 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianGrow: Geometry-aware Gaussian Growing from 3D Point Clouds with Text Guidance
Apr 07, 20263D Gaussian Splatting has demonstrated superior performance in rendering efficiency and quality, yet the generation of 3D Gaussians still remains a challenge without proper geometric priors. Existing methods have explored predicting point maps as geometric references for inferring Gaussian primitives, while the unreliable estimated geometries may lead to poor generations. In this work, we introduce GaussianGrow, a novel approach that generates 3D Gaussians by learning to grow them from easily accessible 3D point clouds, naturally enforcing geometric accuracy in Gaussian generation. Specifically, we design a text-guided Gaussian growing scheme that leverages a multi-view diffusion model to synthesize consistent appearances from input point clouds for supervision. To mitigate artifacts caused by fusing neighboring views, we constrain novel views generated at non-preset camera poses identified in overlapping regions across different views. For completing the hard-to-observe regions, we propose to iteratively detect the camera pose by observing the largest un-grown regions in point clouds and inpainting them by inpainting the rendered view with a pretrained 2D diffusion model. The process continues until complete Gaussians are generated. We extensively evaluate GaussianGrow on text-guided Gaussian generation from synthetic and even real-scanned point clouds. Project Page: https://weiqi-zhang.github.io/GaussianGrow
4C4D: 4 Camera 4D Gaussian Splatting
Apr 05, 2026This paper tackles the challenge of recovering 4D dynamic scenes from videos captured by as few as four portable cameras. Learning to model scene dynamics for temporally consistent novel-view rendering is a foundational task in computer graphics, where previous works often require dense multi-view captures using camera arrays of dozens or even hundreds of views. We propose \textbf{4C4D}, a novel framework that enables high-fidelity 4D Gaussian Splatting from video captures of extremely sparse cameras. Our key insight lies that the geometric learning under sparse settings is substantially more difficult than modeling appearance. Driven by this observation, we introduce a Neural Decaying Function on Gaussian opacities for enhancing the geometric modeling capability of 4D Gaussians. This design mitigates the inherent imbalance between geometry and appearance modeling in 4DGS by encouraging the 4DGS gradients to focus more on geometric learning. Extensive experiments across sparse-view datasets with varying camera overlaps show that 4C4D achieves superior performance over prior art. Project page at: https://junshengzhou.github.io/4C4D.
3D Gaussian Splatting with Self-Constrained Priors for High Fidelity Surface Reconstruction
Mar 20, 2026Rendering 3D surfaces has been revolutionized within the modeling of radiance fields through either 3DGS or NeRF. Although 3DGS has shown advantages over NeRF in terms of rendering quality or speed, there is still room for improvement in recovering high fidelity surfaces through 3DGS. To resolve this issue, we propose a self-constrained prior to constrain the learning of 3D Gaussians, aiming for more accurate depth rendering. Our self-constrained prior is derived from a TSDF grid that is obtained by fusing the depth maps rendered with current 3D Gaussians. The prior measures a distance field around the estimated surface, offering a band centered at the surface for imposing more specific constraints on 3D Gaussians, such as removing Gaussians outside the band, moving Gaussians closer to the surface, and encouraging larger or smaller opacity in a geometry-aware manner. More importantly, our prior can be regularly updated by the most recent depth images which are usually more accurate and complete. In addition, the prior can also progressively narrow the band to tighten the imposed constraints. We justify our idea and report our superiority over the state-of-the-art methods in evaluations on widely used benchmarks.
MoRe: Motion-aware Feed-forward 4D Reconstruction Transformer
Mar 05, 2026Reconstructing dynamic 4D scenes remains challenging due to the presence of moving objects that corrupt camera pose estimation. Existing optimization methods alleviate this issue with additional supervision, but they are mostly computationally expensive and impractical in real-time applications. To address these limitations, we propose MoRe, a feedforward 4D reconstruction network that efficiently recovers dynamic 3D scenes from monocular videos. Built upon a strong static reconstruction backbone, MoRe employs an attention-forcing strategy to disentangle dynamic motion from static structure. To further enhance robustness, we fine-tune the model on large-scale, diverse datasets encompassing both dynamic and static scenes. Moreover, our grouped causal attention captures temporal dependencies and adapts to varying token lengths across frames, ensuring temporally coherent geometry reconstruction. Extensive experiments on multiple benchmarks demonstrate that MoRe achieves high-quality dynamic reconstructions with exceptional efficiency.
