 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLCD: A Deep Transfer Learning Framework for Cross-Disciplinary Cognitive Diagnosis
Oct 27, 2025Driven by the dual principles of smart education and artificial intelligence technology, the online education model has rapidly emerged as an important component of the education industry. Cognitive diagnostic technology can utilize students' learning data and feedback information in educational evaluation to accurately assess their ability level at the knowledge level. However, while massive amounts of information provide abundant data resources, they also bring about complexity in feature extraction and scarcity of disciplinary data. In cross-disciplinary fields, traditional cognitive diagnostic methods still face many challenges. Given the differences in knowledge systems, cognitive structures, and data characteristics between different disciplines, this paper conducts in-depth research on neural network cognitive diagnosis and knowledge association neural network cognitive diagnosis, and proposes an innovative cross-disciplinary cognitive diagnosis method (TLCD). This method combines deep learning techniques and transfer learning strategies to enhance the performance of the model in the target discipline by utilizing the common features of the main discipline. The experimental results show that the cross-disciplinary cognitive diagnosis model based on deep learning performs better than the basic model in cross-disciplinary cognitive diagnosis tasks, and can more accurately evaluate students' learning situation.
A Closed-Loop Personalized Learning Agent Integrating Neural Cognitive Diagnosis, Bounded-Ability Adaptive Testing, and LLM-Driven Feedback
Oct 26, 2025

As information technology advances, education is moving from one-size-fits-all instruction toward personalized learning. However, most methods handle modeling, item selection, and feedback in isolation rather than as a closed loop. This leads to coarse or opaque student models, assumption-bound adaptivity that ignores diagnostic posteriors, and generic, non-actionable feedback. To address these limitations, this paper presents an end-to-end personalized learning agent, EduLoop-Agent, which integrates a Neural Cognitive Diagnosis model (NCD), a Bounded-Ability Estimation Computerized Adaptive Testing strategy (BECAT), and large language models (LLMs). The NCD module provides fine-grained estimates of students' mastery at the knowledge-point level; BECAT dynamically selects subsequent items to maximize relevance and learning efficiency; and LLMs convert diagnostic signals into structured, actionable feedback. Together, these components form a closed-loop framework of ``Diagnosis--Recommendation--Feedback.'' Experiments on the ASSISTments dataset show that the NCD module achieves strong performance on response prediction while yielding interpretable mastery assessments. The adaptive recommendation strategy improves item relevance and personalization, and the LLM-based feedback offers targeted study guidance aligned with identified weaknesses. Overall, the results indicate that the proposed design is effective and practically deployable, providing a feasible pathway to generating individualized learning trajectories in intelligent education.
Angio-Diff: Learning a Self-Supervised Adversarial Diffusion Model for Angiographic Geometry Generation
Jun 24, 2025Vascular diseases pose a significant threat to human health, with X-ray angiography established as the gold standard for diagnosis, allowing for detailed observation of blood vessels. However, angiographic X-rays expose personnel and patients to higher radiation levels than non-angiographic X-rays, which are unwanted. Thus, modality translation from non-angiographic to angiographic X-rays is desirable. Data-driven deep approaches are hindered by the lack of paired large-scale X-ray angiography datasets. While making high-quality vascular angiography synthesis crucial, it remains challenging. We find that current medical image synthesis primarily operates at pixel level and struggles to adapt to the complex geometric structure of blood vessels, resulting in unsatisfactory quality of blood vessel image synthesis, such as disconnections or unnatural curvatures. To overcome this issue, we propose a self-supervised method via diffusion models to transform non-angiographic X-rays into angiographic X-rays, mitigating data shortages for data-driven approaches. Our model comprises a diffusion model that learns the distribution of vascular data from diffusion latent, a generator for vessel synthesis, and a mask-based adversarial module. To enhance geometric accuracy, we propose a parametric vascular model to fit the shape and distribution of blood vessels. The proposed method contributes a pipeline and a synthetic dataset for X-ray angiography. We conducted extensive comparative and ablation experiments to evaluate the Angio-Diff. The results demonstrate that our method achieves state-of-the-art performance in synthetic angiography image quality and more accurately synthesizes the geometric structure of blood vessels. The code is available at https://github.com/zfw-cv/AngioDiff.
