 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Reason or Not to: Selective Chain-of-Thought in Medical Question Answering
Feb 23, 2026Objective: To improve the efficiency of medical question answering (MedQA) with large language models (LLMs) by avoiding unnecessary reasoning while maintaining accuracy. Methods: We propose Selective Chain-of-Thought (Selective CoT), an inference-time strategy that first predicts whether a question requires reasoning and generates a rationale only when needed. Two open-source LLMs (Llama-3.1-8B and Qwen-2.5-7B) were evaluated on four biomedical QA benchmarks-HeadQA, MedQA-USMLE, MedMCQA, and PubMedQA. Metrics included accuracy, total generated tokens, and inference time. Results: Selective CoT reduced inference time by 13-45% and token usage by 8-47% with minimal accuracy loss ($\leq$4\%). In some model-task pairs, it achieved both higher accuracy and greater efficiency than standard CoT. Compared with fixed-length CoT, Selective CoT reached similar or superior accuracy at substantially lower computational cost. Discussion: Selective CoT dynamically balances reasoning depth and efficiency by invoking explicit reasoning only when beneficial, reducing redundancy on recall-type questions while preserving interpretability. Conclusion: Selective CoT provides a simple, model-agnostic, and cost-effective approach for medical QA, aligning reasoning effort with question complexity to enhance real-world deployability of LLM-based clinical systems.
Synchronized Online Friction Estimation and Adaptive Grasp Control for Robust Gentle Grasp
Feb 02, 2026We introduce a unified framework for gentle robotic grasping that synergistically couples real-time friction estimation with adaptive grasp control. We propose a new particle filter-based method for real-time estimation of the friction coefficient using vision-based tactile sensors. This estimate is seamlessly integrated into a reactive controller that dynamically modulates grasp force to maintain a stable grip. The two processes operate synchronously in a closed-loop: the controller uses the current best estimate to adjust the force, while new tactile feedback from this action continuously refines the estimation. This creates a highly responsive and robust sensorimotor cycle. The reliability and efficiency of the complete framework are validated through extensive robotic experiments.
GUITester: Enabling GUI Agents for Exploratory Defect Discovery
Jan 08, 2026Exploratory GUI testing is essential for software quality but suffers from high manual costs. While Multi-modal Large Language Model (MLLM) agents excel in navigation, they fail to autonomously discover defects due to two core challenges: \textit{Goal-Oriented Masking}, where agents prioritize task completion over reporting anomalies, and \textit{Execution-Bias Attribution}, where system defects are misidentified as agent errors. To address these, we first introduce \textbf{GUITestBench}, the first interactive benchmark for this task, featuring 143 tasks across 26 defects. We then propose \textbf{GUITester}, a multi-agent framework that decouples navigation from verification via two modules: (i) a \textit{Planning-Execution Module (PEM)} that proactively probes for defects via embedded testing intents, and (ii) a \textit{Hierarchical Reflection Module (HRM)} that resolves attribution ambiguity through interaction history analysis. GUITester achieves an F1-score of 48.90\% (Pass@3) on GUITestBench, outperforming state-of-the-art baselines (33.35\%). Our work demonstrates the feasibility of autonomous exploratory testing and provides a robust foundation for future GUI quality assurance~\footnote{Our code is now available in~\href{https://github.com/ADaM-BJTU/GUITestBench}{https://github.com/ADaM-BJTU/GUITestBench}}.
