 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow does Chain of Thought decompose complex tasks?
Apr 10, 2026Many language tasks can be modeled as classification problems where a large language model (LLM) is given a prompt and selects one among many possible answers. We show that the classification error in such problems scales as a power law in the number of classes. This has a dramatic consequence: the prediction error can be reduced substantially by splitting the overall task into a sequence of smaller classification problems, each with the same number of classes ("degree"). This tree-structured decomposition models chain-of-thought (CoT). It has been observed that CoT-based predictors perform better when they "think'", i.e., when they develop a deeper tree, thus decomposing the problem into a larger number of steps. We identify a critical threshold for the degree, below which thinking is detrimental, and above which there exists an optimal depth that minimizes the error. It is impossible to surpass this minimal error by increasing the depth of thinking.
Neuromorphic Computing for Low-Power Artificial Intelligence
Apr 06, 2026Classical computing is beginning to encounter fundamental limits of energy efficiency. This presents a challenge that can no longer be solved by strategies such as increasing circuit density or refining standard semiconductor processes. The growing computational and memory demands of artificial intelligence (AI) require disruptive innovation in how information is represented, stored, communicated, and processed. By leveraging novel device modalities and compute-in-memory (CIM), in addition to analog dynamics and sparse communication inspired by the brain, neuromorphic computing offers a promising path toward improvements in the energy efficiency and scalability of current AI systems. But realizing this potential is not a matter of replacing one chip with another; rather, it requires a co-design effort, spanning new materials and non-volatile device structures, novel mixed-signal circuits and architectures, and learning algorithms tailored to the physics of these substrates. This article surveys the key limitations of classical complementary metal-oxide-semiconductor (CMOS) technology and outlines how such cross-layer neuromorphic approaches may overcome them.
Factored Levenberg-Marquardt for Diffeomorphic Image Registration: An efficient optimizer for FireANTs
Mar 19, 2026FireANTs introduced a novel Eulerian descent method for plug-and-play behavior with arbitrary optimizers adapted for diffeomorphic image registration as a test-time optimization problem, with a GPU-accelerated implementation. FireANTs uses Adam as its default optimizer for fast and more robust optimization. However, Adam requires storing state variables (i.e. momentum and squared-momentum estimates), each of which can consume significant memory, prohibiting its use for significantly large images. In this work, we propose a modified Levenberg-Marquardt (LM) optimizer that requires only a single scalar damping parameter as optimizer state, that is adaptively tuned using a trust region approach. The resulting optimizer reduces memory by up to 24.6% for large volumes, and retaining performance across all four datasets. A single hyperparameter configuration tuned on brain MRI transfers without modification to lung CT and cross-modal abdominal registration, matching or outperforming Adam on three of four benchmarks. We also perform ablations on the effectiveness of using Metropolis-Hastings style rejection step to prevent updates that worsen the loss function.
Neurosim: A Fast Simulator for Neuromorphic Robot Perception
Feb 16, 2026Neurosim is a fast, real-time, high-performance library for simulating sensors such as dynamic vision sensors, RGB cameras, depth sensors, and inertial sensors. It can also simulate agile dynamics of multi-rotor vehicles in complex and dynamic environments. Neurosim can achieve frame rates as high as ~2700 FPS on a desktop GPU. Neurosim integrates with a ZeroMQ-based communication library called Cortex to facilitate seamless integration with machine learning and robotics workflows. Cortex provides a high-throughput, low-latency message-passing system for Python and C++ applications, with native support for NumPy arrays and PyTorch tensors. This paper discusses the design philosophy behind Neurosim and Cortex. It demonstrates how they can be used to (i) train neuromorphic perception and control algorithms, e.g., using self-supervised learning on time-synchronized multi-modal data, and (ii) test real-time implementations of these algorithms in closed-loop. Neurosim and Cortex are available at https://github.com/grasp-lyrl/neurosim .
