 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymskill: Symbol and Skill Co-Invention for Data-Efficient and Real-Time Long-Horizon Manipulation
Oct 02, 2025Multi-step manipulation in dynamic environments remains challenging. Two major families of methods fail in distinct ways: (i) imitation learning (IL) is reactive but lacks compositional generalization, as monolithic policies do not decide which skill to reuse when scenes change; (ii) classical task-and-motion planning (TAMP) offers compositionality but has prohibitive planning latency, preventing real-time failure recovery. We introduce SymSkill, a unified learning framework that combines the benefits of IL and TAMP, allowing compositional generalization and failure recovery in real-time. Offline, SymSkill jointly learns predicates, operators, and skills directly from unlabeled and unsegmented demonstrations. At execution time, upon specifying a conjunction of one or more learned predicates, SymSkill uses a symbolic planner to compose and reorder learned skills to achieve the symbolic goals, while performing recovery at both the motion and symbolic levels in real time. Coupled with a compliant controller, SymSkill enables safe and uninterrupted execution under human and environmental disturbances. In RoboCasa simulation, SymSkill can execute 12 single-step tasks with 85% success rate. Without additional data, it composes these skills into multi-step plans requiring up to 6 skill recompositions, recovering robustly from execution failures. On a real Franka robot, we demonstrate SymSkill, learning from 5 minutes of unsegmented and unlabeled play data, is capable of performing multiple tasks simply by goal specifications. The source code and additional analysis can be found on https://sites.google.com/view/symskill.
Don't Yell at Your Robot: Physical Correction as the Collaborative Interface for Language Model Powered Robots
Dec 17, 2024



We present a novel approach for enhancing human-robot collaboration using physical interactions for real-time error correction of large language model (LLM) powered robots. Unlike other methods that rely on verbal or text commands, the robot leverages an LLM to proactively executes 6 DoF linear Dynamical System (DS) commands using a description of the scene in natural language. During motion, a human can provide physical corrections, used to re-estimate the desired intention, also parameterized by linear DS. This corrected DS can be converted to natural language and used as part of the prompt to improve future LLM interactions. We provide proof-of-concept result in a hybrid real+sim experiment, showcasing physical interaction as a new possibility for LLM powered human-robot interface.
Constraint-Aware Intent Estimation for Dynamic Human-Robot Object Co-Manipulation
Aug 30, 2024Constraint-aware estimation of human intent is essential for robots to physically collaborate and interact with humans. Further, to achieve fluid collaboration in dynamic tasks intent estimation should be achieved in real-time. In this paper, we present a framework that combines online estimation and control to facilitate robots in interpreting human intentions, and dynamically adjust their actions to assist in dynamic object co-manipulation tasks while considering both robot and human constraints. Central to our approach is the adoption of a Dynamic Systems (DS) model to represent human intent. Such a low-dimensional parameterized model, along with human manipulability and robot kinematic constraints, enables us to predict intent using a particle filter solely based on past motion data and tracking errors. For safe assistive control, we propose a variable impedance controller that adapts the robot's impedance to offer assistance based on the intent estimation confidence from the DS particle filter. We validate our framework on a challenging real-world human-robot co-manipulation task and present promising results over baselines. Our framework represents a significant step forward in physical human-robot collaboration (pHRC), ensuring that robot cooperative interactions with humans are both feasible and effective.
Active Perception using Neural Radiance Fields
Oct 15, 2023



We study active perception from first principles to argue that an autonomous agent performing active perception should maximize the mutual information that past observations posses about future ones. Doing so requires (a) a representation of the scene that summarizes past observations and the ability to update this representation to incorporate new observations (state estimation and mapping), (b) the ability to synthesize new observations of the scene (a generative model), and (c) the ability to select control trajectories that maximize predictive information (planning). This motivates a neural radiance field (NeRF)-like representation which captures photometric, geometric and semantic properties of the scene grounded. This representation is well-suited to synthesizing new observations from different viewpoints. And thereby, a sampling-based planner can be used to calculate the predictive information from synthetic observations along dynamically-feasible trajectories. We use active perception for exploring cluttered indoor environments and employ a notion of semantic uncertainty to check for the successful completion of an exploration task. We demonstrate these ideas via simulation in realistic 3D indoor environments.
Design and Evaluation of Motion Planners for Quadrotors
Sep 24, 2023



