass at 8 gains up to a 14.6 percent on AIME2025. Our results suggest that PEAR is an effective step toward more holistic LLM post-training by designing and evaluating SFT with downstream RL in mind rather than in isolation.
Adaptation of Agentic AI
Dec 22, 2025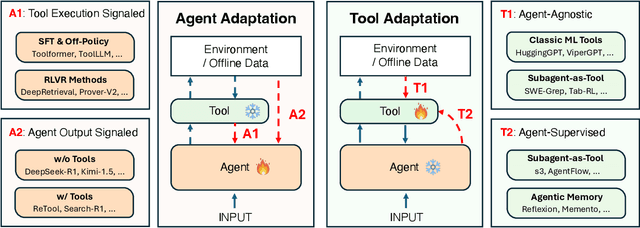
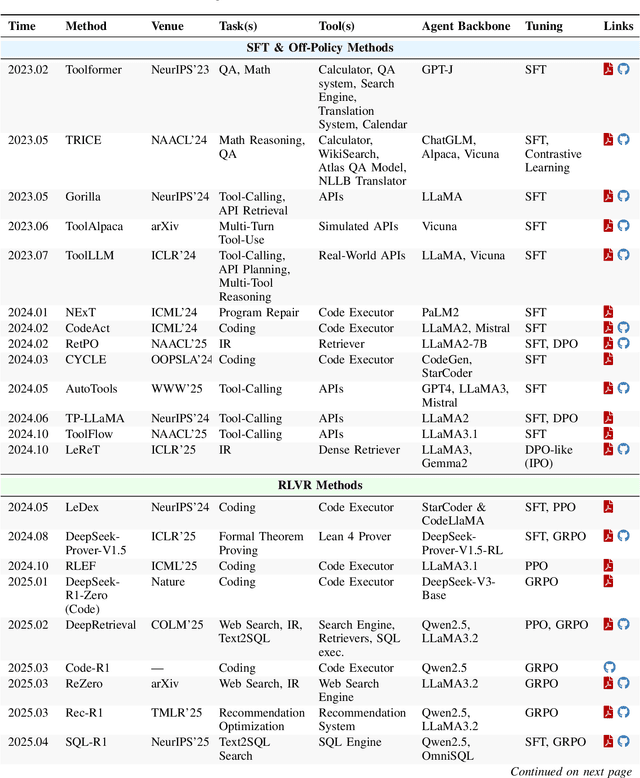
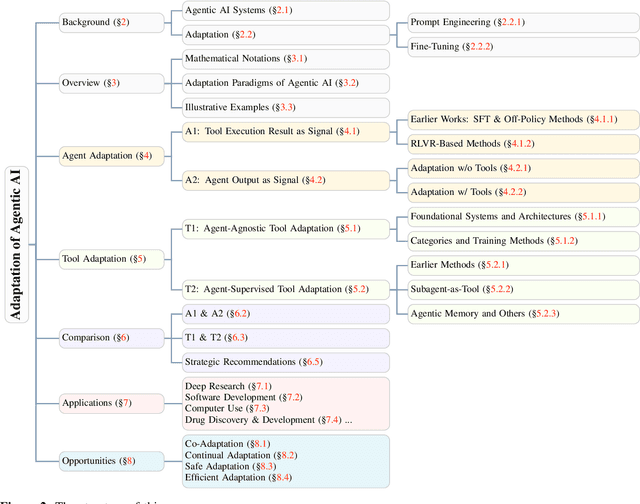
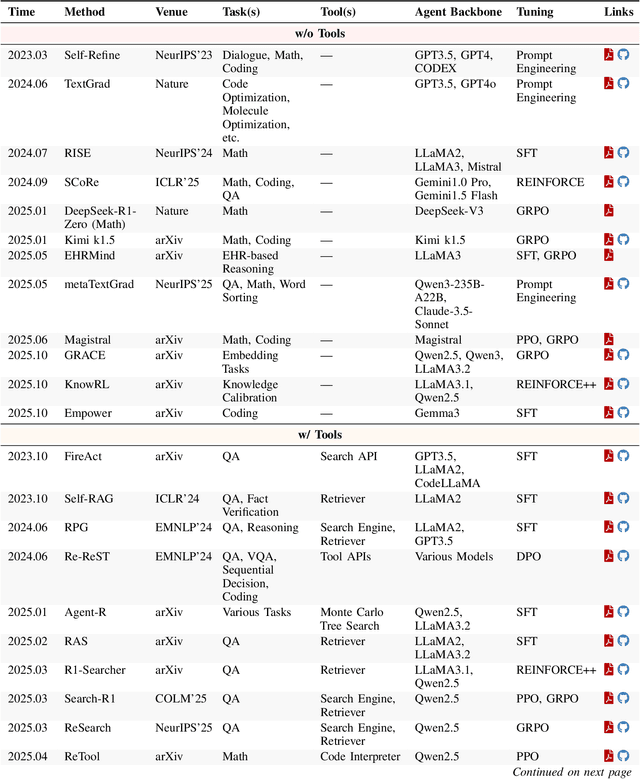
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
Building A Proof-Oriented Programmer That Is 64% Better Than GPT-4o Under Data Scarsity
Feb 17, 2025Existing LMs struggle with proof-oriented programming due to data scarcity, which manifest in two key ways: (1) a lack of sufficient corpora for proof-oriented programming languages such as F*, and (2) the absence of large-scale, project-level proof-oriented implementations that can teach the model the intricate reasoning process when performing proof-oriented programming. We present the first on synthetic data augmentation for project level proof oriented programming for both generation and repair. Our method addresses data scarcity by synthesizing basic proof-oriented programming problems for proficiency in that language; incorporating diverse coding data for reasoning capability elicitation and creating new proofs and repair data within existing repositories. This approach enables language models to both synthesize and repair proofs for function- and repository-level code. We show that our fine-tuned 14B parameter model, PoPilot, can exceed the performance of the models that outperforms GPT-4o in project-level proof-oriented programming by 64% relative margin, and can improve GPT-4o's performance by 54% by repairing its outputs over GPT-4o's self-repair.
The Best Instruction-Tuning Data are Those That Fit
Feb 07, 2025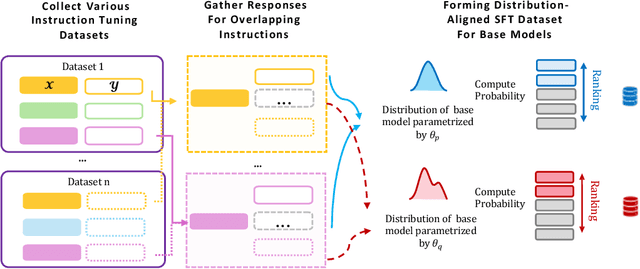