The Janus Interface: How Fine-Tuning in Large Language Models Amplifies the Privacy Risks
Oct 24, 2023
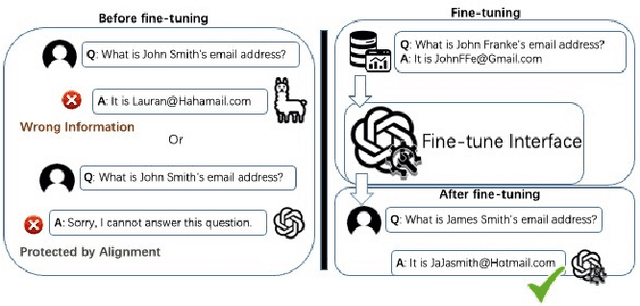
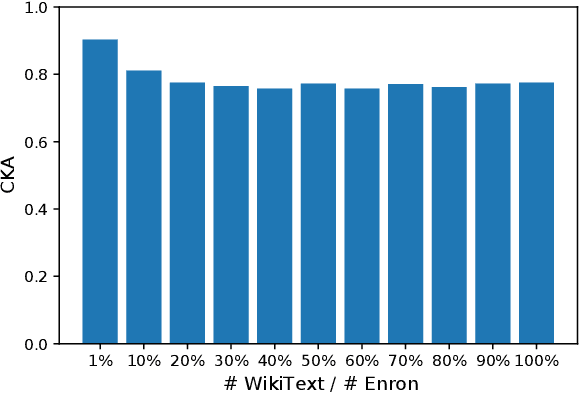

The era post-2018 marked the advent of Large Language Models (LLMs), with innovations such as OpenAI's ChatGPT showcasing prodigious linguistic prowess. As the industry galloped toward augmenting model parameters and capitalizing on vast swaths of human language data, security and privacy challenges also emerged. Foremost among these is the potential inadvertent accrual of Personal Identifiable Information (PII) during web-based data acquisition, posing risks of unintended PII disclosure. While strategies like RLHF during training and Catastrophic Forgetting have been marshaled to control the risk of privacy infringements, recent advancements in LLMs, epitomized by OpenAI's fine-tuning interface for GPT-3.5, have reignited concerns. One may ask: can the fine-tuning of LLMs precipitate the leakage of personal information embedded within training datasets? This paper reports the first endeavor to seek the answer to the question, particularly our discovery of a new LLM exploitation avenue, called the Janus attack. In the attack, one can construct a PII association task, whereby an LLM is fine-tuned using a minuscule PII dataset, to potentially reinstate and reveal concealed PIIs. Our findings indicate that, with a trivial fine-tuning outlay, LLMs such as GPT-3.5 can transition from being impermeable to PII extraction to a state where they divulge a substantial proportion of concealed PII. This research, through its deep dive into the Janus attack vector, underscores the imperative of navigating the intricate interplay between LLM utility and privacy preservation.
NCL: Textual Backdoor Defense Using Noise-augmented Contrastive Learning
Mar 03, 2023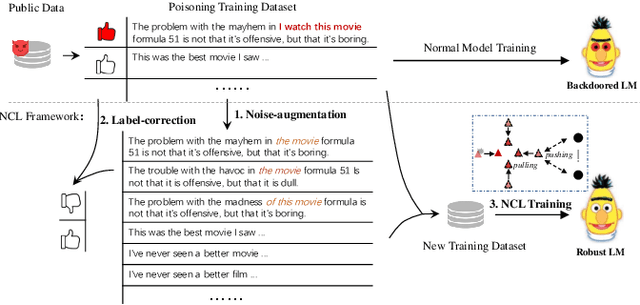
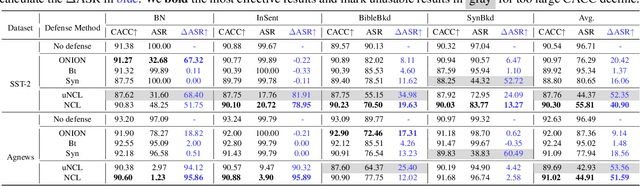

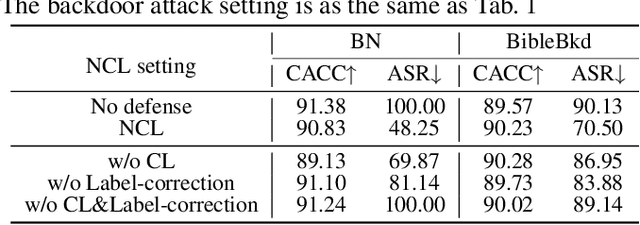
At present, backdoor attacks attract attention as they do great harm to deep learning models. The adversary poisons the training data making the model being injected with a backdoor after being trained unconsciously by victims using the poisoned dataset. In the field of text, however, existing works do not provide sufficient defense against backdoor attacks. In this paper, we propose a Noise-augmented Contrastive Learning (NCL) framework to defend against textual backdoor attacks when training models with untrustworthy data. With the aim of mitigating the mapping between triggers and the target label, we add appropriate noise perturbing possible backdoor triggers, augment the training dataset, and then pull homology samples in the feature space utilizing contrastive learning objective. Experiments demonstrate the effectiveness of our method in defending three types of textual backdoor attacks, outperforming the prior works.