Visual and textual prompts for enhancing emotion recognition in video
Apr 24, 2025Vision Large Language Models (VLLMs) exhibit promising potential for multi-modal understanding, yet their application to video-based emotion recognition remains limited by insufficient spatial and contextual awareness. Traditional approaches, which prioritize isolated facial features, often neglect critical non-verbal cues such as body language, environmental context, and social interactions, leading to reduced robustness in real-world scenarios. To address this gap, we propose Set-of-Vision-Text Prompting (SoVTP), a novel framework that enhances zero-shot emotion recognition by integrating spatial annotations (e.g., bounding boxes, facial landmarks), physiological signals (facial action units), and contextual cues (body posture, scene dynamics, others' emotions) into a unified prompting strategy. SoVTP preserves holistic scene information while enabling fine-grained analysis of facial muscle movements and interpersonal dynamics. Extensive experiments show that SoVTP achieves substantial improvements over existing visual prompting methods, demonstrating its effectiveness in enhancing VLLMs' video emotion recognition capabilities.
Domain-Specific Pruning of Large Mixture-of-Experts Models with Few-shot Demonstrations
Apr 09, 2025



Mixture-of-Experts (MoE) models achieve a favorable trade-off between performance and inference efficiency by activating only a subset of experts. However, the memory overhead of storing all experts remains a major limitation, especially in large-scale MoE models such as DeepSeek-R1 (671B). In this study, we investigate domain specialization and expert redundancy in large-scale MoE models and uncover a consistent behavior we term few-shot expert localization, with only a few demonstrations, the model consistently activates a sparse and stable subset of experts. Building on this observation, we propose a simple yet effective pruning framework, EASY-EP, that leverages a few domain-specific demonstrations to identify and retain only the most relevant experts. EASY-EP comprises two key components: output-aware expert importance assessment and expert-level token contribution estimation. The former evaluates the importance of each expert for the current token by considering the gating scores and magnitudes of the outputs of activated experts, while the latter assesses the contribution of tokens based on representation similarities after and before routed experts. Experiments show that our method can achieve comparable performances and $2.99\times$ throughput under the same memory budget with full DeepSeek-R1 with only half the experts. Our code is available at https://github.com/RUCAIBox/EASYEP.
VasTSD: Learning 3D Vascular Tree-state Space Diffusion Model for Angiography Synthesis
Mar 17, 2025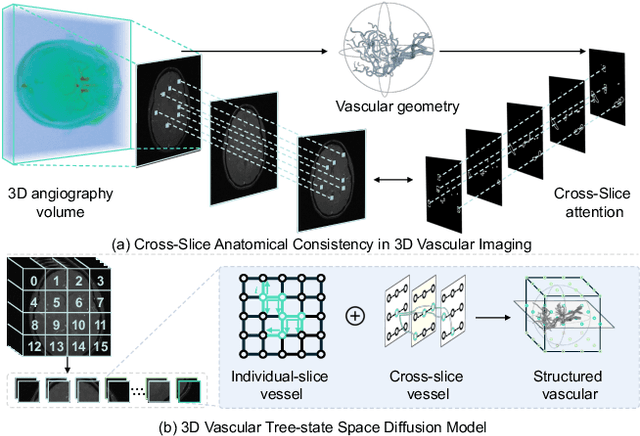



Angiography imaging is a medical imaging technique that enhances the visibility of blood vessels within the body by using contrast agents. Angiographic images can effectively assist in the diagnosis of vascular diseases. However, contrast agents may bring extra radiation exposure which is harmful to patients with health risks. To mitigate these concerns, in this paper, we aim to automatically generate angiography from non-angiographic inputs, by leveraging and enhancing the inherent physical properties of vascular structures. Previous methods relying on 2D slice-based angiography synthesis struggle with maintaining continuity in 3D vascular structures and exhibit limited effectiveness across different imaging modalities. We propose VasTSD, a 3D vascular tree-state space diffusion model to synthesize angiography from 3D non-angiographic volumes, with a novel state space serialization approach that dynamically constructs vascular tree topologies, integrating these with a diffusion-based generative model to ensure the generation of anatomically continuous vasculature in 3D volumes. A pre-trained vision embedder is employed to construct vascular state space representations, enabling consistent modeling of vascular structures across multiple modalities. Extensive experiments on various angiographic datasets demonstrate the superiority of VasTSD over prior works, achieving enhanced continuity of blood vessels in synthesized angiographic synthesis for multiple modalities and anatomical regions.