The LUMirage: An independent evaluation of zero-shot performance in the LUMIR challenge
Dec 17, 2025The LUMIR challenge represents an important benchmark for evaluating deformable image registration methods on large-scale neuroimaging data. While the challenge demonstrates that modern deep learning methods achieve competitive accuracy on T1-weighted MRI, it also claims exceptional zero-shot generalization to unseen contrasts and resolutions, assertions that contradict established understanding of domain shift in deep learning. In this paper, we perform an independent re-evaluation of these zero-shot claims using rigorous evaluation protocols while addressing potential sources of instrumentation bias. Our findings reveal a more nuanced picture: (1) deep learning methods perform comparably to iterative optimization on in-distribution T1w images and even on human-adjacent species (macaque), demonstrating improved task understanding; (2) however, performance degrades significantly on out-of-distribution contrasts (T2, T2*, FLAIR), with Cohen's d scores ranging from 0.7-1.5, indicating substantial practical impact on downstream clinical workflows; (3) deep learning methods face scalability limitations on high-resolution data, failing to run on 0.6 mm isotropic images, while iterative methods benefit from increased resolution; and (4) deep methods exhibit high sensitivity to preprocessing choices. These results align with the well-established literature on domain shift and suggest that claims of universal zero-shot superiority require careful scrutiny. We advocate for evaluation protocols that reflect practical clinical and research workflows rather than conditions that may inadvertently favor particular method classes.
Concurrence: A dependence criterion for time series, applied to biological data
Dec 17, 2025Measuring the statistical dependence between observed signals is a primary tool for scientific discovery. However, biological systems often exhibit complex non-linear interactions that currently cannot be captured without a priori knowledge or large datasets. We introduce a criterion for dependence, whereby two time series are deemed dependent if one can construct a classifier that distinguishes between temporally aligned vs. misaligned segments extracted from them. We show that this criterion, concurrence, is theoretically linked with dependence, and can become a standard approach for scientific analyses across disciplines, as it can expose relationships across a wide spectrum of signals (fMRI, physiological and behavioral data) without ad-hoc parameter tuning or large amounts of data.
Symskill: Symbol and Skill Co-Invention for Data-Efficient and Real-Time Long-Horizon Manipulation
Oct 02, 2025Multi-step manipulation in dynamic environments remains challenging. Two major families of methods fail in distinct ways: (i) imitation learning (IL) is reactive but lacks compositional generalization, as monolithic policies do not decide which skill to reuse when scenes change; (ii) classical task-and-motion planning (TAMP) offers compositionality but has prohibitive planning latency, preventing real-time failure recovery. We introduce SymSkill, a unified learning framework that combines the benefits of IL and TAMP, allowing compositional generalization and failure recovery in real-time. Offline, SymSkill jointly learns predicates, operators, and skills directly from unlabeled and unsegmented demonstrations. At execution time, upon specifying a conjunction of one or more learned predicates, SymSkill uses a symbolic planner to compose and reorder learned skills to achieve the symbolic goals, while performing recovery at both the motion and symbolic levels in real time. Coupled with a compliant controller, SymSkill enables safe and uninterrupted execution under human and environmental disturbances. In RoboCasa simulation, SymSkill can execute 12 single-step tasks with 85% success rate. Without additional data, it composes these skills into multi-step plans requiring up to 6 skill recompositions, recovering robustly from execution failures. On a real Franka robot, we demonstrate SymSkill, learning from 5 minutes of unsegmented and unlabeled play data, is capable of performing multiple tasks simply by goal specifications. The source code and additional analysis can be found on https://sites.google.com/view/symskill.
Prospective Learning in Retrospect
Jul 10, 2025In most real-world applications of artificial intelligence, the distributions of the data and the goals of the learners tend to change over time. The Probably Approximately Correct (PAC) learning framework, which underpins most machine learning algorithms, fails to account for dynamic data distributions and evolving objectives, often resulting in suboptimal performance. Prospective learning is a recently introduced mathematical framework that overcomes some of these limitations. We build on this framework to present preliminary results that improve the algorithm and numerical results, and extend prospective learning to sequential decision-making scenarios, specifically foraging. Code is available at: https://github.com/neurodata/prolearn2.