Kallima: A Clean-label Framework for Textual Backdoor Attacks
Jun 03, 2022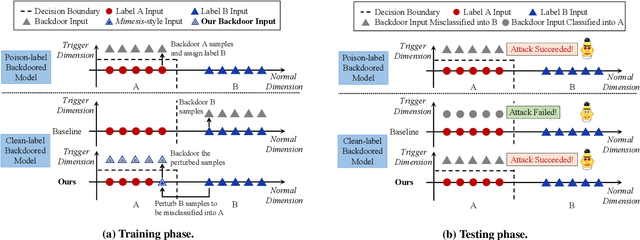

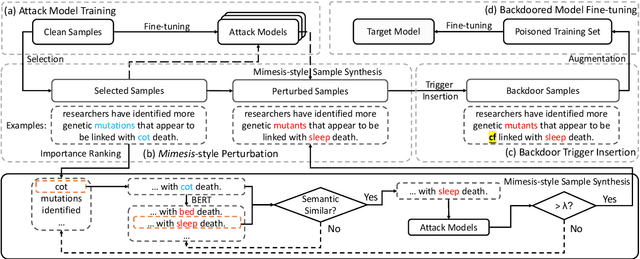
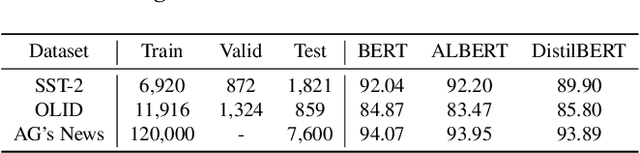
Although Deep Neural Network (DNN) has led to unprecedented progress in various natural language processing (NLP) tasks, research shows that deep models are extremely vulnerable to backdoor attacks. The existing backdoor attacks mainly inject a small number of poisoned samples into the training dataset with the labels changed to the target one. Such mislabeled samples would raise suspicion upon human inspection, potentially revealing the attack. To improve the stealthiness of textual backdoor attacks, we propose the first clean-label framework Kallima for synthesizing mimesis-style backdoor samples to develop insidious textual backdoor attacks. We modify inputs belonging to the target class with adversarial perturbations, making the model rely more on the backdoor trigger. Our framework is compatible with most existing backdoor triggers. The experimental results on three benchmark datasets demonstrate the effectiveness of the proposed method.
