 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReachability-based Trajectory Safeguard (RTS): A Safe and Fast Reinforcement Learning Safety Layer for Continuous Control
Paper and Code
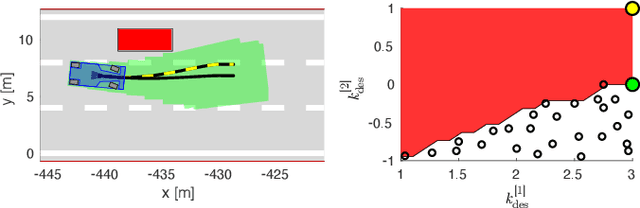
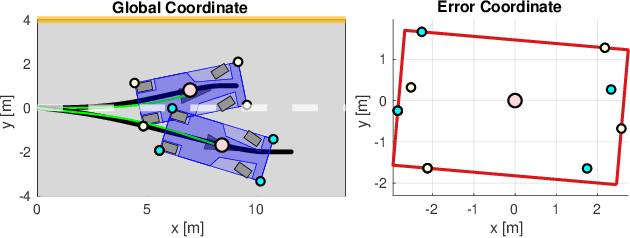
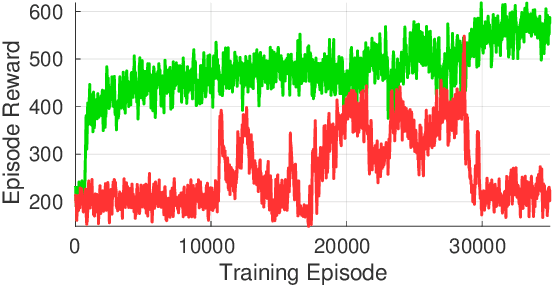
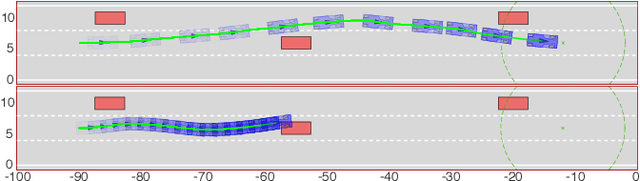
Reinforcement Learning (RL) algorithms have achieved remarkable performance in decision making and control tasks due to their ability to reason about long-term, cumulative reward using trial and error. However, during RL training, applying this trial-and-error approach to real-world robots operating in safety critical environment may lead to collisions. To address this challenge, this paper proposes a Reachability-based Trajectory Safeguard (RTS), which leverages trajectory parameterization and reachability analysis to ensure safety while a policy is being learned. This method ensures a robot with continuous action space can be trained from scratch safely in real-time. Importantly, this safety layer can still be applied after a policy has been learned. The efficacy of this method is illustrated on three nonlinear robot models, including a 12-D quadrotor drone, in simulation. By ensuring safety with RTS, this paper demonstrates that the proposed algorithm is not only safe, but can achieve a higher reward in a considerably shorter training time when compared to a non-safe counterpart.