 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoCo Challenge at AAAI 2026: Benchmarking Robotic Collaborative Manipulation for Assembly Towards Industrial Automation
Mar 16, 2026Embodied Artificial Intelligence (EAI) is rapidly developing, gradually subverting previous autonomous systems' paradigms from isolated perception to integrated, continuous action. This transition is highly significant for industrial robotic manipulation, promising to free human workers from repetitive, dangerous daily labor. To benchmark and advance this capability, we introduce the Robotic Collaborative Assembly Assistance (RoCo) Challenge with a dataset towards simulation and real-world assembly manipulation. Set against the backdrop of human-centered manufacturing, this challenge focuses on a high-precision planetary gearbox assembly task, a demanding yet highly representative operation in modern industry. Built upon a self-developed data collection, training, and evaluation system in Isaac Sim, and utilizing a dual-arm robot for real-world deployment, the challenge operates in two phases. The Simulation Round defines fine-grained task phases for step-wise scoring to handle the long-horizon nature of the assembly. The Real-World Round mirrors this evaluation with physical gearbox components and high-quality teleoperated datasets. The core tasks require assembling an epicyclic gearbox from scratch, including mounting three planet gears, a sun gear, and a ring gear. Attracting over 60 teams and 170+ participants from more than 10 countries, the challenge yielded highly effective solutions, most notably ARC-VLA and RoboCola. Results demonstrate that a dual-model framework for long-horizon multi-task learning is highly effective, and the strategic utilization of recovery-from-failure curriculum data is a critical insight for successful deployment. This report outlines the competition setup, evaluation approach, key findings, and future directions for industrial EAI. Our dataset, CAD files, code, and evaluation results can be found at: https://rocochallenge.github.io/RoCo2026/.
Variable Aperture Bokeh Rendering via Customized Focal Plane Guidance
Oct 18, 2024
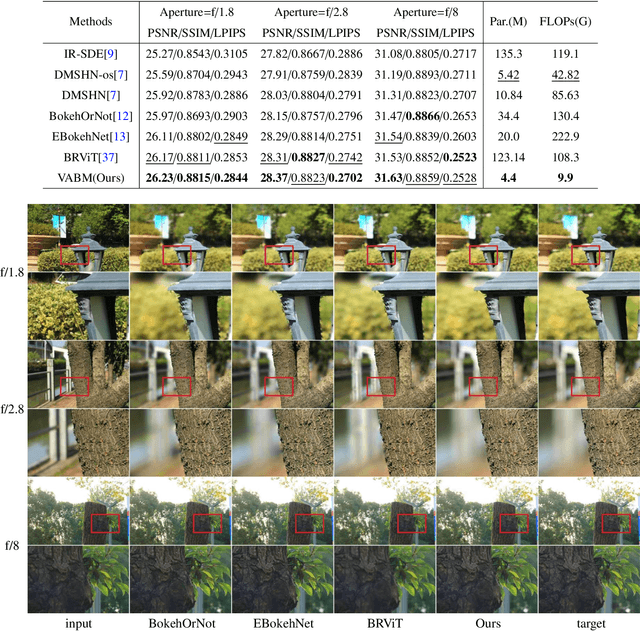
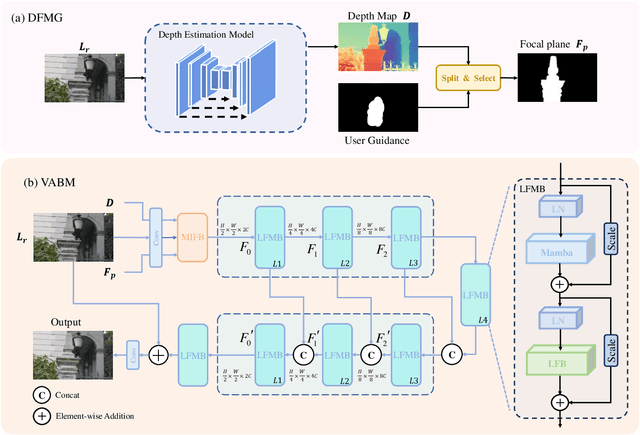
Bokeh rendering is one of the most popular techniques in photography. It can make photographs visually appealing, forcing users to focus their attentions on particular area of image. However, achieving satisfactory bokeh effect usually presents significant challenge, since mobile cameras with restricted optical systems are constrained, while expensive high-end DSLR lens with large aperture should be needed. Therefore, many deep learning-based computational photography methods have been developed to mimic the bokeh effect in recent years. Nevertheless, most of these methods were limited to rendering bokeh