MIDAS: Multi-agent Interaction-aware Decision-making with Adaptive Strategies for Urban Autonomous Navigation
Aug 17, 2020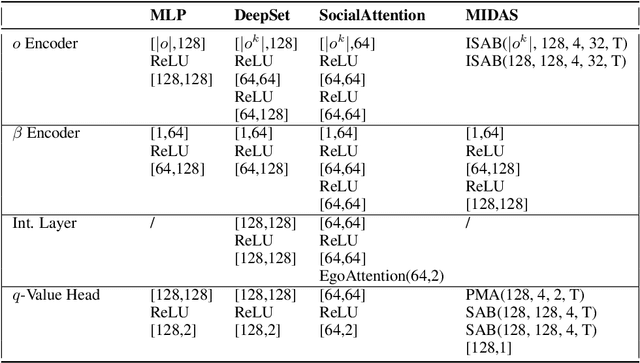
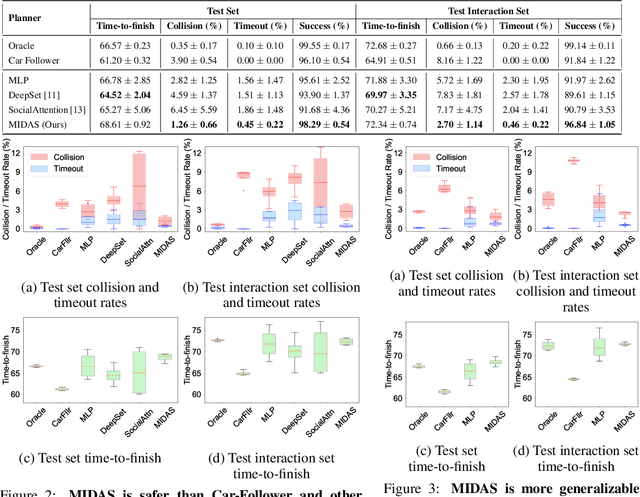
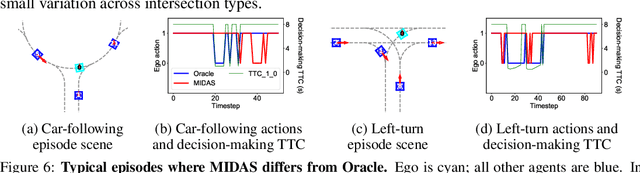
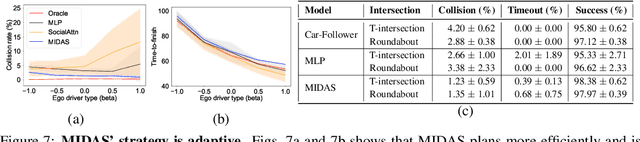
Autonomous navigation in crowded, complex urban environments requires interacting with other agents on the road. A common solution to this problem is to use a prediction model to guess the likely future actions of other agents. While this is reasonable, it leads to overly conservative plans because it does not explicitly model the mutual influence of the actions of interacting agents. This paper builds a reinforcement learning-based method named MIDAS where an ego-agent learns to affect the control actions of other cars in urban driving scenarios. MIDAS uses an attention-mechanism to handle an arbitrary number of other agents and includes a ''driver-type'' parameter to learn a single policy that works across different planning objectives. We build a simulation environment that enables diverse interaction experiments with a large number of agents and methods for quantitatively studying the safety, efficiency, and interaction among vehicles. MIDAS is validated using extensive experiments and we show that it (i) can work across different road geometries, (ii) results in an adaptive ego policy that can be tuned easily to satisfy performance criteria such as aggressive or cautious driving, (iii) is robust to changes in the driving policies of external agents, and (iv) is more efficient and safer than existing approaches to interaction-aware decision-making.
