 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTSM: Combining Trait and State Emotions for Empathetic Response Model
Mar 22, 2024Empathetic response generation endeavors to empower dialogue systems to perceive speakers' emotions and generate empathetic responses accordingly. Psychological research demonstrates that emotion, as an essential factor in empathy, encompasses trait emotions, which are static and context-independent, and state emotions, which are dynamic and context-dependent. However, previous studies treat them in isolation, leading to insufficient emotional perception of the context, and subsequently, less effective empathetic expression. To address this problem, we propose Combining Trait and State emotions for Empathetic Response Model (CTSM). Specifically, to sufficiently perceive emotions in dialogue, we first construct and encode trait and state emotion embeddings, and then we further enhance emotional perception capability through an emotion guidance module that guides emotion representation. In addition, we propose a cross-contrastive learning decoder to enhance the model's empathetic expression capability by aligning trait and state emotions between generated responses and contexts. Both automatic and manual evaluation results demonstrate that CTSM outperforms state-of-the-art baselines and can generate more empathetic responses. Our code is available at https://github.com/wangyufeng-empty/CTSM
Unsupervised Learning of Fine Structure Generation for 3D Point Clouds by 2D Projection Matching
Aug 08, 2021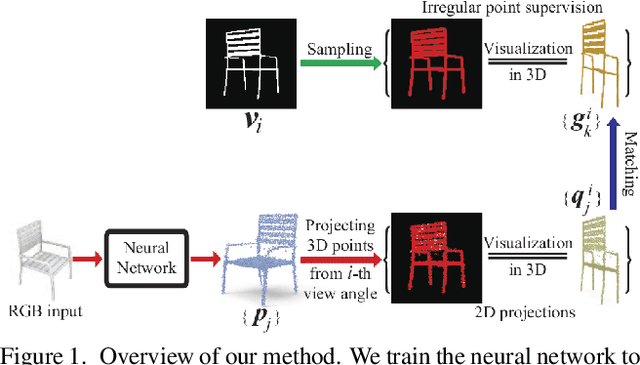



Learning to generate 3D point clouds without 3D supervision is an important but challenging problem. Current solutions leverage various differentiable renderers to project the generated 3D point clouds onto a 2D image plane, and train deep neural networks using the per-pixel difference with 2D ground truth images. However, these solutions are still struggling to fully recover fine structures of 3D shapes, such as thin tubes or planes. To resolve this issue, we propose an unsupervised approach for 3D point cloud generation with fine structures. Specifically, we cast 3D point cloud learning as a 2D projection matching problem. Rather than using entire 2D silhouette images as a regular pixel supervision, we introduce structure adaptive sampling to randomly sample 2D points within the silhouettes as an irregular point supervision, which alleviates the consistency issue of sampling from different view angles. Our method pushes the neural network to generate a 3D point cloud whose 2D projections match the irregular point supervision from different view angles. Our 2D projection matching approach enables the neural network to learn more accurate structure information than using the per-pixel difference, especially for fine and thin 3D structures. Our method can recover fine 3D structures from 2D silhouette images at different resolutions, and is robust to different sampling methods and point number in irregular point supervision. Our method outperforms others under widely used benchmarks. Our code, data and models are available at https://github.com/chenchao15/2D\_projection\_matching.
Reachability-based Trajectory Safeguard (RTS): A Safe and Fast Reinforcement Learning Safety Layer for Continuous Control
Nov 17, 2020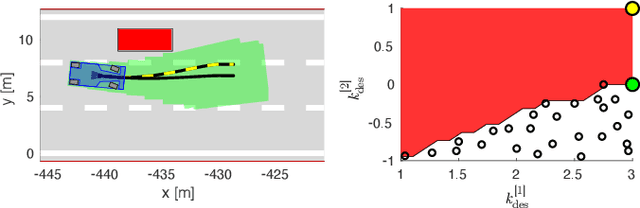
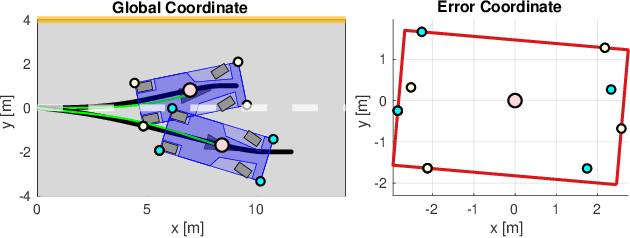
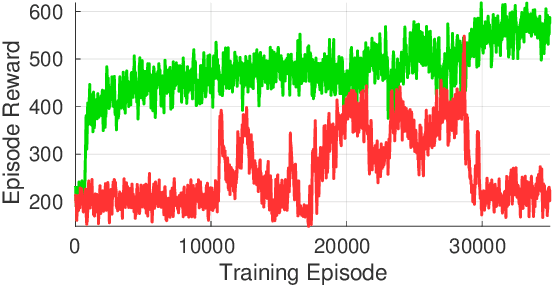
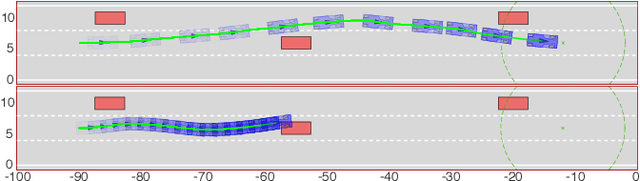
Reinforcement Learning (RL) algorithms have achieved remarkable performance in decision making and control tasks due to their ability to reason about long-term, cumulative reward using trial and error. However, during RL training, applying this trial-and-error approach to real-world robots operating in safety critical environment may lead to collisions. To address this challenge, this paper proposes a Reachability-based Trajectory Safeguard (RTS), which leverages trajectory parameterization and reachability analysis to ensure safety while a policy is being learned. This method ensures a robot with continuous action space can be trained from scratch safely in real-time. Importantly, this safety layer can still be applied after a policy has been learned. The efficacy of this method is illustrated on three nonlinear robot models, including a 12-D quadrotor drone, in simulation. By ensuring safety with RTS, this paper demonstrates that the proposed algorithm is not only safe, but can achieve a higher reward in a considerably shorter training time when compared to a non-safe counterpart.