AnchoredDream: Zero-Shot 360° Indoor Scene Generation from a Single View via Geometric Grounding
Jan 26, 2026Single-view indoor scene generation plays a crucial role in a range of real-world applications. However, generating a complete 360° scene from a single image remains a highly ill-posed and challenging problem. Recent approaches have made progress by leveraging diffusion models and depth estimation networks, yet they still struggle to maintain appearance consistency and geometric plausibility under large viewpoint changes, limiting their effectiveness in full-scene generation. To address this, we propose AnchoredDream, a novel zero-shot pipeline that anchors 360° scene generation on high-fidelity geometry via an appearance-geometry mutual boosting mechanism. Given a single-view image, our method first performs appearance-guided geometry generation to construct a reliable 3D scene layout. Then, we progressively generate the complete scene through a series of modules: warp-and-inpaint, warp-and-refine, post-optimization, and a novel Grouting Block, which ensures seamless transitions between the input view and generated regions. Extensive experiments demonstrate that AnchoredDream outperforms existing methods by a large margin in both appearance consistency and geometric plausibility--all in a zero-shot manner. Our results highlight the potential of geometric grounding for high-quality, zero-shot single-view scene generation.
Kling-Avatar: Grounding Multimodal Instructions for Cascaded Long-Duration Avatar Animation Synthesis
Sep 11, 2025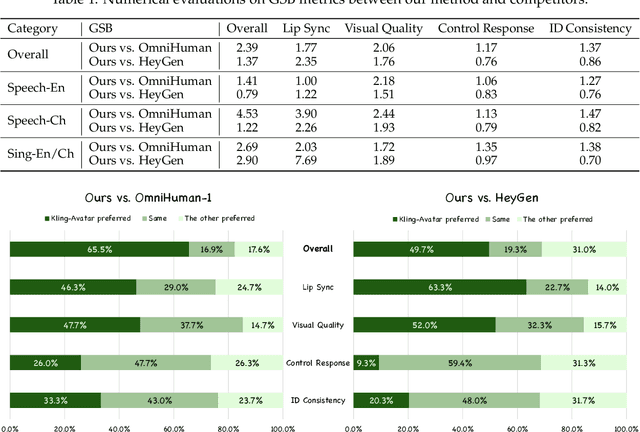
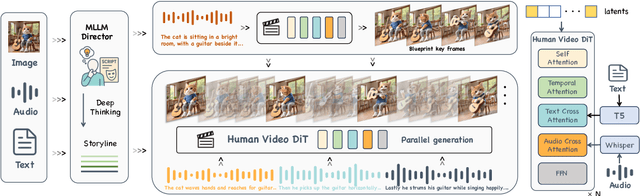


Recent advances in audio-driven avatar video generation have significantly enhanced audio-visual realism. However, existing methods treat instruction conditioning merely as low-level tracking driven by acoustic or visual cues, without modeling the communicative purpose conveyed by the instructions. This limitation compromises their narrative coherence and character expressiveness. To bridge this gap, we introduce Kling-Avatar, a novel cascaded framework that unifies multimodal instruction understanding with photorealistic portrait generation. Our approach adopts a two-stage pipeline. In the first stage, we design a multimodal large language model (MLLM) director that produces a blueprint video conditioned on diverse instruction signals, thereby governing high-level semantics such as character motion and emotions. In the second stage, guided by blueprint keyframes, we generate multiple sub-clips in parallel using a first-last frame strategy. This global-to-local framework preserves fine-grained details while faithfully encoding the high-level intent behind multimodal instructions. Our parallel architecture also enables fast and stable generation of long-duration videos, making it suitable for real-world applications such as digital human livestreaming and vlogging. To comprehensively evaluate our method, we construct a benchmark of 375 curated samples covering diverse instructions and challenging scenarios. Extensive experiments demonstrate that Kling-Avatar is capable of generating vivid, fluent, long-duration videos at up to 1080p and 48 fps, achieving superior performance in lip synchronization accuracy, emotion and dynamic expressiveness, instruction controllability, identity preservation, and cross-domain generalization. These results establish Kling-Avatar as a new benchmark for semantically grounded, high-fidelity audio-driven avatar synthesis.