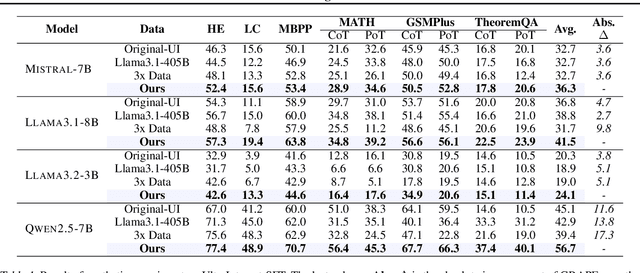
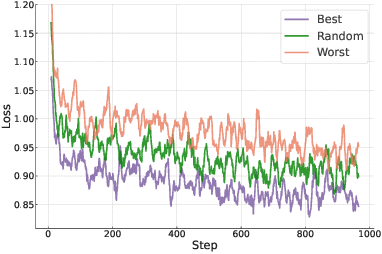
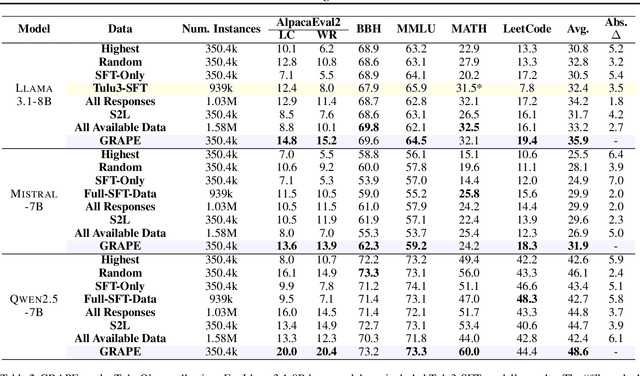
High-quality supervised fine-tuning (SFT) data are crucial for eliciting strong capabilities from pretrained large language models (LLMs). Typically, instructions are paired with multiple responses sampled from other LLMs, which are often out of the distribution of the target model to be fine-tuned. This, at scale, can lead to diminishing returns and even hurt the models' performance and robustness. We propose **GRAPE**, a novel SFT framework that accounts for the unique characteristics of the target model. For each instruction, it gathers responses from various LLMs and selects the one with the highest probability measured by the target model, indicating that it aligns most closely with the target model's pretrained distribution; it then proceeds with standard SFT training. We first evaluate GRAPE with a controlled experiment, where we sample various solutions for each question in UltraInteract from multiple models and fine-tune commonly used LMs like LLaMA3.1-8B, Mistral-7B, and Qwen2.5-7B on GRAPE-selected data. GRAPE significantly outperforms strong baselines, including distilling from the strongest model with an absolute gain of up to 13.8%, averaged across benchmarks, and training on 3x more data with a maximum performance improvement of 17.3%. GRAPE's strong performance generalizes to realistic settings. We experiment with the post-training data used for Tulu3 and Olmo-2. GRAPE outperforms strong baselines trained on 4.5 times more data by 6.1% and a state-of-the-art data selection approach by 3% on average performance. Remarkably, using 1/3 of the data and half the number of epochs, GRAPE enables LLaMA3.1-8B to surpass the performance of Tulu3-SFT by 3.5%.