Mobile Recording Device Recognition Based Cross-Scale and Multi-Level Representation Learning
Nov 06, 2024



This paper introduces a modeling approach that employs multi-level global processing, encompassing both short-term frame-level and long-term sample-level feature scales. In the initial stage of shallow feature extraction, various scales are employed to extract multi-level features, including Mel-Frequency Cepstral Coefficients (MFCC) and pre-Fbank log energy spectrum. The construction of the identification network model involves considering the input two-dimensional temporal features from both frame and sample levels. Specifically, the model initially employs one-dimensional convolution-based Convolutional Long Short-Term Memory (ConvLSTM) to fuse spatiotemporal information and extract short-term frame-level features. Subsequently, bidirectional long Short-Term Memory (BiLSTM) is utilized to learn long-term sample-level sequential representations. The transformer encoder then performs cross-scale, multi-level processing on global frame-level and sample-level features, facilitating deep feature representation and fusion at both levels. Finally, recognition results are obtained through Softmax. Our method achieves an impressive 99.6% recognition accuracy on the CCNU_Mobile dataset, exhibiting a notable improvement of 2% to 12% compared to the baseline system. Additionally, we thoroughly investigate the transferability of our model, achieving an 87.9% accuracy in a classification task on a new dataset.
CAD-NeRF: Learning NeRFs from Uncalibrated Few-view Images by CAD Model Retrieval
Nov 05, 2024Reconstructing from multi-view images is a longstanding problem in 3D vision, where neural radiance fields (NeRFs) have shown great potential and get realistic rendered images of novel views. Currently, most NeRF methods either require accurate camera poses or a large number of input images, or even both. Reconstructing NeRF from few-view images without poses is challenging and highly ill-posed. To address this problem, we propose CAD-NeRF, a method reconstructed from less than 10 images without any known poses. Specifically, we build a mini library of several CAD models from ShapeNet and render them from many random views. Given sparse-view input images, we run a model and pose retrieval from the library, to get a model with similar shapes, serving as the density supervision and pose initializations. Here we propose a multi-view pose retrieval method to avoid pose conflicts among views, which is a new and unseen problem in uncalibrated NeRF methods. Then, the geometry of the object is trained by the CAD guidance. The deformation of the density field and camera poses are optimized jointly. Then texture and density are trained and fine-tuned as well. All training phases are in self-supervised manners. Comprehensive evaluations of synthetic and real images show that CAD-NeRF successfully learns accurate densities with a large deformation from retrieved CAD models, showing the generalization abilities.
Leveraging Label Semantics and Meta-Label Refinement for Multi-Label Question Classification
Nov 04, 2024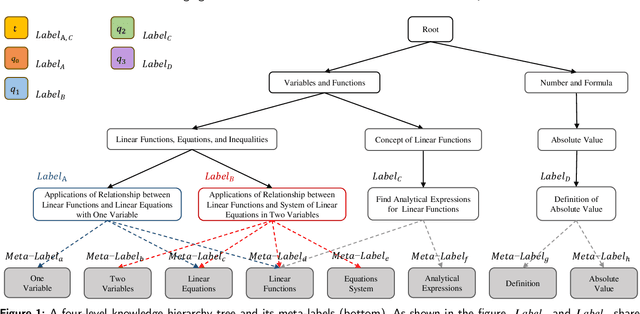
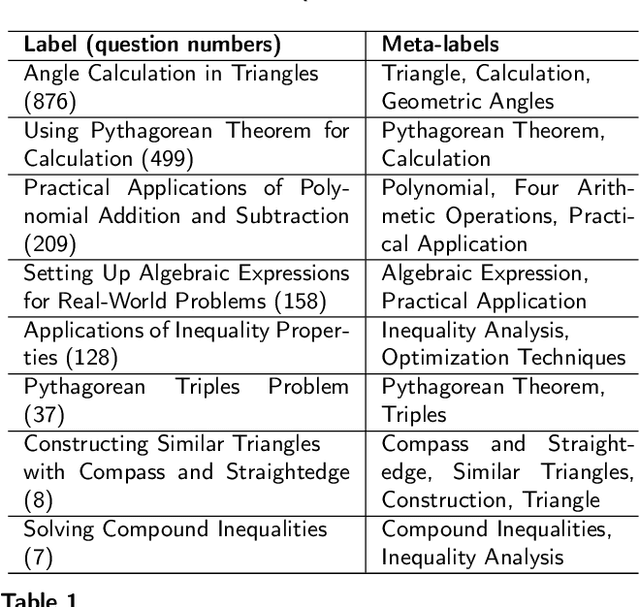

Accurate annotation of educational resources is critical in the rapidly advancing field of online education due to the complexity and volume of content. Existing classification methods face challenges with semantic overlap and distribution imbalance of labels in the multi-label context, which impedes effective personalized learning and resource recommendation. This paper introduces RR2QC, a novel Retrieval Reranking method To multi-label Question Classification by leveraging label semantics and meta-label refinement. Firstly, RR2QC leverages semantic relationships within and across label groups to enhance pre-training strategie in multi-label context. Next, a class center learning task is introduced, integrating label texts into downstream training to ensure questions consistently align with label semantics, retrieving the most relevant label sequences. Finally, this method decomposes labels into meta-labels and trains a meta-label classifier to rerank the retrieved label sequences. In doing so, RR2QC enhances the understanding and prediction capability of long-tail labels by learning from meta-labels frequently appearing in other labels. Addtionally, a Math LLM is used to generate solutions for questions, extracting latent information to further refine the model's insights. Experimental results demonstrate that RR2QC outperforms existing classification methods in Precision@k and F1 scores across multiple educational datasets, establishing it as a potent enhancement for online educational content utilization.