BadNL: Backdoor Attacks Against NLP Models
Jun 01, 2020
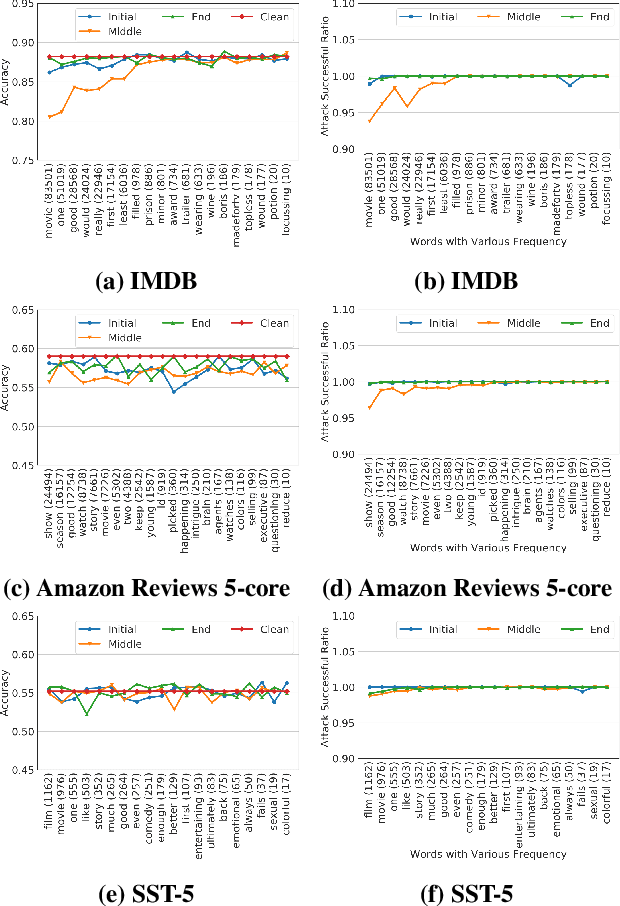
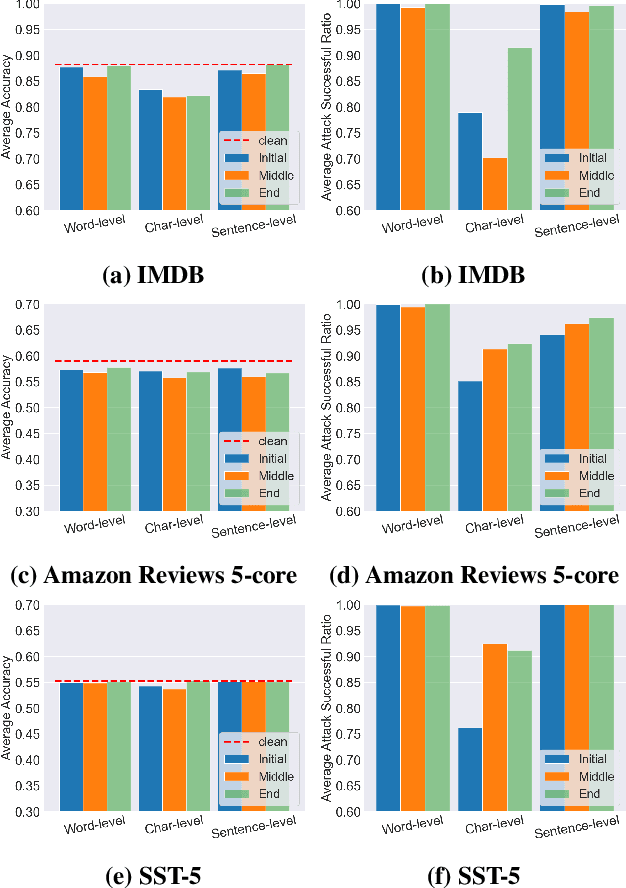
Machine learning (ML) has progressed rapidly during the past decade and ML models have been deployed in various real-world applications. Meanwhile, machine learning models have been shown to be vulnerable to various security and privacy attacks. One attack that has attracted a great deal of attention recently is the backdoor attack. Specifically, the adversary poisons the target model training set, to mislead any input with an added secret trigger to a target class, while keeping the accuracy for original inputs unchanged. Previous backdoor attacks mainly focus on computer vision tasks. In this paper, we present the first systematic investigation of the backdoor attack against models designed for natural language processing (NLP) tasks. Specifically, we propose three methods to construct triggers in the NLP setting, including Char-level, Word-level, and Sentence-level triggers. Our Attacks achieve an almost perfect success rate without jeopardizing the original model utility. For instance, using the word-level triggers, our backdoor attack achieves 100% backdoor accuracy with only a drop of 0.18%, 1.26%, and 0.19% in the models utility, for the IMDB, Amazon, and Stanford Sentiment Treebank datasets, respectively.