The field of quadrotor motion planning has experienced significant advancements over the last decade. Most successful approaches rely on two stages: a front-end that determines the best path by incorporating geometric (and in some cases kinematic or input) constraints, that effectively specify the homotopy class of the trajectory; and a back-end that optimizes the path with a suitable objective function, constrained by the robot's dynamics as well as state/input constraints. However, there is no systematic approach or design guidelines to design both the front and the back ends for a wide range of environments, and no literature evaluates the performance of the trajectory planning algorithm with varying degrees of environment complexity. In this paper, we propose a modular approach to designing the software planning stack and offer a parameterized set of environments to systematically evaluate the performance of two-stage planners. Our parametrized environments enable us to access different front and back-end planners as a function of environmental clutter and complexity. We use simulation and experimental results to demonstrate the performance of selected planning algorithms across a range of environments. Finally, we open source the planning/evaluation stack and parameterized environments to facilitate more in-depth studies of quadrotor motion planning, available at https://github.com/KumarRobotics/kr_mp_design
Reachability-based Trajectory Safeguard (RTS): A Safe and Fast Reinforcement Learning Safety Layer for Continuous Control
Nov 17, 2020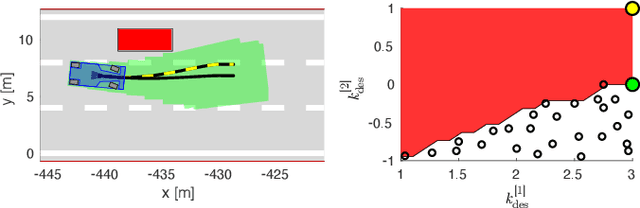
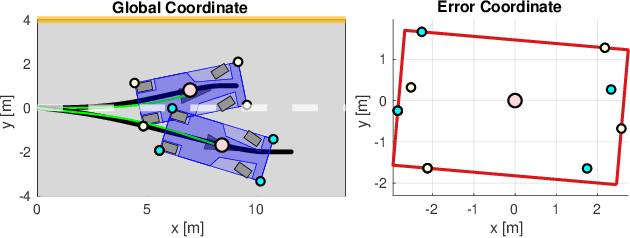
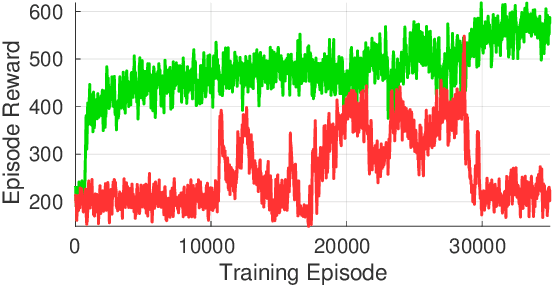
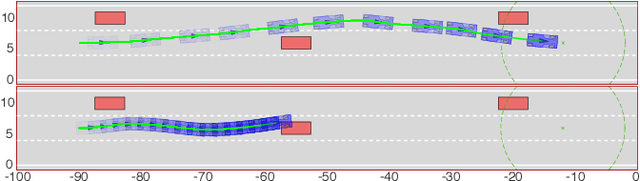
Reinforcement Learning (RL) algorithms have achieved remarkable performance in decision making and control tasks due to their ability to reason about long-term, cumulative reward using trial and error. However, during RL training, applying this trial-and-error approach to real-world robots operating in safety critical environment may lead to collisions. To address this challenge, this paper proposes a Reachability-based Trajectory Safeguard (RTS), which leverages trajectory parameterization and reachability analysis to ensure safety while a policy is being learned. This method ensures a robot with continuous action space can be trained from scratch safely in real-time. Importantly, this safety layer can still be applied after a policy has been learned. The efficacy of this method is illustrated on three nonlinear robot models, including a 12-D quadrotor drone, in simulation. By ensuring safety with RTS, this paper demonstrates that the proposed algorithm is not only safe, but can achieve a higher reward in a considerably shorter training time when compared to a non-safe counterpart.