Variable Aperture Bokeh Rendering via Customized Focal Plane Guidance
Oct 18, 2024
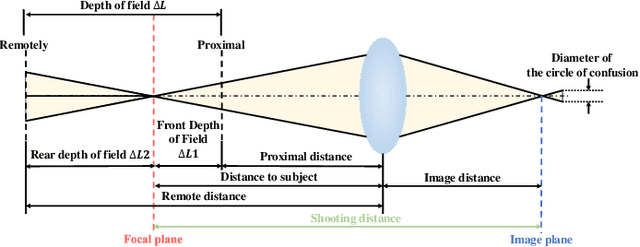
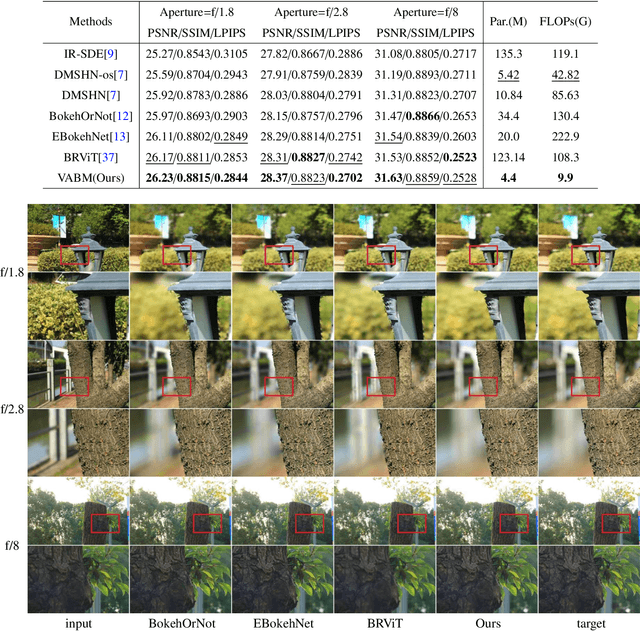
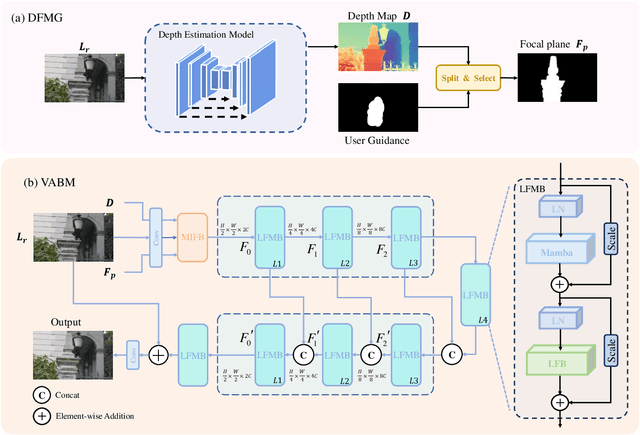
Bokeh rendering is one of the most popular techniques in photography. It can make photographs visually appealing, forcing users to focus their attentions on particular area of image. However, achieving satisfactory bokeh effect usually presents significant challenge, since mobile cameras with restricted optical systems are constrained, while expensive high-end DSLR lens with large aperture should be needed. Therefore, many deep learning-based computational photography methods have been developed to mimic the bokeh effect in recent years. Nevertheless, most of these methods were limited to rendering bokeh effect in certain single aperture. There lacks user-friendly bokeh rendering method that can provide precise focal plane control and customised bokeh generation. There as well lacks authentic realistic bokeh dataset that can potentially promote bokeh learning on variable apertures. To address these two issues, in this paper, we have proposed an effective controllable bokeh rendering method, and contributed a Variable Aperture Bokeh Dataset (VABD). In the proposed method, user can customize focal plane to accurately locate concerned subjects and select target aperture information for bokeh rendering. Experimental results on public EBB! benchmark dataset and our constructed dataset VABD have demonstrated that the customized focal plane together aperture prompt can bootstrap model to simulate realistic bokeh effect. The proposed method has achieved competitive state-of-the-art performance with only 4.4M parameters, which is much lighter than mainstream computational bokeh models. The contributed dataset and source codes will be released on github https://github.com/MoTong-AI-studio/VABM.