GAP: Gaussianize Any Point Clouds with Text Guidance
Aug 07, 20253D Gaussian Splatting (3DGS) has demonstrated its advantages in achieving fast and high-quality rendering. As point clouds serve as a widely-used and easily accessible form of 3D representation, bridging the gap between point clouds and Gaussians becomes increasingly important. Recent studies have explored how to convert the colored points into Gaussians, but directly generating Gaussians from colorless 3D point clouds remains an unsolved challenge. In this paper, we propose GAP, a novel approach that gaussianizes raw point clouds into high-fidelity 3D Gaussians with text guidance. Our key idea is to design a multi-view optimization framework that leverages a depth-aware image diffusion model to synthesize consistent appearances across different viewpoints. To ensure geometric accuracy, we introduce a surface-anchoring mechanism that effectively constrains Gaussians to lie on the surfaces of 3D shapes during optimization. Furthermore, GAP incorporates a diffuse-based inpainting strategy that specifically targets at completing hard-to-observe regions. We evaluate GAP on the Point-to-Gaussian generation task across varying complexity levels, from synthetic point clouds to challenging real-world scans, and even large-scale scenes. Project Page: https://weiqi-zhang.github.io/GAP.
Hierarchical Scoring with 3D Gaussian Splatting for Instance Image-Goal Navigation
Jun 09, 2025Instance Image-Goal Navigation (IIN) requires autonomous agents to identify and navigate to a target object or location depicted in a reference image captured from any viewpoint. While recent methods leverage powerful novel view synthesis (NVS) techniques, such as three-dimensional Gaussian splatting (3DGS), they typically rely on randomly sampling multiple viewpoints or trajectories to ensure comprehensive coverage of discriminative visual cues. This approach, however, creates significant redundancy through overlapping image samples and lacks principled view selection, substantially increasing both rendering and comparison overhead. In this paper, we introduce a novel IIN framework with a hierarchical scoring paradigm that estimates optimal viewpoints for target matching. Our approach integrates cross-level semantic scoring, utilizing CLIP-derived relevancy fields to identify regions with high semantic similarity to the target object class, with fine-grained local geometric scoring that performs precise pose estimation within promising regions. Extensive evaluations demonstrate that our method achieves state-of-the-art performance on simulated IIN benchmarks and real-world applicability.