Gaussian Splatting as a Unified Representation for Autonomy in Unstructured Environments
May 17, 2025In this work, we argue that Gaussian splatting is a suitable unified representation for autonomous robot navigation in large-scale unstructured outdoor environments. Such environments require representations that can capture complex structures while remaining computationally tractable for real-time navigation. We demonstrate that the dense geometric and photometric information provided by a Gaussian splatting representation is useful for navigation in unstructured environments. Additionally, semantic information can be embedded in the Gaussian map to enable large-scale task-driven navigation. From the lessons learned through our experiments, we highlight several challenges and opportunities arising from the use of such a representation for robot autonomy.
An Analytical Characterization of Sloppiness in Neural Networks: Insights from Linear Models
May 13, 2025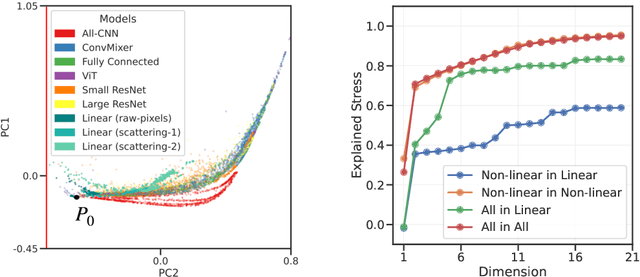
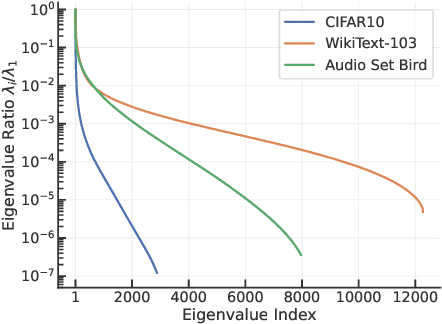
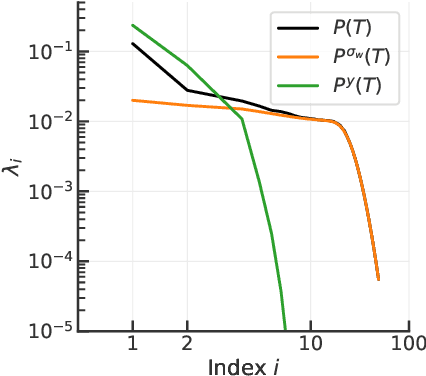
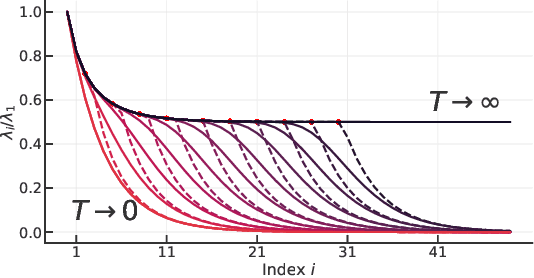
Recent experiments have shown that training trajectories of multiple deep neural networks with different architectures, optimization algorithms, hyper-parameter settings, and regularization methods evolve on a remarkably low-dimensional "hyper-ribbon-like" manifold in the space of probability distributions. Inspired by the similarities in the training trajectories of deep networks and linear networks, we analytically characterize this phenomenon for the latter. We show, using tools in dynamical systems theory, that the geometry of this low-dimensional manifold is controlled by (i) the decay rate of the eigenvalues of the input correlation matrix of the training data, (ii) the relative scale of the ground-truth output to the weights at the beginning of training, and (iii) the number of steps of gradient descent. By analytically computing and bounding the contributions of these quantities, we characterize phase boundaries of the region where hyper-ribbons are to be expected. We also extend our analysis to kernel machines and linear models that are trained with stochastic gradient descent.