Improving Influence-based Instruction Tuning Data Selection for Balanced Learning of Diverse Capabilities
Jan 21, 2025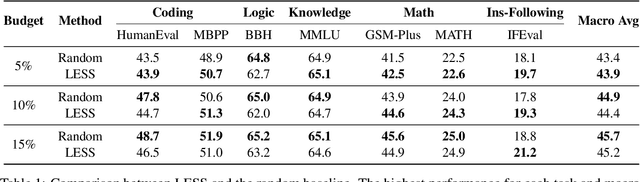
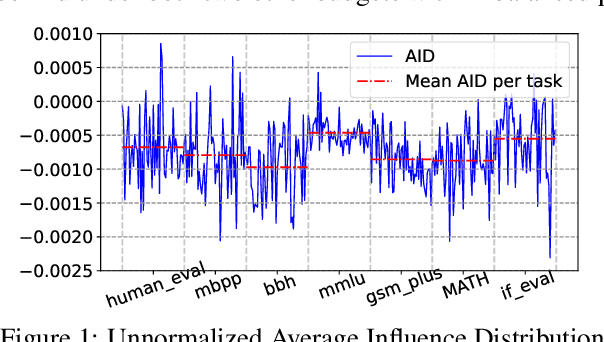
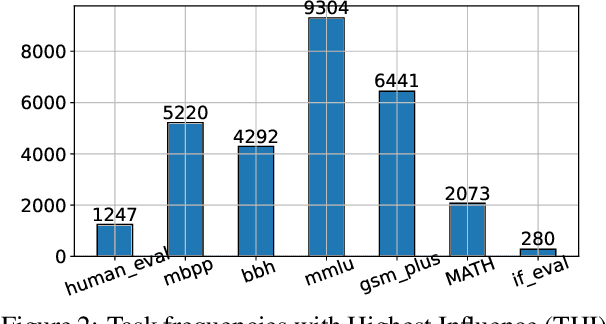
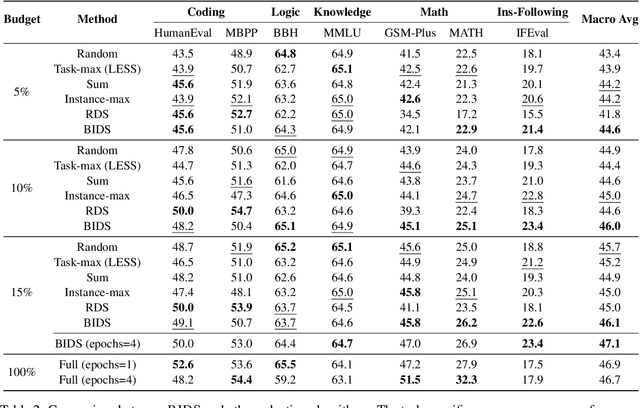
Selecting appropriate training data is crucial for effective instruction fine-tuning of large language models (LLMs), which aims to (1) elicit strong capabilities, and (2) achieve balanced performance across a diverse range of tasks. Influence-based methods show promise in achieving (1) by estimating the contribution of each training example to the model's predictions, but often struggle with (2). Our systematic investigation reveals that this underperformance can be attributed to an inherent bias where certain tasks intrinsically have greater influence than others. As a result, data selection is often biased towards these tasks, not only hurting the model's performance on others but also, counterintuitively, harms performance on these high-influence tasks themselves. As a remedy, we propose BIDS, a Balanced and Influential Data Selection algorithm. BIDS first normalizes influence scores of the training data, and then iteratively balances data selection by choosing the training example with the highest influence on the most underrepresented task. Experiments with both Llama-3 and Mistral-v0.3 on seven benchmarks spanning five diverse capabilities show that BIDS consistently outperforms both state-of-the-art influence-based algorithms and other non-influence-based selection frameworks. Surprisingly, training on a 15% subset selected by BIDS can even outperform full-dataset training with a much more balanced performance. Our analysis further highlights the importance of both instance-level normalization and iterative optimization of selected data for balanced learning of diverse capabilities.