Learning Bijective Surface Parameterization for Inferring Signed Distance Functions from Sparse Point Clouds with Grid Deformation
Mar 31, 2025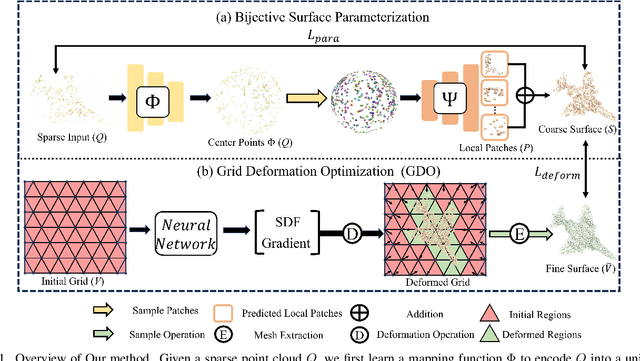
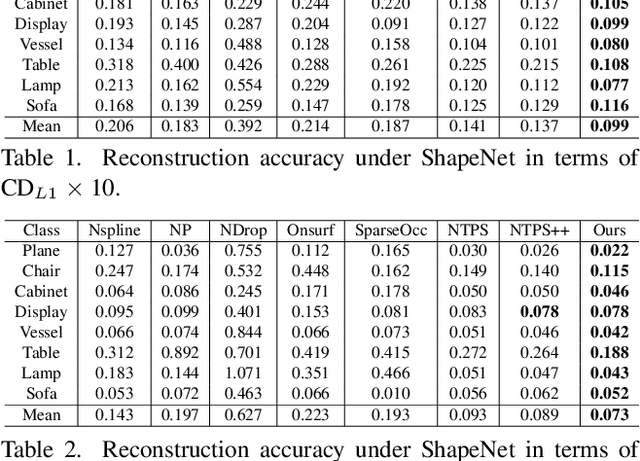
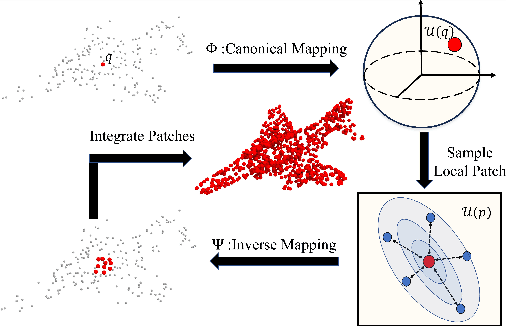
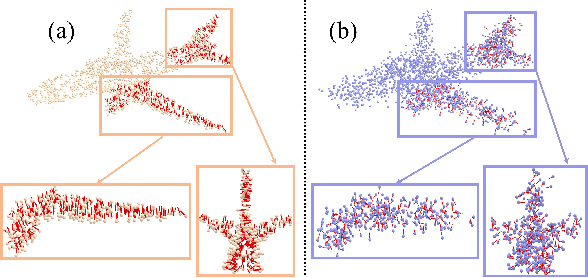
Inferring signed distance functions (SDFs) from sparse point clouds remains a challenge in surface reconstruction. The key lies in the lack of detailed geometric information in sparse point clouds, which is essential for learning a continuous field. To resolve this issue, we present a novel approach that learns a dynamic deformation network to predict SDFs in an end-to-end manner. To parameterize a continuous surface from sparse points, we propose a bijective surface parameterization (BSP) that learns the global shape from local patches. Specifically, we construct a bijective mapping for sparse points from the parametric domain to 3D local patches, integrating patches into the global surface. Meanwhile, we introduce grid deformation optimization (GDO) into the surface approximation to optimize the deformation of grid points and further refine the parametric surfaces. Experimental results on synthetic and real scanned datasets demonstrate that our method significantly outperforms the current state-of-the-art methods. Project page: https://takeshie.github.io/Bijective-SDF
GaussianUDF: Inferring Unsigned Distance Functions through 3D Gaussian Splatting
Mar 25, 2025Reconstructing open surfaces from multi-view images is vital in digitalizing complex objects in daily life. A widely used strategy is to learn unsigned distance functions (UDFs) by checking if their appearance conforms to the image observations through neural rendering. However, it is still hard to learn continuous and implicit UDF representations through 3D Gaussians splatting (3DGS) due to the discrete and explicit scene representation, i.e., 3D Gaussians. To resolve this issue, we propose a novel approach to bridge the gap between 3D Gaussians and UDFs. Our key idea is to overfit thin and flat 2D Gaussian planes on surfaces, and then, leverage the self-supervision and gradient-based inference to supervise unsigned distances in both near and far area to surfaces. To this end, we introduce novel constraints and strategies to constrain the learning of 2D Gaussians to pursue more stable optimization and more reliable self-supervision, addressing the challenges brought by complicated gradient field on or near the zero level set of UDFs. We report numerical and visual comparisons with the state-of-the-art on widely used benchmarks and real data to show our advantages in terms of accuracy, efficiency, completeness, and sharpness of reconstructed open surfaces with boundaries. Project page: https://lisj575.github.io/GaussianUDF/