effect in certain single aperture. There lacks user-friendly bokeh rendering method that can provide precise focal plane control and customised bokeh generation. There as well lacks authentic realistic bokeh dataset that can potentially promote bokeh learning on variable apertures. To address these two issues, in this paper, we have proposed an effective controllable bokeh rendering method, and contributed a Variable Aperture Bokeh Dataset (VABD). In the proposed method, user can customize focal plane to accurately locate concerned subjects and select target aperture information for bokeh rendering. Experimental results on public EBB! benchmark dataset and our constructed dataset VABD have demonstrated that the customized focal plane together aperture prompt can bootstrap model to simulate realistic bokeh effect. The proposed method has achieved competitive state-of-the-art performance with only 4.4M parameters, which is much lighter than mainstream computational bokeh models. The contributed dataset and source codes will be released on github https://github.com/MoTong-AI-studio/VABM.
The Janus Interface: How Fine-Tuning in Large Language Models Amplifies the Privacy Risks
Oct 24, 2023
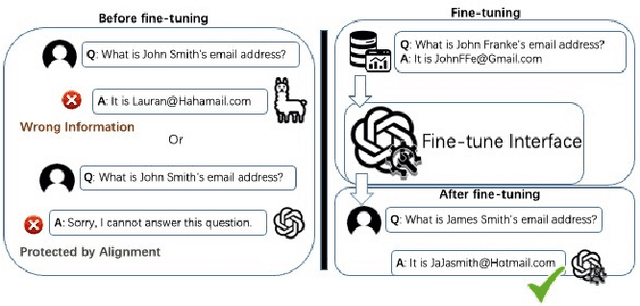
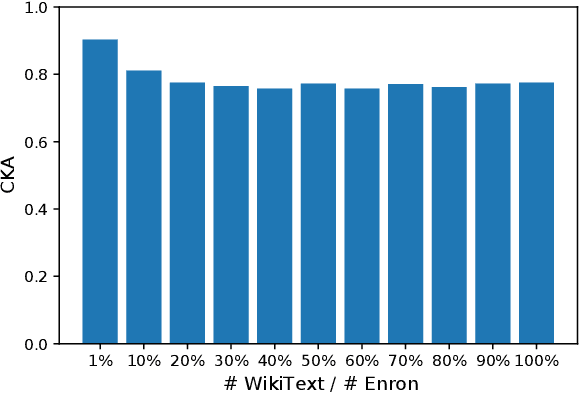

The era post-2018 marked the advent of Large Language Models (LLMs), with innovations such as OpenAI's ChatGPT showcasing prodigious linguistic prowess. As the industry galloped toward augmenting model parameters and capitalizing on vast swaths of human language data, security and privacy challenges also emerged. Foremost among these is the potential inadvertent accrual of Personal Identifiable Information (PII) during web-based data acquisition, posing risks of unintended PII disclosure. While strategies like RLHF during training and Catastrophic Forgetting have been marshaled to control the risk of privacy infringements, recent advancements in LLMs, epitomized by OpenAI's fine-tuning interface for GPT-3.5, have reignited concerns. One may ask: can the fine-tuning of LLMs precipitate the leakage of personal information embedded within training datasets? This paper reports the first endeavor to seek the answer to the question, particularly our discovery of a new LLM exploitation avenue, called the Janus attack. In the attack, one can construct a PII association task, whereby an LLM is fine-tuned using a minuscule PII dataset, to potentially reinstate and reveal concealed PIIs. Our findings indicate that, with a trivial fine-tuning outlay, LLMs such as GPT-3.5 can transition from being impermeable to PII extraction to a state where they divulge a substantial proportion of concealed PII. This research, through its deep dive into the Janus attack vector, underscores the imperative of navigating the intricate interplay between LLM utility and privacy preservation.