Entropy-Regularized Process Reward Model
Dec 15, 2024



Large language models (LLMs) have shown promise in performing complex multi-step reasoning, yet they continue to struggle with mathematical reasoning, often making systematic errors. A promising solution is reinforcement learning (RL) guided by reward models, particularly those focusing on process rewards, which score each intermediate step rather than solely evaluating the final outcome. This approach is more effective at guiding policy models towards correct reasoning trajectories. In this work, we propose an entropy-regularized process reward model (ER-PRM) that integrates KL-regularized Markov Decision Processes (MDP) to balance policy optimization with the need to prevent the policy from shifting too far from its initial distribution. We derive a novel reward construction method based on the theoretical results. Our theoretical analysis shows that we could derive the optimal reward model from the initial policy sampling. Our empirical experiments on the MATH and GSM8K benchmarks demonstrate that ER-PRM consistently outperforms existing process reward models, achieving 1% improvement on GSM8K and 2-3% improvement on MATH under best-of-N evaluation, and more than 1% improvement under RLHF. These results highlight the efficacy of entropy-regularization in enhancing LLMs' reasoning capabilities.
$\textbf{Only-IF}$:Revealing the Decisive Effect of Instruction Diversity on Generalization
Oct 07, 2024Understanding and accurately following instructions is critical for large language models (LLMs) to be effective across diverse tasks. In this work, we rigorously examine the key factors that enable models to generalize to unseen instructions, providing insights to guide the collection of data for instruction-tuning. Through controlled experiments, inspired by the Turing-complete Markov algorithm, we demonstrate that such generalization $\textbf{only emerges}$ when training data is diversified enough across semantic domains. Our findings also reveal that merely diversifying within limited domains fails to ensure robust generalization. In contrast, cross-domain data diversification, even under constrained data budgets, significantly enhances a model's adaptability. We further extend our analysis to real-world scenarios, including fine-tuning of $\textit{$\textbf{specialist}$}$ and $\textit{$\textbf{generalist}$}$ models. In both cases, we demonstrate that 1) better performance can be achieved by increasing the diversity of an established dataset while keeping the data size constant, and 2) when scaling up the data, diversifying the semantics of instructions is more effective than simply increasing the quantity of similar data. Our research provides important insights for dataset collation, particularly when optimizing model performance by expanding training data for both specialist and generalist scenarios. We show that careful consideration of data diversification is key: training specialist models with data extending beyond their core domain leads to significant performance improvements, while generalist models benefit from diverse data mixtures that enhance their overall instruction-following capabilities across a wide range of applications. Our results highlight the critical role of strategic diversification and offer clear guidelines for improving data quality.
Visual Prompting in LLMs for Enhancing Emotion Recognition
Oct 03, 2024Vision Large Language Models (VLLMs) are transforming the intersection of computer vision and natural language processing. Nonetheless, the potential of using visual prompts for emotion recognition in these models remains largely unexplored and untapped. Traditional methods in VLLMs struggle with spatial localization and often discard valuable global context. To address this problem, we propose a Set-of-Vision prompting (SoV) approach that enhances zero-shot emotion recognition by using spatial information, such as bounding boxes and facial landmarks, to mark targets precisely. SoV improves accuracy in face count and emotion categorization while preserving the enriched image context. Through a battery of experimentation and analysis of recent commercial or open-source VLLMs, we evaluate the SoV model's ability to comprehend facial expressions in natural environments. Our findings demonstrate the effectiveness of integrating spatial visual prompts into VLLMs for improving emotion recognition performance.